 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHyLRA: Hybrid Layer Reuse Attention for Efficient Long-Context Inference
Jan 31, 2026Long-context inference in Large Language Models (LLMs) is bottlenecked by the quadratic computation complexity of attention and the substantial memory footprint of Key-Value (KV) caches. While existing sparse attention mechanisms attempt to mitigate this by exploiting inherent sparsity, they often rely on rigid patterns or aggressive pruning, failing to achieve an optimal balance between efficiency and accuracy. In this paper, we introduce {\bf HyLRA} ({\bf Hy}brid {\bf L}ayer {\bf R}euse {\bf A}ttention), a novel framework driven by layer-wise sparsity profiling. Our empirical analysis uncovers a dual characteristic in attention mechanics: \textit{intra-layer sensitivity}, where specific layers necessitate full attention to prevent feature distortion, and \textit{inter-layer similarity}, where consecutive layers share substantial critical tokens. Based on these observations, HyLRA employs an offline dynamic programming approach to derive an optimal layer-wise policy. This hybrid strategy retains full attention for sensitive layers to ensure robustness, while enabling tolerant layers to bypass quadratic calculations by directly reusing top-$k$ indices from preceding layers. This approach allows LLMs to restrict computation to the most critical tokens, effectively overcoming the quadratic bottleneck of dense attention. Extensive evaluations demonstrate that HyLRA improves inference throughput by 6\%--46\% while maintaining comparable performance (with $<1\%$ accuracy degradation), consistently outperforming state-of-the-art sparse attention methods. HyLRA is open source at \href{https://anonymous.4open.science/r/unified-cache-management-CF80/}{\texttt{/r/unified-cache-management-CF80/}}
A Mathematical Theory of Top-$k$ Sparse Attention via Total Variation Distance
Dec 08, 2025



We develop a unified mathematical framework for certified Top-$k$ attention truncation that quantifies approximation error at both the distribution and output levels. For a single attention distribution $P$ and its Top-$k$ truncation $\hat P$, we show that the total-variation distance coincides with the discarded softmax tail mass and satisfies $\mathrm{TV}(P,\hat P)=1-e^{-\mathrm{KL}(\hat P\Vert P)}$, yielding sharp Top-$k$-specific bounds in place of generic inequalities. From this we derive non-asymptotic deterministic bounds -- from a single boundary gap through multi-gap and blockwise variants -- that control $\mathrm{TV}(P,\hat P)$ using only the ordered logits. Using an exact head-tail decomposition, we prove that the output error factorizes as $\|\mathrm{Attn}(q,K,V)-\mathrm{Attn}_k(q,K,V)\|_2=τ\|μ_{\mathrm{tail}}-μ_{\mathrm{head}}\|_2$ with $τ=\mathrm{TV}(P,\hat P)$, yielding a new head-tail diameter bound $\|\mathrm{Attn}(q,K,V)-\mathrm{Attn}_k(q,K,V)\|_2\leτ\,\mathrm{diam}_{H,T}$ and refinements linking the error to $\mathrm{Var}_P(V)$. Under an i.i.d. Gaussian score model $s_i\sim\mathcal N(μ,σ^2)$ we derive closed-form tail masses and an asymptotic rule for the minimal $k_\varepsilon$ ensuring $\mathrm{TV}(P,\hat P)\le\varepsilon$, namely $k_\varepsilon/n\approxΦ_c(σ+Φ^{-1}(\varepsilon))$. Experiments on bert-base-uncased and synthetic logits confirm the predicted scaling of $k_\varepsilon/n$ and show that certified Top-$k$ can reduce scored keys by 2-4$\times$ on average while meeting the prescribed total-variation budget.
Efficient Long-Context LLM Inference via KV Cache Clustering
Jun 13, 2025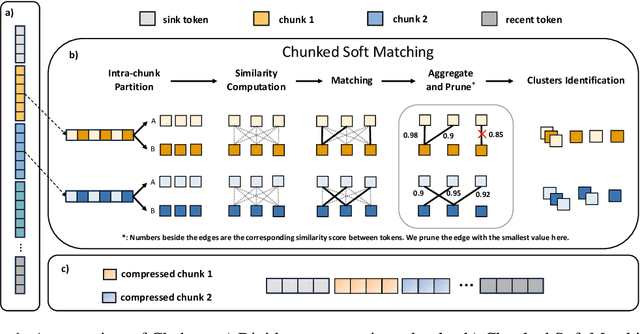
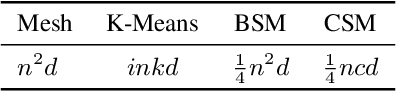
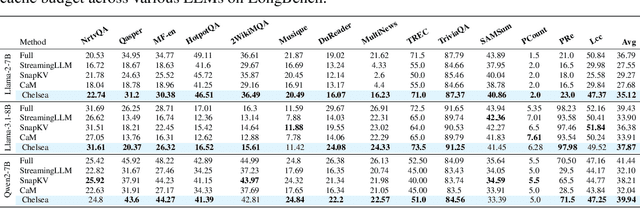
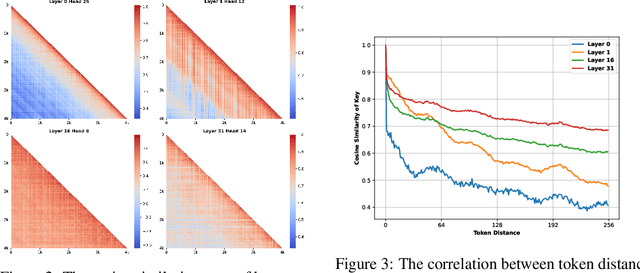
Large language models (LLMs) with extended context windows have become increasingly prevalent for tackling complex tasks. However, the substantial Key-Value (KV) cache required for long-context LLMs poses significant deployment challenges. Existing approaches either discard potentially critical information needed for future generations or offer limited efficiency gains due to high computational overhead. In this paper, we introduce Chelsea, a simple yet effective framework for online KV cache clustering. Our approach is based on the observation that key states exhibit high similarity along the sequence dimension. To enable efficient clustering, we divide the sequence into chunks and propose Chunked Soft Matching, which employs an alternating partition strategy within each chunk and identifies clusters based on similarity. Chelsea then merges the KV cache within each cluster into a single centroid. Additionally, we provide a theoretical analysis of the computational complexity and the optimality of the intra-chunk partitioning strategy. Extensive experiments across various models and long-context benchmarks demonstrate that Chelsea achieves up to 80% reduction in KV cache memory usage while maintaining comparable model performance. Moreover, with minimal computational overhead, Chelsea accelerates the decoding stage of inference by up to 3.19$\times$ and reduces end-to-end latency by up to 2.72$\times$.
AutoSchemaKG: Autonomous Knowledge Graph Construction through Dynamic Schema Induction from Web-Scale Corpora
May 29, 2025
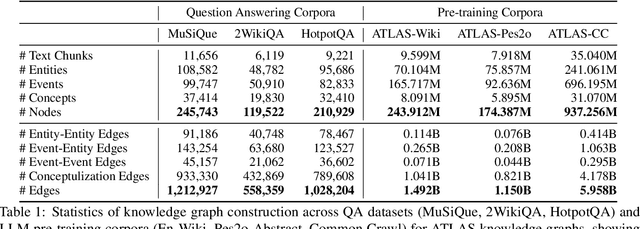
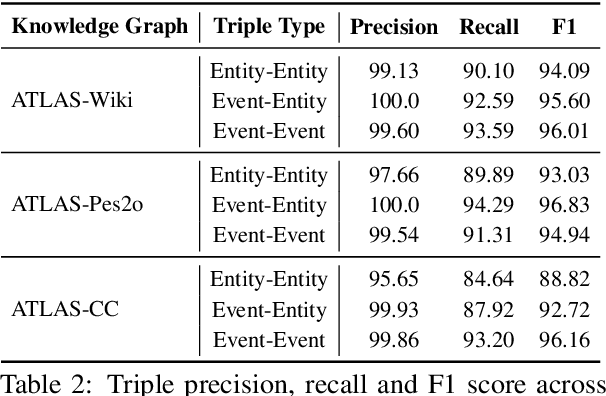

We present AutoSchemaKG, a framework for fully autonomous knowledge graph construction that eliminates the need for predefined schemas. Our system leverages large language models to simultaneously extract knowledge triples and induce comprehensive schemas directly from text, modeling both entities and events while employing conceptualization to organize instances into semantic categories. Processing over 50 million documents, we construct ATLAS (Automated Triple Linking And Schema induction), a family of knowledge graphs with 900+ million nodes and 5.9 billion edges. This approach outperforms state-of-the-art baselines on multi-hop QA tasks and enhances LLM factuality. Notably, our schema induction achieves 95\% semantic alignment with human-crafted schemas with zero manual intervention, demonstrating that billion-scale knowledge graphs with dynamically induced schemas can effectively complement parametric knowledge in large language models.
XL3M: A Training-free Framework for LLM Length Extension Based on Segment-wise Inference
May 28, 2024



Length generalization failure problem, namely the large language model (LLM) fails to generalize to texts longer than its maximum training length, greatly restricts the application of LLM in the scenarios with streaming long inputs. To address this problem, the existing methods either require substantial costs or introduce precision loss. In this paper, we empirically find that the accuracy of the LLM's prediction is highly correlated to its certainty. Based on this, we propose an efficient training free framework, named XL3M (it means extra-long large language model), which enables the LLMs trained on short sequences to reason extremely long sequence without any further training or fine-tuning. Under the XL3M framework, the input context will be firstly decomposed into multiple short sub-contexts, where each sub-context contains an independent segment and a common ``question'' which is a few tokens from the end of the original context. Then XL3M gives a method to measure the relevance between each segment and the ``question'', and constructs a concise key context by splicing all the relevant segments in chronological order. The key context is further used instead of the original context to complete the inference task. Evaluations on comprehensive benchmarks show the superiority of XL3M. Using our framework, a Llama2-7B model is able to reason 20M long sequences on an 8-card Huawei Ascend 910B NPU machine with 64GB memory per card.