 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring and Distilling Cross-Modal Information for Image Captioning
Paper and Code

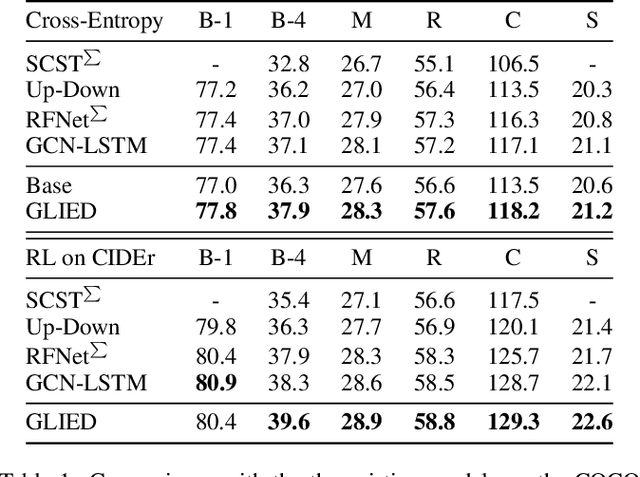
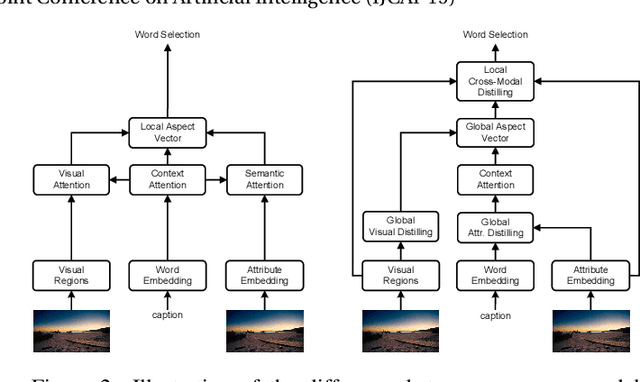
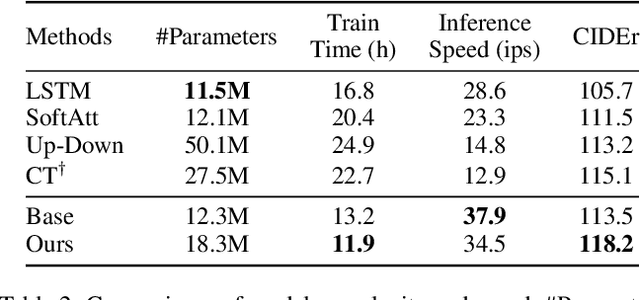
Recently, attention-based encoder-decoder models have been used extensively in image captioning. Yet there is still great difficulty for the current methods to achieve deep image understanding. In this work, we argue that such understanding requires visual attention to correlated image regions and semantic attention to coherent attributes of interest. Based on the Transformer, to perform effective attention, we explore image captioning from a cross-modal perspective and propose the Global-and-Local Information Exploring-and-Distilling approach that explores and distills the source information in vision and language. It globally provides the aspect vector, a spatial and relational representation of images based on caption contexts, through the extraction of salient region groupings and attribute collocations, and locally extracts the fine-grained regions and attributes in reference to the aspect vector for word selection. Our Transformer-based model achieves a CIDEr score of 129.3 in offline COCO evaluation on the COCO testing set with remarkable efficiency in terms of accuracy, speed, and parameter budget.