 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBillion-Scale Pretraining with Vision Transformers for Multi-Task Visual Representations
Aug 12, 2021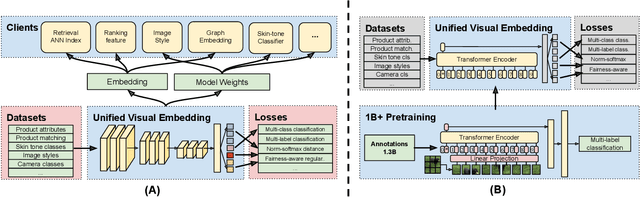


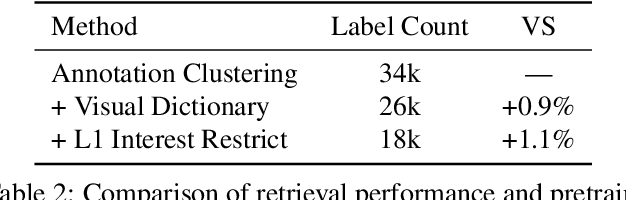
Large-scale pretraining of visual representations has led to state-of-the-art performance on a range of benchmark computer vision tasks, yet the benefits of these techniques at extreme scale in complex production systems has been relatively unexplored. We consider the case of a popular visual discovery product, where these representations are trained with multi-task learning, from use-case specific visual understanding (e.g. skin tone classification) to general representation learning for all visual content (e.g. embeddings for retrieval). In this work, we describe how we (1) generate a dataset with over a billion images via large weakly-supervised pretraining to improve the performance of these visual representations, and (2) leverage Transformers to replace the traditional convolutional backbone, with insights into both system and performance improvements, especially at 1B+ image scale. To support this backbone model, we detail a systematic approach to deriving weakly-supervised image annotations from heterogenous text signals, demonstrating the benefits of clustering techniques to handle the long-tail distribution of image labels. Through a comprehensive study of offline and online evaluation, we show that large-scale Transformer-based pretraining provides significant benefits to industry computer vision applications. The model is deployed in a production visual shopping system, with 36% improvement in top-1 relevance and 23% improvement in click-through volume. We conduct extensive experiments to better understand the empirical relationships between Transformer-based architectures, dataset scale, and the performance of production vision systems.
Toward Transformer-Based Object Detection
Dec 17, 2020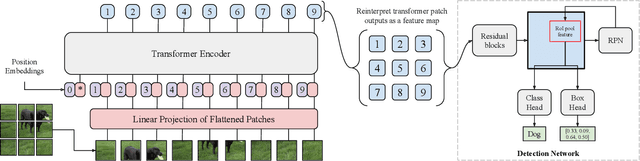
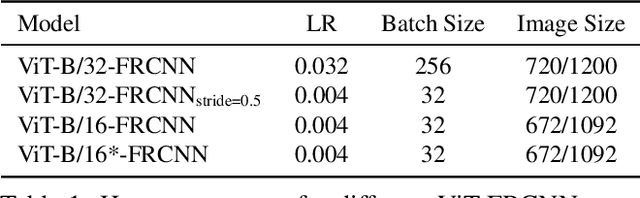
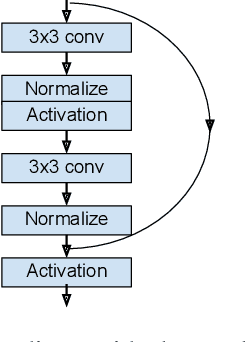
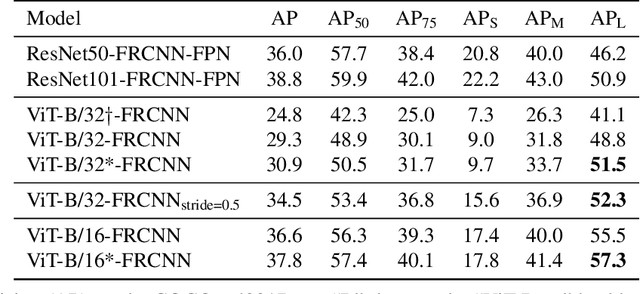
Transformers have become the dominant model in natural language processing, owing to their ability to pretrain on massive amounts of data, then transfer to smaller, more specific tasks via fine-tuning. The Vision Transformer was the first major attempt to apply a pure transformer model directly to images as input, demonstrating that as compared to convolutional networks, transformer-based architectures can achieve competitive results on benchmark classification tasks. However, the computational complexity of the attention operator means that we are limited to low-resolution inputs. For more complex tasks such as detection or segmentation, maintaining a high input resolution is crucial to ensure that models can properly identify and reflect fine details in their output. This naturally raises the question of whether or not transformer-based architectures such as the Vision Transformer are capable of performing tasks other than classification. In this paper, we determine that Vision Transformers can be used as a backbone by a common detection task head to produce competitive COCO results. The model that we propose, ViT-FRCNN, demonstrates several known properties associated with transformers, including large pretraining capacity and fast fine-tuning performance. We also investigate improvements over a standard detection backbone, including superior performance on out-of-domain images, better performance on large objects, and a lessened reliance on non-maximum suppression. We view ViT-FRCNN as an important stepping stone toward a pure-transformer solution of complex vision tasks such as object detection.
Bootstrapping Complete The Look at Pinterest
Jun 29, 2020
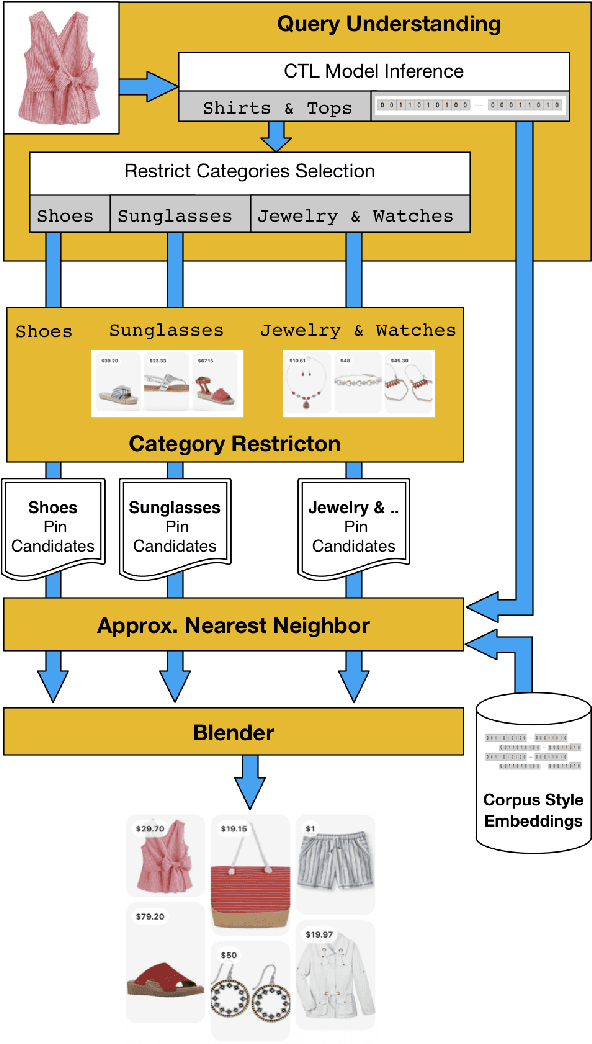
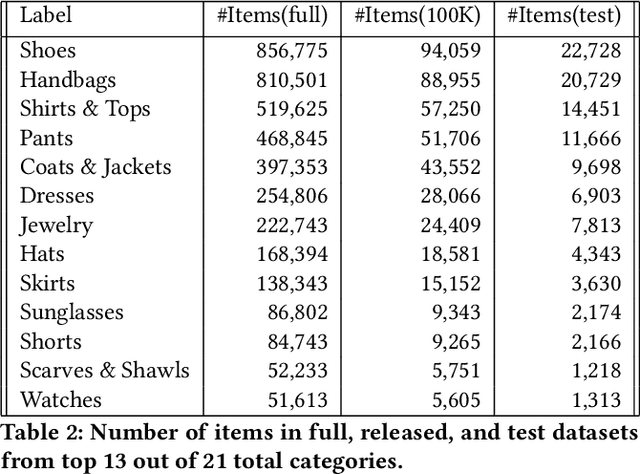
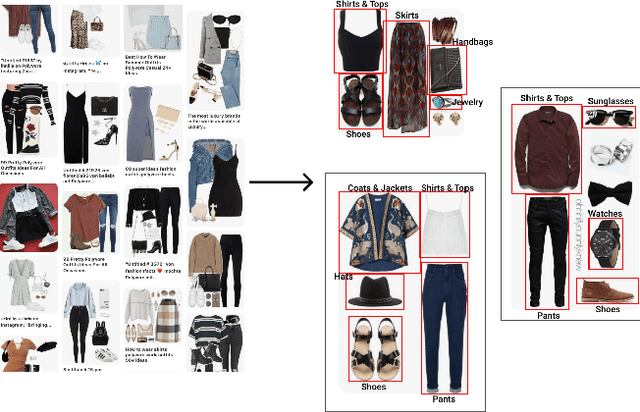
Putting together an ideal outfit is a process that involves creativity and style intuition. This makes it a particularly difficult task to automate. Existing styling products generally involve human specialists and a highly curated set of fashion items. In this paper, we will describe how we bootstrapped the Complete The Look (CTL) system at Pinterest. This is a technology that aims to learn the subjective task of "style compatibility" in order to recommend complementary items that complete an outfit. In particular, we want to show recommendations from other categories that are compatible with an item of interest. For example, what are some heels that go well with this cocktail dress? We will introduce our outfit dataset of over 1 million outfits and 4 million objects, a subset of which we will make available to the research community, and describe the pipeline used to obtain and refresh this dataset. Furthermore, we will describe how we evaluate this subjective task and compare model performance across multiple training methods. Lastly, we will share our lessons going from experimentation to working prototype, and how to mitigate failure modes in the production environment. Our work represents one of the first examples of an industrial-scale solution for compatibility-based fashion recommendation.