 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNewsCLIPpings: Automatic Generation of Out-of-Context Multimodal Media
Paper and Code

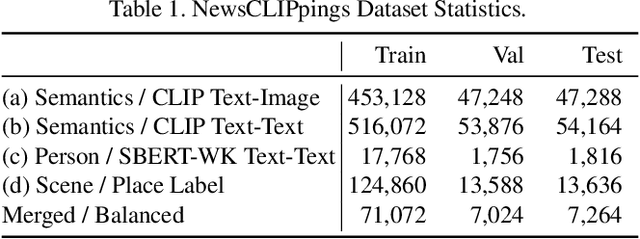
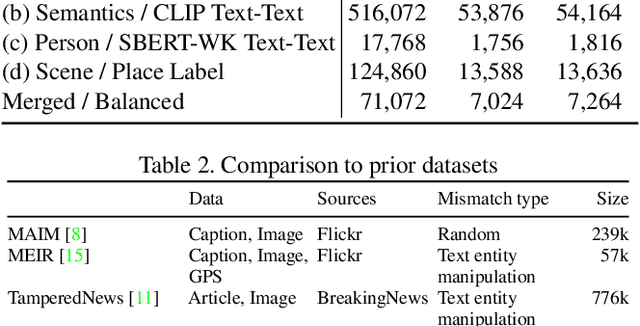

The threat of online misinformation is hard to overestimate, with adversaries relying on a range of tools, from cheap fakes to sophisticated deep fakes. We are motivated by a threat scenario where an image is being used out of context to support a certain narrative expressed in a caption. While some prior datasets for detecting image-text inconsistency can be solved with blind models due to linguistic cues introduced by text manipulation, we propose a dataset where both image and text are unmanipulated but mismatched. We introduce several strategies for automatic retrieval of suitable images for the given captions, capturing cases with related semantics but inconsistent entities as well as matching entities but inconsistent semantic context. Our large-scale automatically generated NewsCLIPpings Dataset requires models to jointly analyze both modalities and to reason about entity mismatch as well as semantic mismatch between text and images in news media.