 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning a Generative Meta-Model of LLM Activations
Feb 06, 2026Existing approaches for analyzing neural network activations, such as PCA and sparse autoencoders, rely on strong structural assumptions. Generative models offer an alternative: they can uncover structure without such assumptions and act as priors that improve intervention fidelity. We explore this direction by training diffusion models on one billion residual stream activations, creating "meta-models" that learn the distribution of a network's internal states. We find that diffusion loss decreases smoothly with compute and reliably predicts downstream utility. In particular, applying the meta-model's learned prior to steering interventions improves fluency, with larger gains as loss decreases. Moreover, the meta-model's neurons increasingly isolate concepts into individual units, with sparse probing scores that scale as loss decreases. These results suggest generative meta-models offer a scalable path toward interpretability without restrictive structural assumptions. Project page: https://generative-latent-prior.github.io.
Task Vectors are Cross-Modal
Oct 29, 2024



We investigate the internal representations of vision-and-language models (VLMs) and how they encode task representations. We consider tasks specified through examples or instructions, using either text or image inputs. Surprisingly, we find that conceptually similar tasks are mapped to similar task vector representations, regardless of how they are specified. Our findings suggest that to output answers, tokens in VLMs undergo three distinct phases: input, task, and answer, a process which is consistent across different modalities and specifications. The task vectors we identify in VLMs are general enough to be derived in one modality (e.g., text) and transferred to another (e.g., image). Additionally, we find that ensembling exemplar and instruction based task vectors produce better task representations. Taken together, these insights shed light on the underlying mechanisms of VLMs, particularly their ability to represent tasks in a shared manner across different modalities and task specifications. Project page: https://task-vectors-are-cross-modal.github.io.
Readout Guidance: Learning Control from Diffusion Features
Dec 04, 2023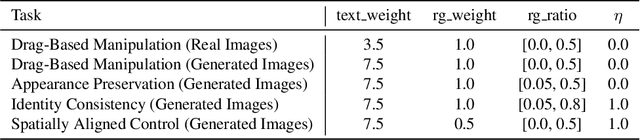

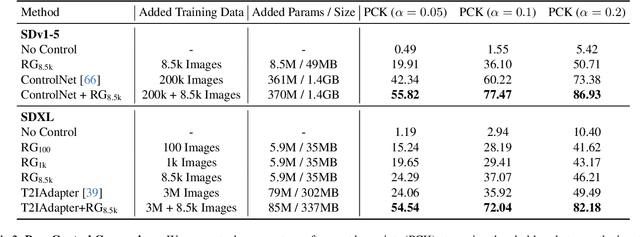
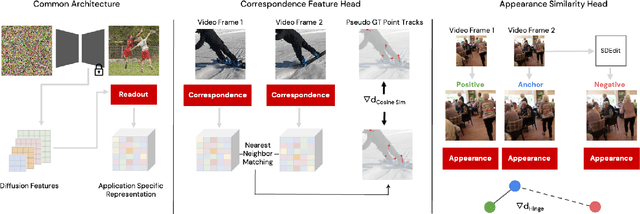
We present Readout Guidance, a method for controlling text-to-image diffusion models with learned signals. Readout Guidance uses readout heads, lightweight networks trained to extract signals from the features of a pre-trained, frozen diffusion model at every timestep. These readouts can encode single-image properties, such as pose, depth, and edges; or higher-order properties that relate multiple images, such as correspondence and appearance similarity. Furthermore, by comparing the readout estimates to a user-defined target, and back-propagating the gradient through the readout head, these estimates can be used to guide the sampling process. Compared to prior methods for conditional generation, Readout Guidance requires significantly fewer added parameters and training samples, and offers a convenient and simple recipe for reproducing different forms of conditional control under a single framework, with a single architecture and sampling procedure. We showcase these benefits in the applications of drag-based manipulation, identity-consistent generation, and spatially aligned control. Project page: https://readout-guidance.github.io.
Diffusion Hyperfeatures: Searching Through Time and Space for Semantic Correspondence
May 23, 2023


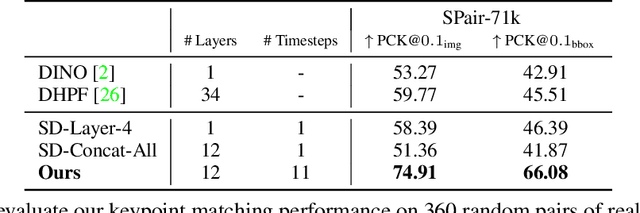
Diffusion models have been shown to be capable of generating high-quality images, suggesting that they could contain meaningful internal representations. Unfortunately, the feature maps that encode a diffusion model's internal information are spread not only over layers of the network, but also over diffusion timesteps, making it challenging to extract useful descriptors. We propose Diffusion Hyperfeatures, a framework for consolidating multi-scale and multi-timestep feature maps into per-pixel feature descriptors that can be used for downstream tasks. These descriptors can be extracted for both synthetic and real images using the generation and inversion processes. We evaluate the utility of our Diffusion Hyperfeatures on the task of semantic keypoint correspondence: our method achieves superior performance on the SPair-71k real image benchmark. We also demonstrate that our method is flexible and transferable: our feature aggregation network trained on the inversion features of real image pairs can be used on the generation features of synthetic image pairs with unseen objects and compositions. Our code is available at \url{https://diffusion-hyperfeatures.github.io}.
Shape-Guided Diffusion with Inside-Outside Attention
Dec 01, 2022
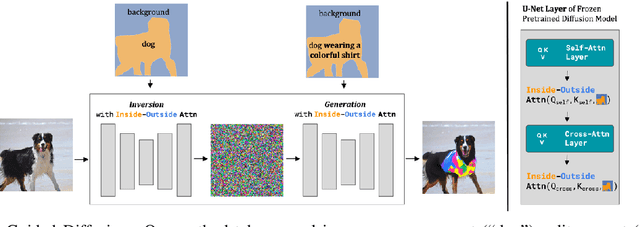

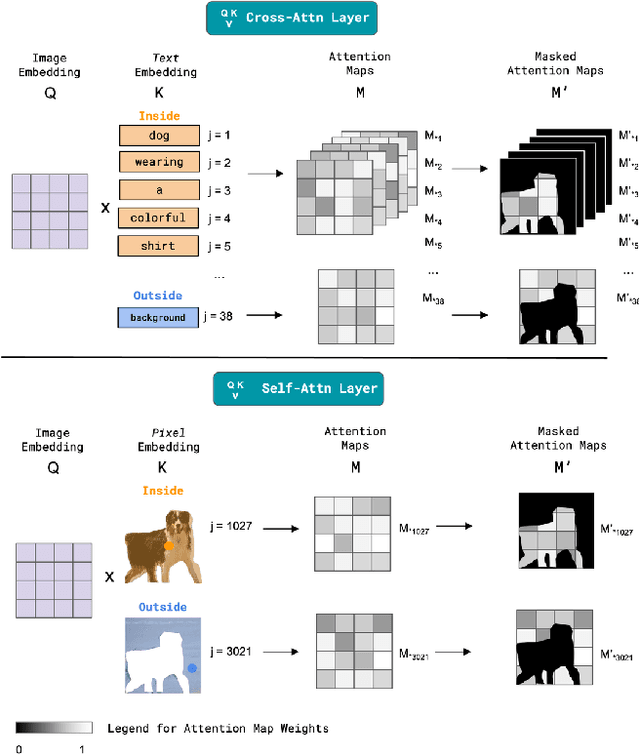
Shape can specify key object constraints, yet existing text-to-image diffusion models ignore this cue and synthesize objects that are incorrectly scaled, cut off, or replaced with background content. We propose a training-free method, Shape-Guided Diffusion, which uses a novel Inside-Outside Attention mechanism to constrain the cross-attention (and self-attention) maps such that prompt tokens (and pixels) referring to the inside of the shape cannot attend outside the shape, and vice versa. To demonstrate the efficacy of our method, we propose a new image editing task where the model must replace an object specified by its mask and a text prompt. We curate a new ShapePrompts benchmark based on MS-COCO and achieve SOTA results in shape faithfulness, text alignment, and realism according to both quantitative metrics and human preferences. Our data and code will be made available at https://shape-guided-diffusion.github.io.
Focus! Relevant and Sufficient Context Selection for News Image Captioning
Dec 01, 2022



News Image Captioning requires describing an image by leveraging additional context from a news article. Previous works only coarsely leverage the article to extract the necessary context, which makes it challenging for models to identify relevant events and named entities. In our paper, we first demonstrate that by combining more fine-grained context that captures the key named entities (obtained via an oracle) and the global context that summarizes the news, we can dramatically improve the model's ability to generate accurate news captions. This begs the question, how to automatically extract such key entities from an image? We propose to use the pre-trained vision and language retrieval model CLIP to localize the visually grounded entities in the news article and then capture the non-visual entities via an open relation extraction model. Our experiments demonstrate that by simply selecting a better context from the article, we can significantly improve the performance of existing models and achieve new state-of-the-art performance on multiple benchmarks.
G^3: Geolocation via Guidebook Grounding
Nov 28, 2022



We demonstrate how language can improve geolocation: the task of predicting the location where an image was taken. Here we study explicit knowledge from human-written guidebooks that describe the salient and class-discriminative visual features humans use for geolocation. We propose the task of Geolocation via Guidebook Grounding that uses a dataset of StreetView images from a diverse set of locations and an associated textual guidebook for GeoGuessr, a popular interactive geolocation game. Our approach predicts a country for each image by attending over the clues automatically extracted from the guidebook. Supervising attention with country-level pseudo labels achieves the best performance. Our approach substantially outperforms a state-of-the-art image-only geolocation method, with an improvement of over 5% in Top-1 accuracy. Our dataset and code can be found at https://github.com/g-luo/geolocation_via_guidebook_grounding.
Twitter-COMMs: Detecting Climate, COVID, and Military Multimodal Misinformation
Dec 16, 2021



Detecting out-of-context media, such as "miscaptioned" images on Twitter, often requires detecting inconsistencies between the two modalities. This paper describes our approach to the Image-Text Inconsistency Detection challenge of the DARPA Semantic Forensics (SemaFor) Program. First, we collect Twitter-COMMs, a large-scale multimodal dataset with 884k tweets relevant to the topics of Climate Change, COVID-19, and Military Vehicles. We train our approach, based on the state-of-the-art CLIP model, leveraging automatically generated random and hard negatives. Our method is then tested on a hidden human-generated evaluation set. We achieve the best result on the program leaderboard, with 11% detection improvement in a high precision regime over a zero-shot CLIP baseline.
NewsCLIPpings: Automatic Generation of Out-of-Context Multimodal Media
Apr 13, 2021
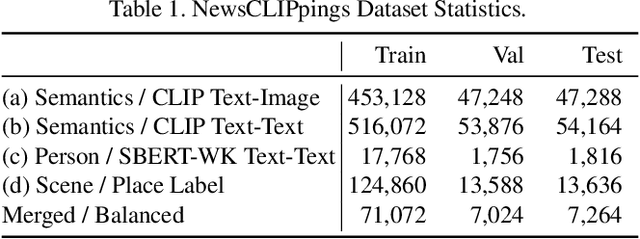
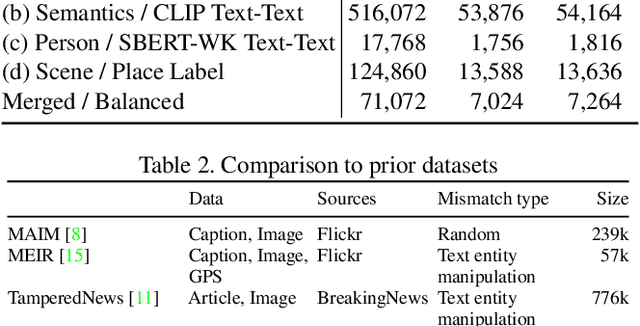

The threat of online misinformation is hard to overestimate, with adversaries relying on a range of tools, from cheap fakes to sophisticated deep fakes. We are motivated by a threat scenario where an image is being used out of context to support a certain narrative expressed in a caption. While some prior datasets for detecting image-text inconsistency can be solved with blind models due to linguistic cues introduced by text manipulation, we propose a dataset where both image and text are unmanipulated but mismatched. We introduce several strategies for automatic retrieval of suitable images for the given captions, capturing cases with related semantics but inconsistent entities as well as matching entities but inconsistent semantic context. Our large-scale automatically generated NewsCLIPpings Dataset requires models to jointly analyze both modalities and to reason about entity mismatch as well as semantic mismatch between text and images in news media.