 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Medical Short Text Classification with Semantic Expansion Using Word-Cluster Embedding
Paper and Code
Dec 05, 2018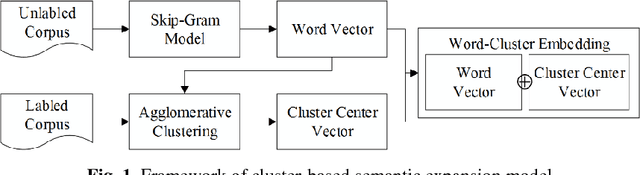
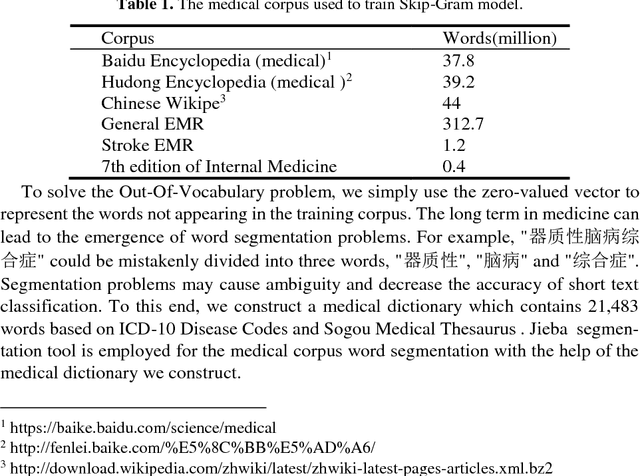
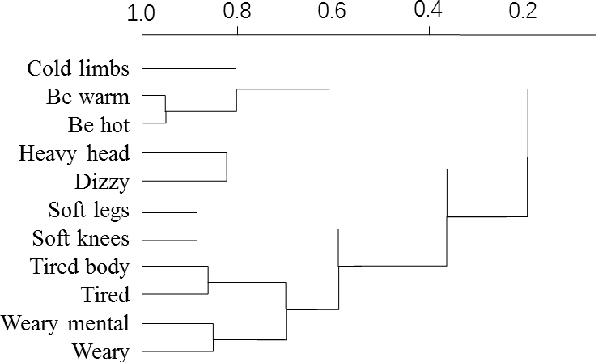
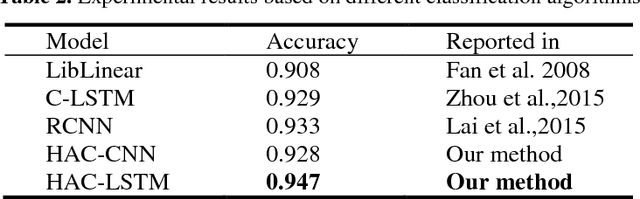
Automatic text classification (TC) research can be used for real-world problems such as the classification of in-patient discharge summaries and medical text reports, which is beneficial to make medical documents more understandable to doctors. However, in electronic medical records (EMR), the texts containing sentences are shorter than that in general domain, which leads to the lack of semantic features and the ambiguity of semantic. To tackle this challenge, we propose to add word-cluster embedding to deep neural network for improving short text classification. Concretely, we first use hierarchical agglomerative clustering to cluster the word vectors in the semantic space. Then we calculate the cluster center vector which represents the implicit topic information of words in the cluster. Finally, we expand word vector with cluster center vector, and implement classifiers using CNN and LSTM respectively. To evaluate the performance of our proposed method, we conduct experiments on public data sets TREC and the medical short sentences data sets which is constructed and released by us. The experimental results demonstrate that our proposed method outperforms state-of-the-art baselines in short sentence classification on both medical domain and general domain.