 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiffusion Hyperfeatures: Searching Through Time and Space for Semantic Correspondence
May 23, 2023


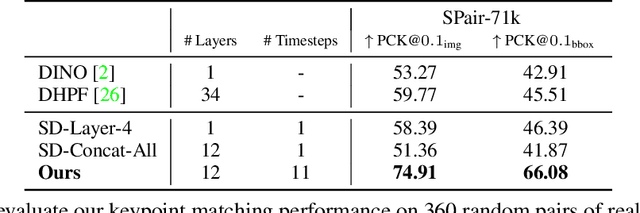
Diffusion models have been shown to be capable of generating high-quality images, suggesting that they could contain meaningful internal representations. Unfortunately, the feature maps that encode a diffusion model's internal information are spread not only over layers of the network, but also over diffusion timesteps, making it challenging to extract useful descriptors. We propose Diffusion Hyperfeatures, a framework for consolidating multi-scale and multi-timestep feature maps into per-pixel feature descriptors that can be used for downstream tasks. These descriptors can be extracted for both synthetic and real images using the generation and inversion processes. We evaluate the utility of our Diffusion Hyperfeatures on the task of semantic keypoint correspondence: our method achieves superior performance on the SPair-71k real image benchmark. We also demonstrate that our method is flexible and transferable: our feature aggregation network trained on the inversion features of real image pairs can be used on the generation features of synthetic image pairs with unseen objects and compositions. Our code is available at \url{https://diffusion-hyperfeatures.github.io}.
Shape-Guided Diffusion with Inside-Outside Attention
Dec 01, 2022
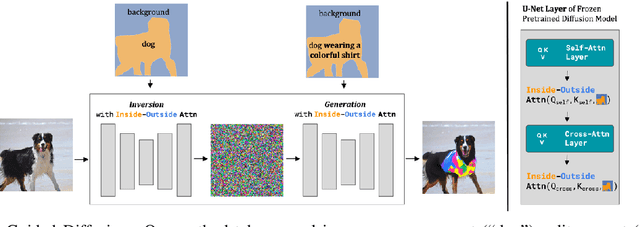

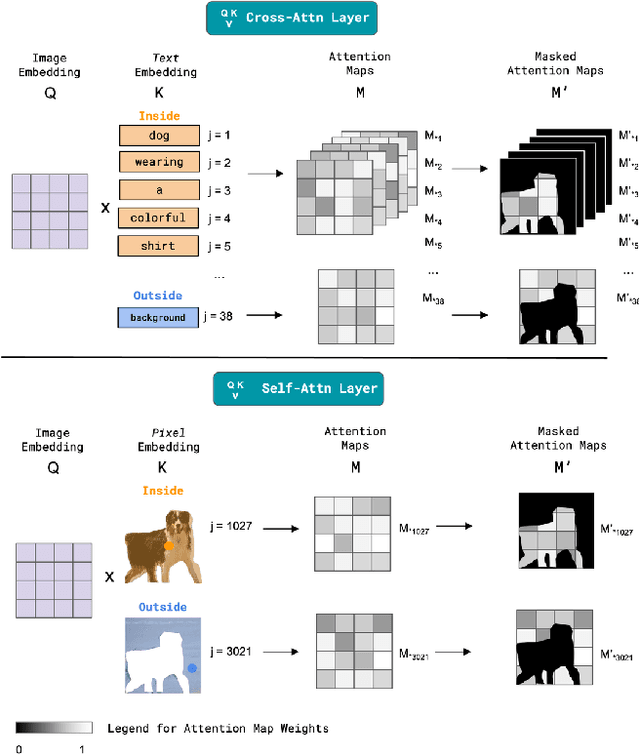
Shape can specify key object constraints, yet existing text-to-image diffusion models ignore this cue and synthesize objects that are incorrectly scaled, cut off, or replaced with background content. We propose a training-free method, Shape-Guided Diffusion, which uses a novel Inside-Outside Attention mechanism to constrain the cross-attention (and self-attention) maps such that prompt tokens (and pixels) referring to the inside of the shape cannot attend outside the shape, and vice versa. To demonstrate the efficacy of our method, we propose a new image editing task where the model must replace an object specified by its mask and a text prompt. We curate a new ShapePrompts benchmark based on MS-COCO and achieve SOTA results in shape faithfulness, text alignment, and realism according to both quantitative metrics and human preferences. Our data and code will be made available at https://shape-guided-diffusion.github.io.
More Control for Free! Image Synthesis with Semantic Diffusion Guidance
Dec 14, 2021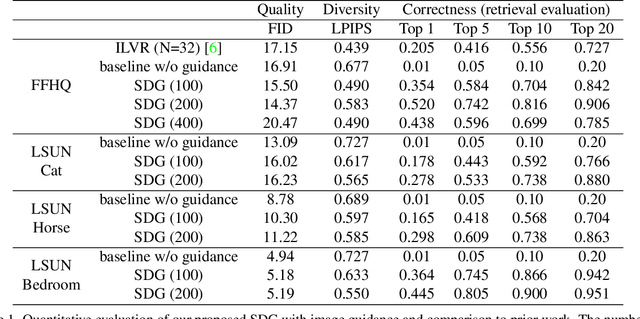
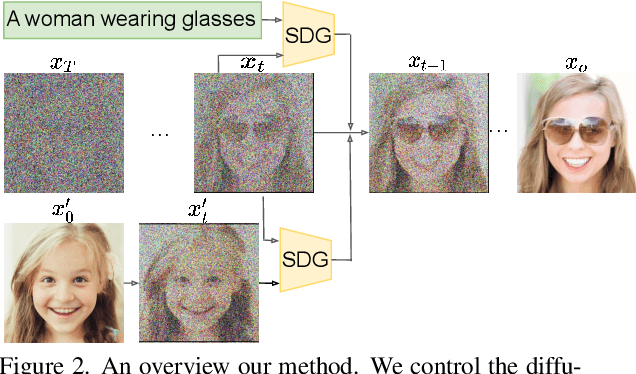
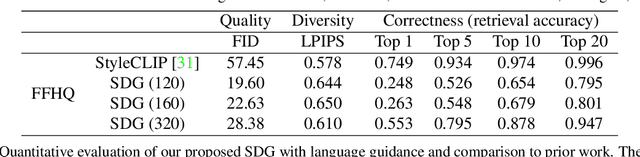

Controllable image synthesis models allow creation of diverse images based on text instructions or guidance from an example image. Recently, denoising diffusion probabilistic models have been shown to generate more realistic imagery than prior methods, and have been successfully demonstrated in unconditional and class-conditional settings. We explore fine-grained, continuous control of this model class, and introduce a novel unified framework for semantic diffusion guidance, which allows either language or image guidance, or both. Guidance is injected into a pretrained unconditional diffusion model using the gradient of image-text or image matching scores. We explore CLIP-based textual guidance as well as both content and style-based image guidance in a unified form. Our text-guided synthesis approach can be applied to datasets without associated text annotations. We conduct experiments on FFHQ and LSUN datasets, and show results on fine-grained text-guided image synthesis, synthesis of images related to a style or content example image, and examples with both textual and image guidance.
Discovering Non-monotonic Autoregressive Orderings with Variational Inference
Oct 27, 2021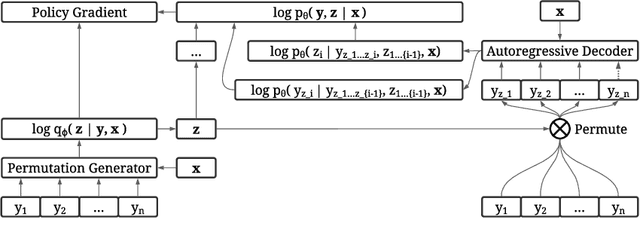

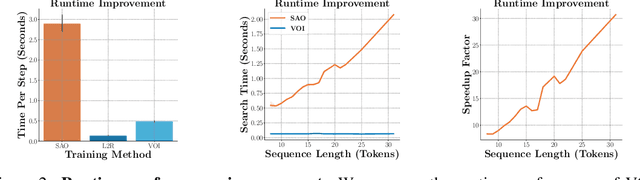

The predominant approach for language modeling is to process sequences from left to right, but this eliminates a source of information: the order by which the sequence was generated. One strategy to recover this information is to decode both the content and ordering of tokens. Existing approaches supervise content and ordering by designing problem-specific loss functions and pre-training with an ordering pre-selected. Other recent works use iterative search to discover problem-specific orderings for training, but suffer from high time complexity and cannot be efficiently parallelized. We address these limitations with an unsupervised parallelizable learner that discovers high-quality generation orders purely from training data -- no domain knowledge required. The learner contains an encoder network and decoder language model that perform variational inference with autoregressive orders (represented as permutation matrices) as latent variables. The corresponding ELBO is not differentiable, so we develop a practical algorithm for end-to-end optimization using policy gradients. We implement the encoder as a Transformer with non-causal attention that outputs permutations in one forward pass. Permutations then serve as target generation orders for training an insertion-based Transformer language model. Empirical results in language modeling tasks demonstrate that our method is context-aware and discovers orderings that are competitive with or even better than fixed orders.
Billion-Scale Pretraining with Vision Transformers for Multi-Task Visual Representations
Aug 12, 2021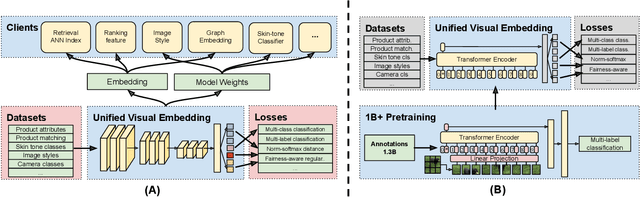


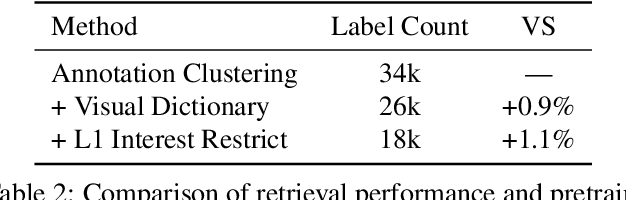
Large-scale pretraining of visual representations has led to state-of-the-art performance on a range of benchmark computer vision tasks, yet the benefits of these techniques at extreme scale in complex production systems has been relatively unexplored. We consider the case of a popular visual discovery product, where these representations are trained with multi-task learning, from use-case specific visual understanding (e.g. skin tone classification) to general representation learning for all visual content (e.g. embeddings for retrieval). In this work, we describe how we (1) generate a dataset with over a billion images via large weakly-supervised pretraining to improve the performance of these visual representations, and (2) leverage Transformers to replace the traditional convolutional backbone, with insights into both system and performance improvements, especially at 1B+ image scale. To support this backbone model, we detail a systematic approach to deriving weakly-supervised image annotations from heterogenous text signals, demonstrating the benefits of clustering techniques to handle the long-tail distribution of image labels. Through a comprehensive study of offline and online evaluation, we show that large-scale Transformer-based pretraining provides significant benefits to industry computer vision applications. The model is deployed in a production visual shopping system, with 36% improvement in top-1 relevance and 23% improvement in click-through volume. We conduct extensive experiments to better understand the empirical relationships between Transformer-based architectures, dataset scale, and the performance of production vision systems.
Toward Transformer-Based Object Detection
Dec 17, 2020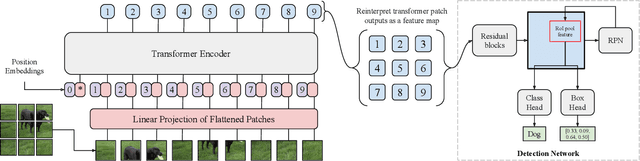
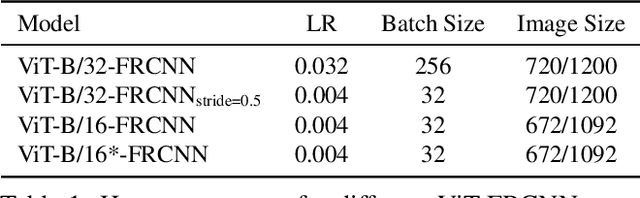
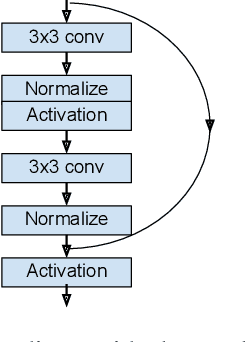
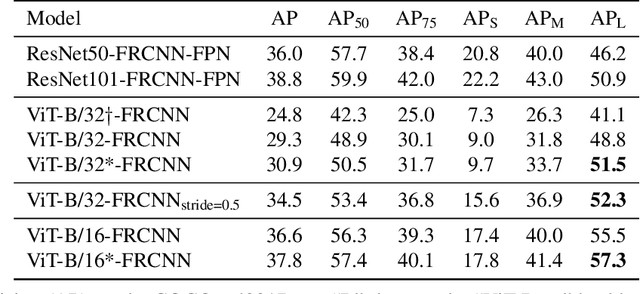
Transformers have become the dominant model in natural language processing, owing to their ability to pretrain on massive amounts of data, then transfer to smaller, more specific tasks via fine-tuning. The Vision Transformer was the first major attempt to apply a pure transformer model directly to images as input, demonstrating that as compared to convolutional networks, transformer-based architectures can achieve competitive results on benchmark classification tasks. However, the computational complexity of the attention operator means that we are limited to low-resolution inputs. For more complex tasks such as detection or segmentation, maintaining a high input resolution is crucial to ensure that models can properly identify and reflect fine details in their output. This naturally raises the question of whether or not transformer-based architectures such as the Vision Transformer are capable of performing tasks other than classification. In this paper, we determine that Vision Transformers can be used as a backbone by a common detection task head to produce competitive COCO results. The model that we propose, ViT-FRCNN, demonstrates several known properties associated with transformers, including large pretraining capacity and fast fine-tuning performance. We also investigate improvements over a standard detection backbone, including superior performance on out-of-domain images, better performance on large objects, and a lessened reliance on non-maximum suppression. We view ViT-FRCNN as an important stepping stone toward a pure-transformer solution of complex vision tasks such as object detection.
Learning a Unified Embedding for Visual Search at Pinterest
Aug 05, 2019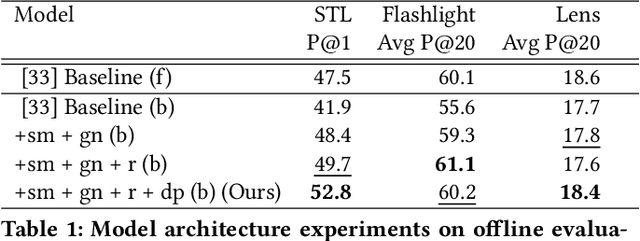

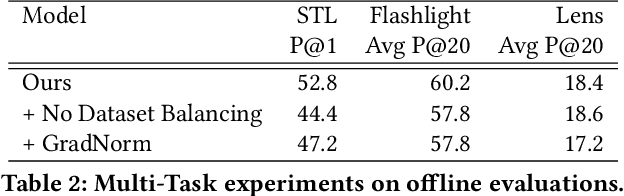
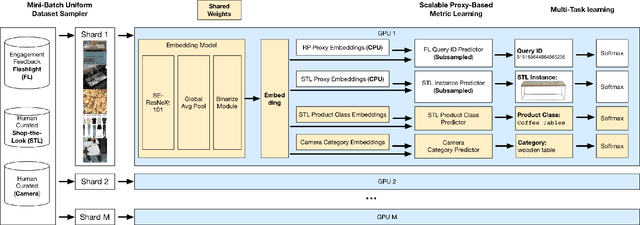
At Pinterest, we utilize image embeddings throughout our search and recommendation systems to help our users navigate through visual content by powering experiences like browsing of related content and searching for exact products for shopping. In this work we describe a multi-task deep metric learning system to learn a single unified image embedding which can be used to power our multiple visual search products. The solution we present not only allows us to train for multiple application objectives in a single deep neural network architecture, but takes advantage of correlated information in the combination of all training data from each application to generate a unified embedding that outperforms all specialized embeddings previously deployed for each product. We discuss the challenges of handling images from different domains such as camera photos, high quality web images, and clean product catalog images. We also detail how to jointly train for multiple product objectives and how to leverage both engagement data and human labeled data. In addition, our trained embeddings can also be binarized for efficient storage and retrieval without compromising precision and recall. Through comprehensive evaluations on offline metrics, user studies, and online A/B experiments, we demonstrate that our proposed unified embedding improves both relevance and engagement of our visual search products for both browsing and searching purposes when compared to existing specialized embeddings. Finally, the deployment of the unified embedding at Pinterest has drastically reduced the operation and engineering cost of maintaining multiple embeddings while improving quality.
Viewpoint Invariant Change Captioning
Jan 08, 2019

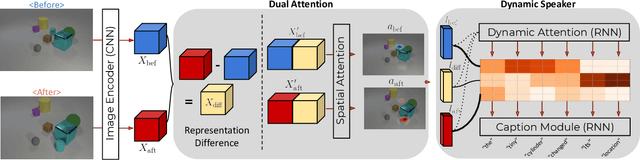

The ability to detect that something has changed in an environment is valuable, but often only if it can be accurately conveyed to a human operator. We introduce Viewpoint Invariant Change Captioning, and develop models which can both localize and describe via natural language complex changes in an environment. Moreover, we distinguish between a change in a viewpoint and an actual scene change (e.g. a change of objects' attributes). To study this new problem, we collect a Viewpoint Invariant Change Captioning Dataset (VICC), building it off the CLEVR dataset and engine. We introduce 5 types of scene changes, including changes in attributes, positions, etc. To tackle this problem, we propose an approach that distinguishes a viewpoint change from an important scene change, localizes the change between "before" and "after" images, and dynamically attends to the relevant visual features when describing the change. We benchmark a number of baselines on our new dataset, and systematically study the different change types. We show the superiority of our proposed approach in terms of change captioning and localization. Finally, we also show that our approach is general and can be applied to real images and language on the recent Spot-the-diff dataset.
Multimodal Explanations: Justifying Decisions and Pointing to the Evidence
Feb 15, 2018
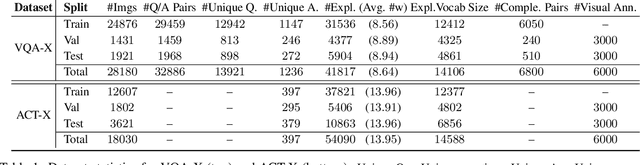


Deep models that are both effective and explainable are desirable in many settings; prior explainable models have been unimodal, offering either image-based visualization of attention weights or text-based generation of post-hoc justifications. We propose a multimodal approach to explanation, and argue that the two modalities provide complementary explanatory strengths. We collect two new datasets to define and evaluate this task, and propose a novel model which can provide joint textual rationale generation and attention visualization. Our datasets define visual and textual justifications of a classification decision for activity recognition tasks (ACT-X) and for visual question answering tasks (VQA-X). We quantitatively show that training with the textual explanations not only yields better textual justification models, but also better localizes the evidence that supports the decision. We also qualitatively show cases where visual explanation is more insightful than textual explanation, and vice versa, supporting our thesis that multimodal explanation models offer significant benefits over unimodal approaches.
Attentive Explanations: Justifying Decisions and Pointing to the Evidence (Extended Abstract)
Nov 17, 2017
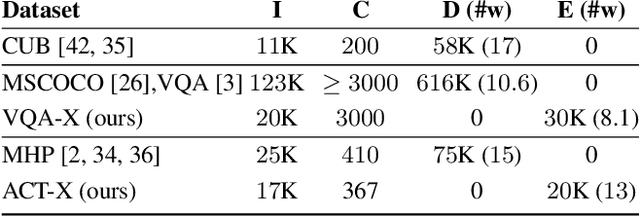


Deep models are the defacto standard in visual decision problems due to their impressive performance on a wide array of visual tasks. On the other hand, their opaqueness has led to a surge of interest in explainable systems. In this work, we emphasize the importance of model explanation in various forms such as visual pointing and textual justification. The lack of data with justification annotations is one of the bottlenecks of generating multimodal explanations. Thus, we propose two large-scale datasets with annotations that visually and textually justify a classification decision for various activities, i.e. ACT-X, and for question answering, i.e. VQA-X. We also introduce a multimodal methodology for generating visual and textual explanations simultaneously. We quantitatively show that training with the textual explanations not only yields better textual justification models, but also models that better localize the evidence that support their decision.