 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSkillRevise: Improving LLM-Authored Agent Skills via Trace-Conditioned Skill Revision
May 31, 2026Agent skills are procedural artifacts that enable LLM agents to execute workflows, verify constraints, and recover from failures. Existing self-evolving methods refine skills using accumulated trajectories. However, they struggle in cold-start settings, where only an initial, imperfect skill is available. Consequently, skill construction defaults to expert authoring or one-shot LLM generation. Expert-authored skills are costly and may not align with how LLM agents actually execute tasks, while one-shot generated skills can be syntactically well formed yet behaviorally weak. To bridge this gap, we propose SkillRevise, an execution-grounded framework designed to iteratively refine these initial skills. SkillRevise diagnoses skill defects from execution evidence, retrieves relevant repair principles from a general memory, and applies execution-anchored edits. By re-executing candidates and measuring empirical utility, it systematically retains the optimal skill version. Evaluated across three benchmarks and five LLMs, SkillRevise substantially outperforms one-shot baselines, improving the base agent's success rate on SkillsBench from 36.05% to 61.63%. Furthermore, the revised skills exhibit strong cross-model transferability, capturing generalized procedural knowledge over model-specific artifacts.
LLM-Hanabi: Evaluating Multi-Agent Gameplays with Theory-of-Mind and Rationale Inference in Imperfect Information Collaboration Game
Oct 06, 2025



Effective multi-agent collaboration requires agents to infer the rationale behind others' actions, a capability rooted in Theory-of-Mind (ToM). While recent Large Language Models (LLMs) excel at logical inference, their ability to infer rationale in dynamic, collaborative settings remains under-explored. This study introduces LLM-Hanabi, a novel benchmark that uses the cooperative game Hanabi to evaluate the rationale inference and ToM of LLMs. Our framework features an automated evaluation system that measures both game performance and ToM proficiency. Across a range of models, we find a significant positive correlation between ToM and in-game success. Notably, first-order ToM (interpreting others' intent) correlates more strongly with performance than second-order ToM (predicting others' interpretations). These findings highlight that for effective AI collaboration, the ability to accurately interpret a partner's rationale is more critical than higher-order reasoning. We conclude that prioritizing first-order ToM is a promising direction for enhancing the collaborative capabilities of future models.
AutoSchemaKG: Autonomous Knowledge Graph Construction through Dynamic Schema Induction from Web-Scale Corpora
May 29, 2025
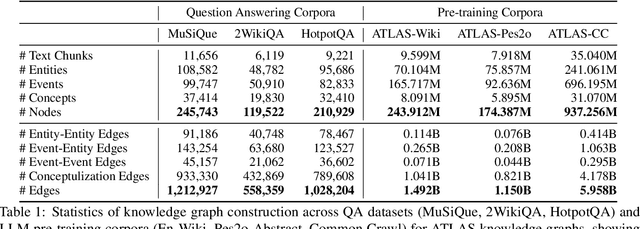
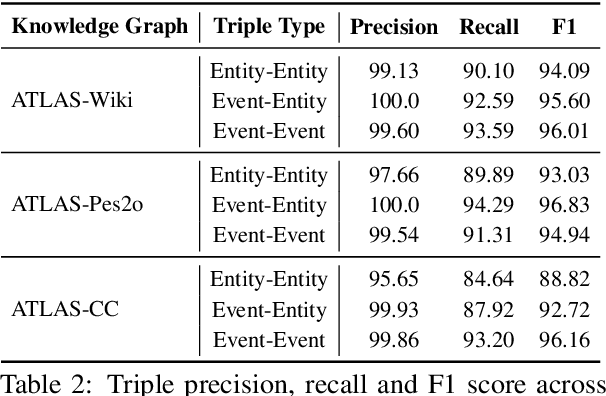

We present AutoSchemaKG, a framework for fully autonomous knowledge graph construction that eliminates the need for predefined schemas. Our system leverages large language models to simultaneously extract knowledge triples and induce comprehensive schemas directly from text, modeling both entities and events while employing conceptualization to organize instances into semantic categories. Processing over 50 million documents, we construct ATLAS (Automated Triple Linking And Schema induction), a family of knowledge graphs with 900+ million nodes and 5.9 billion edges. This approach outperforms state-of-the-art baselines on multi-hop QA tasks and enhances LLM factuality. Notably, our schema induction achieves 95\% semantic alignment with human-crafted schemas with zero manual intervention, demonstrating that billion-scale knowledge graphs with dynamically induced schemas can effectively complement parametric knowledge in large language models.
Persona Knowledge-Aligned Prompt Tuning Method for Online Debate
Oct 05, 2024



Debate is the process of exchanging viewpoints or convincing others on a particular issue. Recent research has provided empirical evidence that the persuasiveness of an argument is determined not only by language usage but also by communicator characteristics. Researchers have paid much attention to aspects of languages, such as linguistic features and discourse structures, but combining argument persuasiveness and impact with the social personae of the audience has not been explored due to the difficulty and complexity. We have observed the impressive simulation and personification capability of ChatGPT, indicating a giant pre-trained language model may function as an individual to provide personae and exert unique influences based on diverse background knowledge. Therefore, we propose a persona knowledge-aligned framework for argument quality assessment tasks from the audience side. This is the first work that leverages the emergence of ChatGPT and injects such audience personae knowledge into smaller language models via prompt tuning. The performance of our pipeline demonstrates significant and consistent improvement compared to competitive architectures.
ActPlan-1K: Benchmarking the Procedural Planning Ability of Visual Language Models in Household Activities
Oct 04, 2024



Large language models~(LLMs) have been adopted to process textual task description and accomplish procedural planning in embodied AI tasks because of their powerful reasoning ability. However, there is still lack of study on how vision language models~(VLMs) behave when multi-modal task inputs are considered. Counterfactual planning that evaluates the model's reasoning ability over alternative task situations are also under exploited. In order to evaluate the planning ability of both multi-modal and counterfactual aspects, we propose ActPlan-1K. ActPlan-1K is a multi-modal planning benchmark constructed based on ChatGPT and household activity simulator iGibson2. The benchmark consists of 153 activities and 1,187 instances. Each instance describing one activity has a natural language task description and multiple environment images from the simulator. The gold plan of each instance is action sequences over the objects in provided scenes. Both the correctness and commonsense satisfaction are evaluated on typical VLMs. It turns out that current VLMs are still struggling at generating human-level procedural plans for both normal activities and counterfactual activities. We further provide automatic evaluation metrics by finetuning over BLEURT model to facilitate future research on our benchmark.
Evaluating and Enhancing LLMs Agent based on Theory of Mind in Guandan: A Multi-Player Cooperative Game under Imperfect Information
Aug 05, 2024



Large language models (LLMs) have shown success in handling simple games with imperfect information and enabling multi-agent coordination, but their ability to facilitate practical collaboration against other agents in complex, imperfect information environments, especially in a non-English environment, still needs to be explored. This study investigates the applicability of knowledge acquired by open-source and API-based LLMs to sophisticated text-based games requiring agent collaboration under imperfect information, comparing their performance to established baselines using other types of agents. We propose a Theory of Mind (ToM) planning technique that allows LLM agents to adapt their strategy against various adversaries using only game rules, current state, and historical context as input. An external tool was incorporated to mitigate the challenge of dynamic and extensive action spaces in this card game. Our results show that although a performance gap exists between current LLMs and state-of-the-art reinforcement learning (RL) models, LLMs demonstrate ToM capabilities in this game setting. It consistently improves their performance against opposing agents, suggesting their ability to understand the actions of allies and adversaries and establish collaboration with allies. To encourage further research and understanding, we have made our codebase openly accessible.
CLR-Fact: Evaluating the Complex Logical Reasoning Capability of Large Language Models over Factual Knowledge
Jul 30, 2024



While large language models (LLMs) have demonstrated impressive capabilities across various natural language processing tasks by acquiring rich factual knowledge from their broad training data, their ability to synthesize and logically reason with this knowledge in complex ways remains underexplored. In this work, we present a systematic evaluation of state-of-the-art LLMs' complex logical reasoning abilities through a novel benchmark of automatically generated complex reasoning questions over general domain and biomedical knowledge graphs. Our extensive experiments, employing diverse in-context learning techniques, reveal that LLMs excel at reasoning over general world knowledge but face significant challenges with specialized domain-specific knowledge. We find that prompting with explicit Chain-of-Thought demonstrations can substantially improve LLM performance on complex logical reasoning tasks with diverse logical operations. Interestingly, our controlled evaluations uncover an asymmetry where LLMs display proficiency at set union operations, but struggle considerably with set intersections - a key building block of logical reasoning. To foster further work, we will publicly release our evaluation benchmark and code.
Text-Tuple-Table: Towards Information Integration in Text-to-Table Generation via Global Tuple Extraction
Apr 22, 2024



The task of condensing large chunks of textual information into concise and structured tables has gained attention recently due to the emergence of Large Language Models (LLMs) and their potential benefit for downstream tasks, such as text summarization and text mining. Previous approaches often generate tables that directly replicate information from the text, limiting their applicability in broader contexts, as text-to-table generation in real-life scenarios necessitates information extraction, reasoning, and integration. However, there is a lack of both datasets and methodologies towards this task. In this paper, we introduce LiveSum, a new benchmark dataset created for generating summary tables of competitions based on real-time commentary texts. We evaluate the performances of state-of-the-art LLMs on this task in both fine-tuning and zero-shot settings, and additionally propose a novel pipeline called $T^3$(Text-Tuple-Table) to improve their performances. Extensive experimental results demonstrate that LLMs still struggle with this task even after fine-tuning, while our approach can offer substantial performance gains without explicit training. Further analyses demonstrate that our method exhibits strong generalization abilities, surpassing previous approaches on several other text-to-table datasets. Our code and data can be found at https://github.com/HKUST-KnowComp/LiveSum-TTT.
NegotiationToM: A Benchmark for Stress-testing Machine Theory of Mind on Negotiation Surrounding
Apr 21, 2024Large Language Models (LLMs) have sparked substantial interest and debate concerning their potential emergence of Theory of Mind (ToM) ability. Theory of mind evaluations currently focuses on testing models using machine-generated data or game settings prone to shortcuts and spurious correlations, which lacks evaluation of machine ToM ability in real-world human interaction scenarios. This poses a pressing demand to develop new real-world scenario benchmarks. We introduce NegotiationToM, a new benchmark designed to stress-test machine ToM in real-world negotiation surrounding covered multi-dimensional mental states (i.e., desires, beliefs, and intentions). Our benchmark builds upon the Belief-Desire-Intention (BDI) agent modeling theory and conducts the necessary empirical experiments to evaluate large language models. Our findings demonstrate that NegotiationToM is challenging for state-of-the-art LLMs, as they consistently perform significantly worse than humans, even when employing the chain-of-thought (CoT) method.