 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMore Control for Free! Image Synthesis with Semantic Diffusion Guidance
Paper and Code
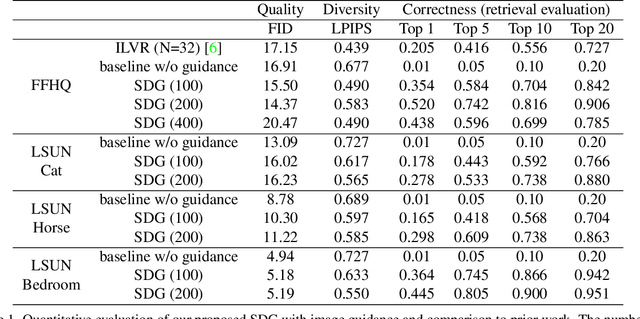
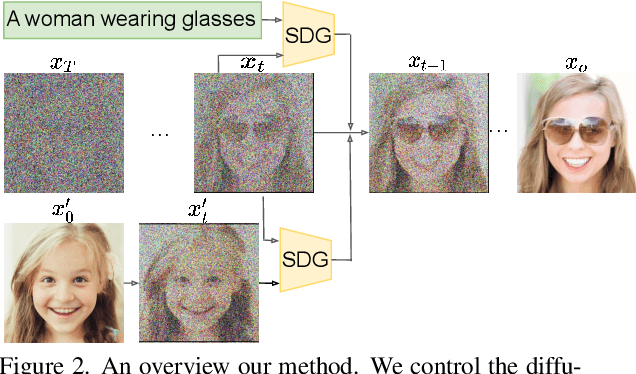
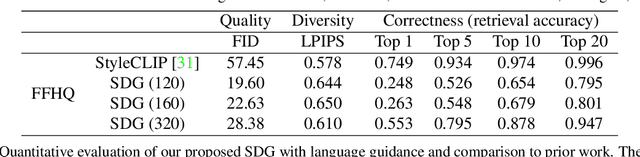

Controllable image synthesis models allow creation of diverse images based on text instructions or guidance from an example image. Recently, denoising diffusion probabilistic models have been shown to generate more realistic imagery than prior methods, and have been successfully demonstrated in unconditional and class-conditional settings. We explore fine-grained, continuous control of this model class, and introduce a novel unified framework for semantic diffusion guidance, which allows either language or image guidance, or both. Guidance is injected into a pretrained unconditional diffusion model using the gradient of image-text or image matching scores. We explore CLIP-based textual guidance as well as both content and style-based image guidance in a unified form. Our text-guided synthesis approach can be applied to datasets without associated text annotations. We conduct experiments on FFHQ and LSUN datasets, and show results on fine-grained text-guided image synthesis, synthesis of images related to a style or content example image, and examples with both textual and image guidance.