 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAligning Visual Regions and Textual Concepts: Learning Fine-Grained Image Representations for Image Captioning
Paper and Code

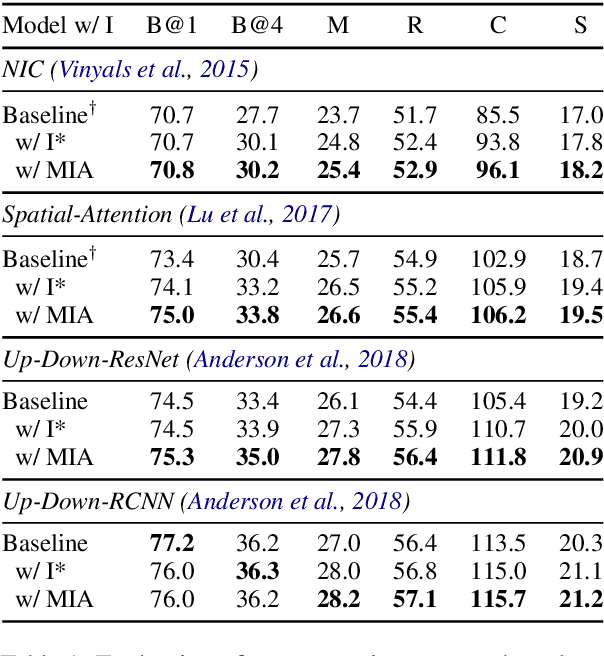
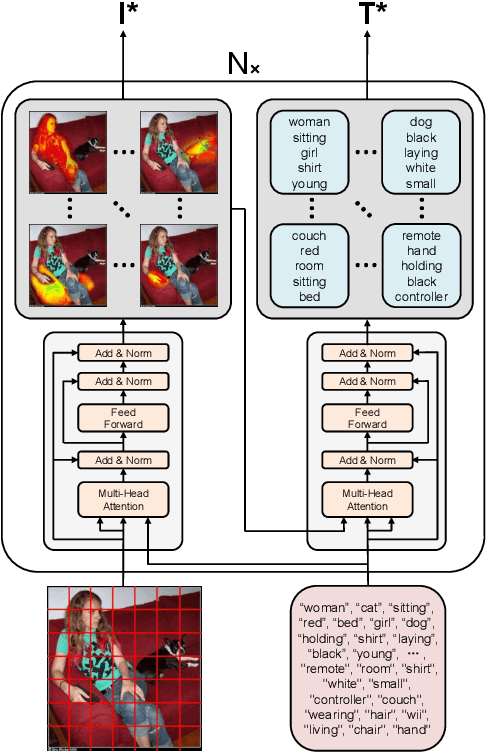
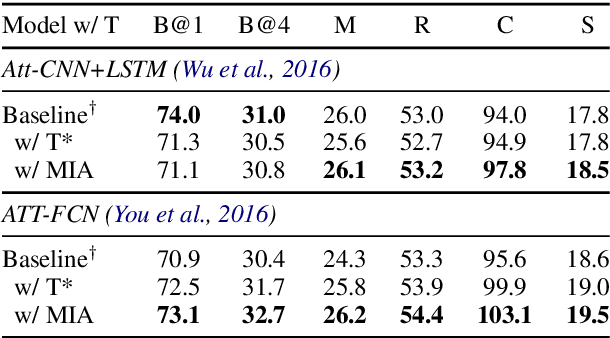
In image-grounded text generation, fine-grained representations of the image are considered to be of paramount importance. Most of the current systems incorporate visual features and textual concepts as a sketch of an image. However, plainly inferred representations are usually undesirable in that they are composed of separate components, the relations of which are elusive. In this work, we aim at representing an image with a set of integrated visual regions and corresponding textual concepts. To this end, we build the Mutual Iterative Attention (MIA) module, which integrates correlated visual features and textual concepts, respectively, by aligning the two modalities. We evaluate the proposed approach on the COCO dataset for image captioning. Extensive experiments show that the refined image representations boost the baseline models by up to 12% in terms of CIDEr, demonstrating that our method is effective and generalizes well to a wide range of models.