 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards In-Depth Root Cause Localization for Microservices with Multi-Agent Recursion-of-Thought
May 14, 2026As modern microservice systems grow increasingly complex due to dynamic interactions and evolving runtime environments, they experience failures with rising frequency. Ensuring system reliability therefore critically depends on accurate root cause localization (RCL). While numerous traditional machine learning and deep learning approaches have been explored for this task, they often suffer from limited interpretability and poor transferability across deployments. More recently, large language model (LLM)-based methods have been proposed to address these issues. However, existing LLM-based approaches still face two fundamental limitations: context explosion, which dilutes critical evidence and degrades localization accuracy, and serial reasoning structures, which hinder deep causal exploration and impair inference efficiency. In this paper, we conduct a comprehensive study of both how human SREs perform root cause localization in practice and why existing LLM-based methods fall short. Motivated by these findings, we introduce RCLAgent, an in-depth root cause localization framework for microservice systems that realizes multi-agent recursion-of-thought with parallel reasoning. RCLAgent decomposes the diagnostic process along the trace graph by assigning each span to a Dedicated Agent and organizing agents recursively and in parallel according to the graph topology, with the final diagnosis obtained by synthesizing the Root-Level Diagnosis Report and the Global Evidence Graph. Extensive experiments on multiple public benchmarks demonstrate that RCLAgent consistently outperforms state-of-the-art methods in both localization accuracy and inference efficiency.
OptProver: Bridging Olympiad and Optimization through Continual Training in Formal Theorem Proving
Apr 28, 2026Recent advances in formal theorem proving have focused on Olympiad-level mathematics, leaving undergraduate domains largely unexplored. Optimization, fundamental to machine learning, operations research, and scientific computing, remains underserved by existing provers. Its reliance on domain-specific formalisms (convexity, optimality conditions, and algorithmic analysis) creates significant distribution shift, making naive domain transfer ineffective. We present OptProver, a trained model that achieves robust transfer from Olympiad to undergraduate optimization. Starting from a strong Olympiad-level prover, our pipeline mitigates distribution shift through two key innovations. First, we employ large-scale optimization-focused data curation via expert iteration. Second, we introduce a specialized preference learning objective that integrates perplexity-weighted optimization with a mechanism to penalize valid but non-progressing proof steps. This not only addresses distribution shifts but also guides the search toward efficient trajectories. To enable rigorous evaluation, we construct a novel benchmark in Lean 4 focused on optimization. On this benchmark, OptProver achieves state-of-the-art Pass@1 and Pass@32 among comparably sized models while maintaining competitive performance on general theorem-proving tasks, demonstrating effective domain transfer without catastrophic forgetting.
Efficient Failure Management for Multi-Agent Systems with Reasoning Trace Representation
Mar 23, 2026Large Language Models (LLM)-based Multi-Agent Systems (MASs) have emerged as a new paradigm in software system design, increasingly demonstrating strong reasoning and collaboration capabilities. As these systems become more complex and autonomous, effective failure management is essential to ensure reliability and availability. However, existing approaches often rely on per-trace reasoning, which leads to low efficiency, and neglect historical failure patterns, limiting diagnostic accuracy. In this paper, we conduct a preliminary empirical study to demonstrate the necessity, potential, and challenges of leveraging historical failure patterns to enhance failure management in MASs. Building on this insight, we propose \textbf{EAGER}, an efficient failure management framework for multi-agent systems based on reasoning trace representation. EAGER employs unsupervised reasoning-scoped contrastive learning to encode both intra-agent reasoning and inter-agent coordination, enabling real-time step-wise failure detection, diagnosis, and reflexive mitigation guided by historical failure knowledge. Preliminary evaluations on three open-source MASs demonstrate the effectiveness of EAGER and highlight promising directions for future research in reliable multi-agent system operations.
RuntimeSlicer: Towards Generalizable Unified Runtime State Representation for Failure Management
Mar 23, 2026Modern software systems operate at unprecedented scale and complexity, where effective failure management is critical yet increasingly challenging. Metrics, traces, and logs provide complementary views of system runtime behavior, but existing failure management approaches typically rely on task-oriented pipelines that tightly couple modality-specific preprocessing, representation learning, and downstream models, resulting in limited generalization across tasks and systems. To fill this gap, we propose RuntimeSlicer, a unified runtime state representation model towards generalizable failure management. RuntimeSlicer pre-trains a task-agnostic representation model that directly encodes metrics, traces, and logs into a single, aligned system-state embedding capturing the holistic runtime condition of the system. To train RuntimeSlicer, we introduce Unified Runtime Contrastive Learning, which integrates heterogeneous training data sources and optimizes complementary objectives for cross-modality alignment and temporal consistency. Building upon the learned system-state embeddings, we further propose State-Aware Task-Oriented Tuning, which performs unsupervised partitioning of runtime states and enables state-conditioned adaptation for downstream tasks. This design allows lightweight task-oriented models to be trained on top of the unified embedding without redesigning modality-specific encoders or preprocessing pipelines. Preliminary experiments on the AIOps 2022 dataset demonstrate the feasibility and effectiveness of RuntimeSlicer for system state modeling and failure management tasks.
M2F: Automated Formalization of Mathematical Literature at Scale
Feb 19, 2026Automated formalization of mathematics enables mechanical verification but remains limited to isolated theorems and short snippets. Scaling to textbooks and research papers is largely unaddressed, as it requires managing cross-file dependencies, resolving imports, and ensuring that entire projects compile end-to-end. We present M2F (Math-to-Formal), the first agentic framework for end-to-end, project-scale autoformalization in Lean. The framework operates in two stages. The statement compilation stage splits the document into atomic blocks, orders them via inferred dependencies, and repairs declaration skeletons until the project compiles, allowing placeholders in proofs. The proof repair stage closes these holes under fixed signatures using goal-conditioned local edits. Throughout both stages, M2F keeps the verifier in the loop, committing edits only when toolchain feedback confirms improvement. In approximately three weeks, M2F converts long-form mathematical sources into a project-scale Lean library of 153,853 lines from 479 pages textbooks on real analysis and convex analysis, fully formalized as Lean declarations with accompanying proofs. This represents textbook-scale formalization at a pace that would typically require months or years of expert effort. On FATE-H, we achieve $96\%$ proof success (vs.\ $80\%$ for a strong baseline). Together, these results demonstrate that practical, large-scale automated formalization of mathematical literature is within reach. The full generated Lean code from our runs is available at https://github.com/optsuite/ReasBook.git.
HyLRA: Hybrid Layer Reuse Attention for Efficient Long-Context Inference
Jan 31, 2026Long-context inference in Large Language Models (LLMs) is bottlenecked by the quadratic computation complexity of attention and the substantial memory footprint of Key-Value (KV) caches. While existing sparse attention mechanisms attempt to mitigate this by exploiting inherent sparsity, they often rely on rigid patterns or aggressive pruning, failing to achieve an optimal balance between efficiency and accuracy. In this paper, we introduce {\bf HyLRA} ({\bf Hy}brid {\bf L}ayer {\bf R}euse {\bf A}ttention), a novel framework driven by layer-wise sparsity profiling. Our empirical analysis uncovers a dual characteristic in attention mechanics: \textit{intra-layer sensitivity}, where specific layers necessitate full attention to prevent feature distortion, and \textit{inter-layer similarity}, where consecutive layers share substantial critical tokens. Based on these observations, HyLRA employs an offline dynamic programming approach to derive an optimal layer-wise policy. This hybrid strategy retains full attention for sensitive layers to ensure robustness, while enabling tolerant layers to bypass quadratic calculations by directly reusing top-$k$ indices from preceding layers. This approach allows LLMs to restrict computation to the most critical tokens, effectively overcoming the quadratic bottleneck of dense attention. Extensive evaluations demonstrate that HyLRA improves inference throughput by 6\%--46\% while maintaining comparable performance (with $<1\%$ accuracy degradation), consistently outperforming state-of-the-art sparse attention methods. HyLRA is open source at \href{https://anonymous.4open.science/r/unified-cache-management-CF80/}{\texttt{/r/unified-cache-management-CF80/}}
A Mathematical Theory of Top-$k$ Sparse Attention via Total Variation Distance
Dec 08, 2025



We develop a unified mathematical framework for certified Top-$k$ attention truncation that quantifies approximation error at both the distribution and output levels. For a single attention distribution $P$ and its Top-$k$ truncation $\hat P$, we show that the total-variation distance coincides with the discarded softmax tail mass and satisfies $\mathrm{TV}(P,\hat P)=1-e^{-\mathrm{KL}(\hat P\Vert P)}$, yielding sharp Top-$k$-specific bounds in place of generic inequalities. From this we derive non-asymptotic deterministic bounds -- from a single boundary gap through multi-gap and blockwise variants -- that control $\mathrm{TV}(P,\hat P)$ using only the ordered logits. Using an exact head-tail decomposition, we prove that the output error factorizes as $\|\mathrm{Attn}(q,K,V)-\mathrm{Attn}_k(q,K,V)\|_2=τ\|μ_{\mathrm{tail}}-μ_{\mathrm{head}}\|_2$ with $τ=\mathrm{TV}(P,\hat P)$, yielding a new head-tail diameter bound $\|\mathrm{Attn}(q,K,V)-\mathrm{Attn}_k(q,K,V)\|_2\leτ\,\mathrm{diam}_{H,T}$ and refinements linking the error to $\mathrm{Var}_P(V)$. Under an i.i.d. Gaussian score model $s_i\sim\mathcal N(μ,σ^2)$ we derive closed-form tail masses and an asymptotic rule for the minimal $k_\varepsilon$ ensuring $\mathrm{TV}(P,\hat P)\le\varepsilon$, namely $k_\varepsilon/n\approxΦ_c(σ+Φ^{-1}(\varepsilon))$. Experiments on bert-base-uncased and synthetic logits confirm the predicted scaling of $k_\varepsilon/n$ and show that certified Top-$k$ can reduce scored keys by 2-4$\times$ on average while meeting the prescribed total-variation budget.
T2I-Copilot: A Training-Free Multi-Agent Text-to-Image System for Enhanced Prompt Interpretation and Interactive Generation
Jul 28, 2025



Text-to-Image (T2I) generative models have revolutionized content creation but remain highly sensitive to prompt phrasing, often requiring users to repeatedly refine prompts multiple times without clear feedback. While techniques such as automatic prompt engineering, controlled text embeddings, denoising, and multi-turn generation mitigate these issues, they offer limited controllability, or often necessitate additional training, restricting the generalization abilities. Thus, we introduce T2I-Copilot, a training-free multi-agent system that leverages collaboration between (Multimodal) Large Language Models to automate prompt phrasing, model selection, and iterative refinement. This approach significantly simplifies prompt engineering while enhancing generation quality and text-image alignment compared to direct generation. Specifically, T2I-Copilot consists of three agents: (1) Input Interpreter, which parses the input prompt, resolves ambiguities, and generates a standardized report; (2) Generation Engine, which selects the appropriate model from different types of T2I models and organizes visual and textual prompts to initiate generation; and (3) Quality Evaluator, which assesses aesthetic quality and text-image alignment, providing scores and feedback for potential regeneration. T2I-Copilot can operate fully autonomously while also supporting human-in-the-loop intervention for fine-grained control. On GenAI-Bench, using open-source generation models, T2I-Copilot achieves a VQA score comparable to commercial models RecraftV3 and Imagen 3, surpasses FLUX1.1-pro by 6.17% at only 16.59% of its cost, and outperforms FLUX.1-dev and SD 3.5 Large by 9.11% and 6.36%. Code will be released at: https://github.com/SHI-Labs/T2I-Copilot.
Efficient Long-Context LLM Inference via KV Cache Clustering
Jun 13, 2025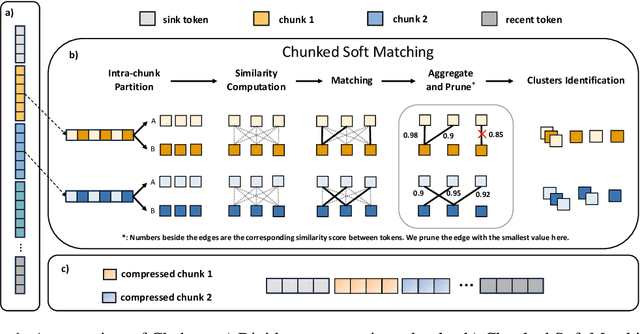
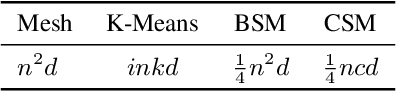
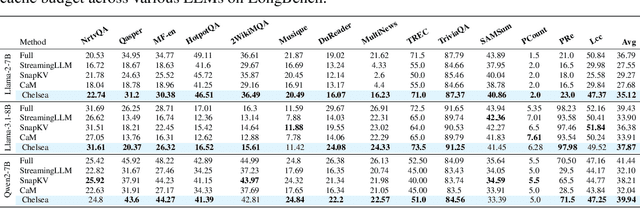
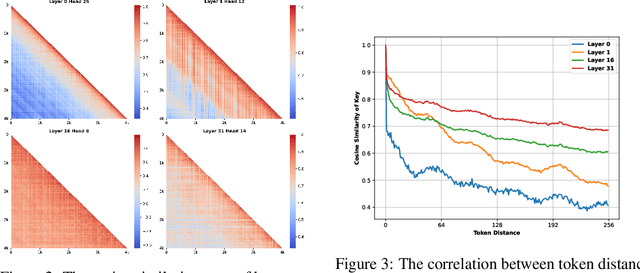
Large language models (LLMs) with extended context windows have become increasingly prevalent for tackling complex tasks. However, the substantial Key-Value (KV) cache required for long-context LLMs poses significant deployment challenges. Existing approaches either discard potentially critical information needed for future generations or offer limited efficiency gains due to high computational overhead. In this paper, we introduce Chelsea, a simple yet effective framework for online KV cache clustering. Our approach is based on the observation that key states exhibit high similarity along the sequence dimension. To enable efficient clustering, we divide the sequence into chunks and propose Chunked Soft Matching, which employs an alternating partition strategy within each chunk and identifies clusters based on similarity. Chelsea then merges the KV cache within each cluster into a single centroid. Additionally, we provide a theoretical analysis of the computational complexity and the optimality of the intra-chunk partitioning strategy. Extensive experiments across various models and long-context benchmarks demonstrate that Chelsea achieves up to 80% reduction in KV cache memory usage while maintaining comparable model performance. Moreover, with minimal computational overhead, Chelsea accelerates the decoding stage of inference by up to 3.19$\times$ and reduces end-to-end latency by up to 2.72$\times$.
AutoSchemaKG: Autonomous Knowledge Graph Construction through Dynamic Schema Induction from Web-Scale Corpora
May 29, 2025
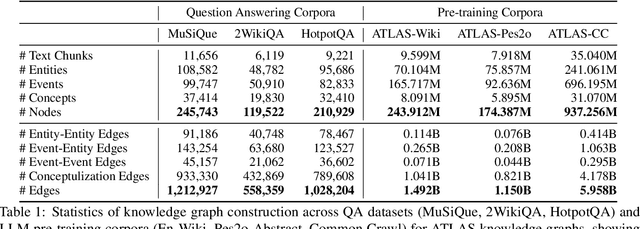
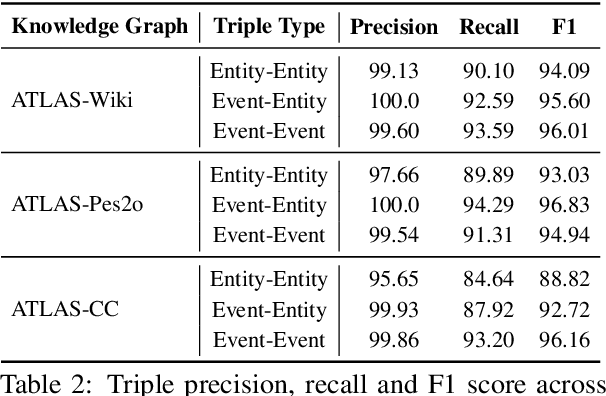

We present AutoSchemaKG, a framework for fully autonomous knowledge graph construction that eliminates the need for predefined schemas. Our system leverages large language models to simultaneously extract knowledge triples and induce comprehensive schemas directly from text, modeling both entities and events while employing conceptualization to organize instances into semantic categories. Processing over 50 million documents, we construct ATLAS (Automated Triple Linking And Schema induction), a family of knowledge graphs with 900+ million nodes and 5.9 billion edges. This approach outperforms state-of-the-art baselines on multi-hop QA tasks and enhances LLM factuality. Notably, our schema induction achieves 95\% semantic alignment with human-crafted schemas with zero manual intervention, demonstrating that billion-scale knowledge graphs with dynamically induced schemas can effectively complement parametric knowledge in large language models.