 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNewtonBench: Benchmarking Generalizable Scientific Law Discovery in LLM Agents
Oct 08, 2025Large language models are emerging as powerful tools for scientific law discovery, a foundational challenge in AI-driven science. However, existing benchmarks for this task suffer from a fundamental methodological trilemma, forcing a trade-off between scientific relevance, scalability, and resistance to memorization. Furthermore, they oversimplify discovery as static function fitting, failing to capture the authentic scientific process of uncovering embedded laws through the interactive exploration of complex model systems. To address these critical gaps, we introduce NewtonBench, a benchmark comprising 324 scientific law discovery tasks across 12 physics domains. Our design mitigates the evaluation trilemma by using metaphysical shifts - systematic alterations of canonical laws - to generate a vast suite of problems that are scalable, scientifically relevant, and memorization-resistant. Moreover, we elevate the evaluation from static function fitting to interactive model discovery, requiring agents to experimentally probe simulated complex systems to uncover hidden principles. Our extensive experiment reveals a clear but fragile capability for discovery in frontier LLMs: this ability degrades precipitously with increasing system complexity and exhibits extreme sensitivity to observational noise. Notably, we uncover a paradoxical effect of tool assistance: providing a code interpreter can hinder more capable models by inducing a premature shift from exploration to exploitation, causing them to satisfice on suboptimal solutions. These results demonstrate that robust, generalizable discovery in complex, interactive environments remains the core challenge. By providing a scalable, robust, and scientifically authentic testbed, NewtonBench offers a crucial tool for measuring true progress and guiding the development of next-generation AI agents capable of genuine scientific discovery.
The Curse of CoT: On the Limitations of Chain-of-Thought in In-Context Learning
Apr 07, 2025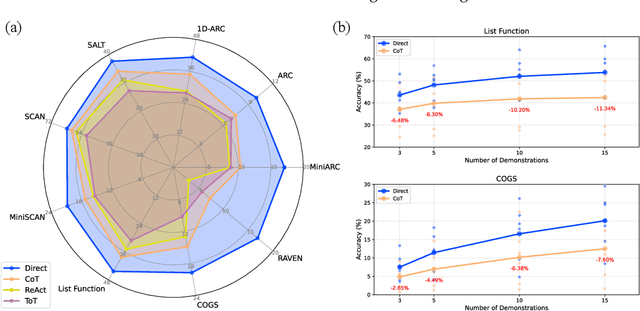
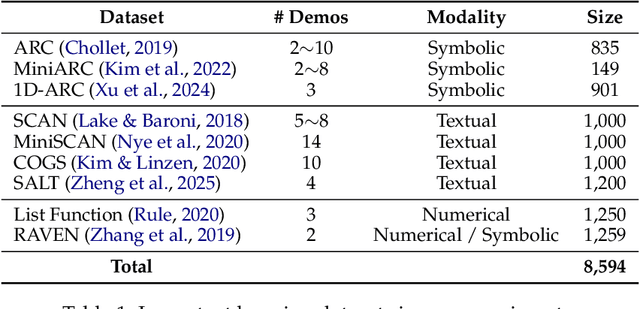
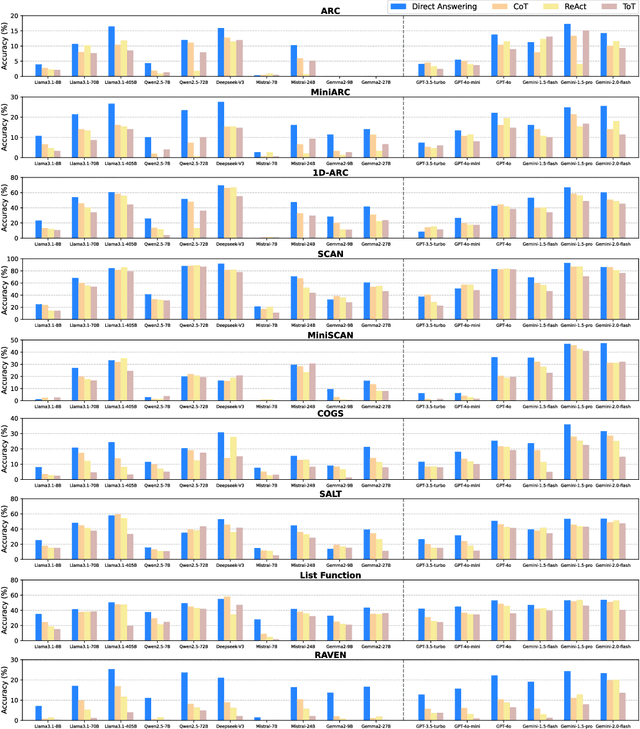
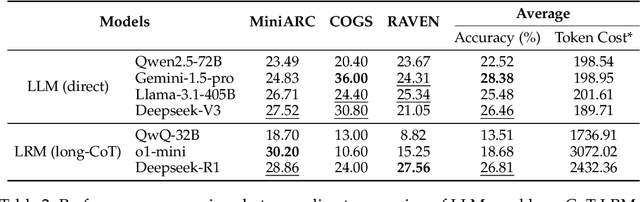
Chain-of-Thought (CoT) prompting has been widely recognized for its ability to enhance reasoning capabilities in large language models (LLMs) through the generation of explicit explanatory rationales. However, our study reveals a surprising contradiction to this prevailing perspective. Through extensive experiments involving 16 state-of-the-art LLMs and nine diverse pattern-based in-context learning (ICL) datasets, we demonstrate that CoT and its reasoning variants consistently underperform direct answering across varying model scales and benchmark complexities. To systematically investigate this unexpected phenomenon, we designed extensive experiments to validate several hypothetical explanations. Our analysis uncovers a fundamental explicit-implicit duality driving CoT's performance in pattern-based ICL: while explicit reasoning falters due to LLMs' struggles to infer underlying patterns from demonstrations, implicit reasoning-disrupted by the increased contextual distance of CoT rationales-often compensates, delivering correct answers despite flawed rationales. This duality explains CoT's relative underperformance, as noise from weak explicit inference undermines the process, even as implicit mechanisms partially salvage outcomes. Notably, even long-CoT reasoning models, which excel in abstract and symbolic reasoning, fail to fully overcome these limitations despite higher computational costs. Our findings challenge existing assumptions regarding the universal efficacy of CoT, yielding novel insights into its limitations and guiding future research toward more nuanced and effective reasoning methodologies for LLMs.
Persona Knowledge-Aligned Prompt Tuning Method for Online Debate
Oct 05, 2024



Debate is the process of exchanging viewpoints or convincing others on a particular issue. Recent research has provided empirical evidence that the persuasiveness of an argument is determined not only by language usage but also by communicator characteristics. Researchers have paid much attention to aspects of languages, such as linguistic features and discourse structures, but combining argument persuasiveness and impact with the social personae of the audience has not been explored due to the difficulty and complexity. We have observed the impressive simulation and personification capability of ChatGPT, indicating a giant pre-trained language model may function as an individual to provide personae and exert unique influences based on diverse background knowledge. Therefore, we propose a persona knowledge-aligned framework for argument quality assessment tasks from the audience side. This is the first work that leverages the emergence of ChatGPT and injects such audience personae knowledge into smaller language models via prompt tuning. The performance of our pipeline demonstrates significant and consistent improvement compared to competitive architectures.
AbsInstruct: Eliciting Abstraction Ability from LLMs through Explanation Tuning with Plausibility Estimation
Feb 16, 2024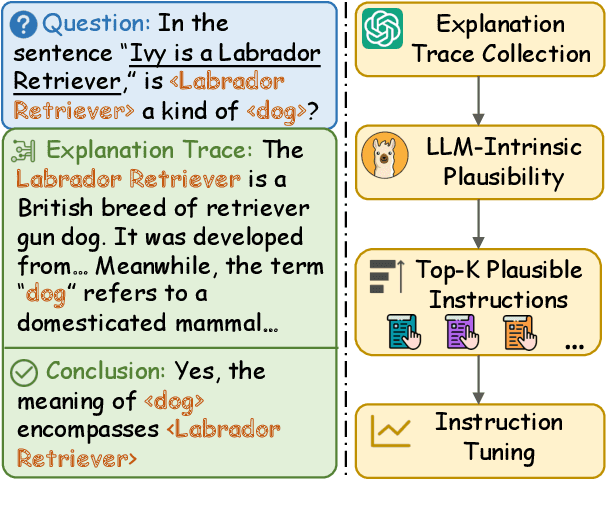

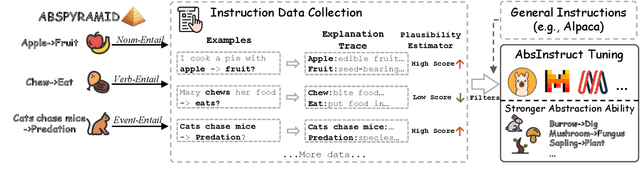
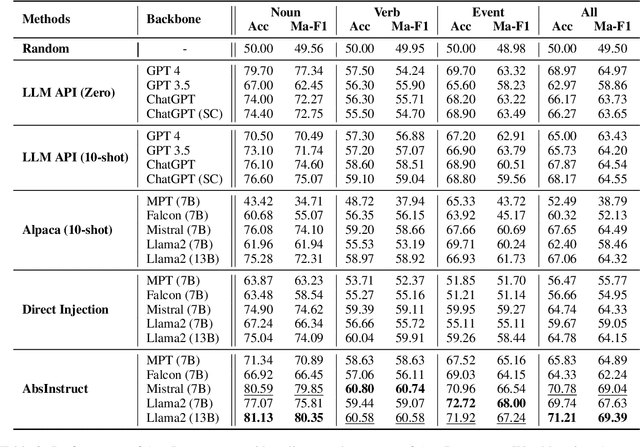
Abstraction ability is crucial in human intelligence, which can also benefit various tasks in NLP study. Existing work shows that LLMs are deficient in abstract ability, and how to improve it remains unexplored. In this work, we design the framework AbsInstruct to enhance LLMs' abstraction ability through instruction tuning. The framework builds instructions with in-depth explanations to assist LLMs in capturing the underlying rationale of abstraction. Meanwhile, we introduce a plausibility estimator to select instructions that are more consistent with the abstraction knowledge of LLMs to be aligned. Then, our framework combines abstraction instructions with general-purpose ones to build a hybrid dataset. Extensive experiments and analyses demonstrate that our framework can considerably enhance LLMs' abstraction ability with strong generalization performance while maintaining their general instruction-following abilities.
TILFA: A Unified Framework for Text, Image, and Layout Fusion in Argument Mining
Oct 08, 2023A main goal of Argument Mining (AM) is to analyze an author's stance. Unlike previous AM datasets focusing only on text, the shared task at the 10th Workshop on Argument Mining introduces a dataset including both text and images. Importantly, these images contain both visual elements and optical characters. Our new framework, TILFA (A Unified Framework for Text, Image, and Layout Fusion in Argument Mining), is designed to handle this mixed data. It excels at not only understanding text but also detecting optical characters and recognizing layout details in images. Our model significantly outperforms existing baselines, earning our team, KnowComp, the 1st place in the leaderboard of Argumentative Stance Classification subtask in this shared task.
COLA: Contextualized Commonsense Causal Reasoning from the Causal Inference Perspective
May 09, 2023Detecting commonsense causal relations (causation) between events has long been an essential yet challenging task. Given that events are complicated, an event may have different causes under various contexts. Thus, exploiting context plays an essential role in detecting causal relations. Meanwhile, previous works about commonsense causation only consider two events and ignore their context, simplifying the task formulation. This paper proposes a new task to detect commonsense causation between two events in an event sequence (i.e., context), called contextualized commonsense causal reasoning. We also design a zero-shot framework: COLA (Contextualized Commonsense Causality Reasoner) to solve the task from the causal inference perspective. This framework obtains rich incidental supervision from temporality and balances covariates from multiple timestamps to remove confounding effects. Our extensive experiments show that COLA can detect commonsense causality more accurately than baselines.
DiscoPrompt: Path Prediction Prompt Tuning for Implicit Discourse Relation Recognition
May 06, 2023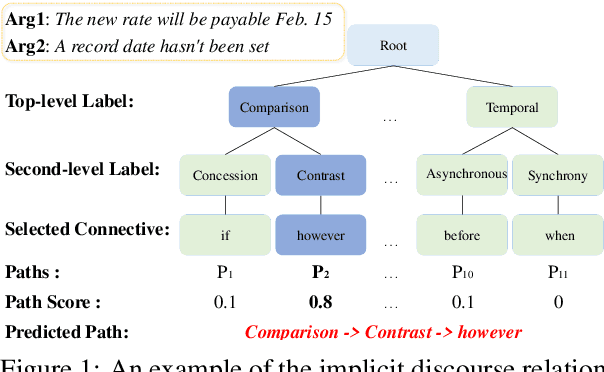
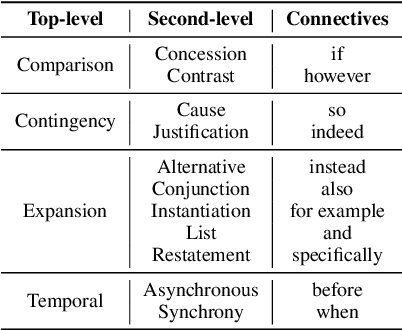
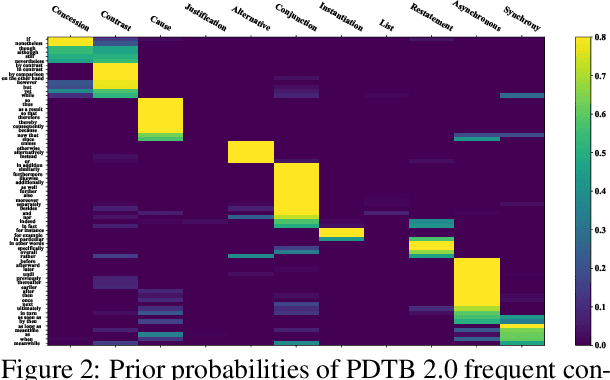
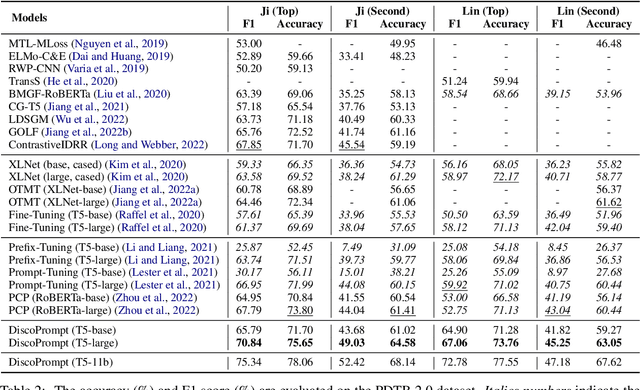
Implicit Discourse Relation Recognition (IDRR) is a sophisticated and challenging task to recognize the discourse relations between the arguments with the absence of discourse connectives. The sense labels for each discourse relation follow a hierarchical classification scheme in the annotation process (Prasad et al., 2008), forming a hierarchy structure. Most existing works do not well incorporate the hierarchy structure but focus on the syntax features and the prior knowledge of connectives in the manner of pure text classification. We argue that it is more effective to predict the paths inside the hierarchical tree (e.g., "Comparison -> Contrast -> however") rather than flat labels (e.g., Contrast) or connectives (e.g., however). We propose a prompt-based path prediction method to utilize the interactive information and intrinsic senses among the hierarchy in IDRR. This is the first work that injects such structure information into pre-trained language models via prompt tuning, and the performance of our solution shows significant and consistent improvement against competitive baselines.
Wasserstein-Fisher-Rao Embedding: Logical Query Embeddings with Local Comparison and Global Transport
May 06, 2023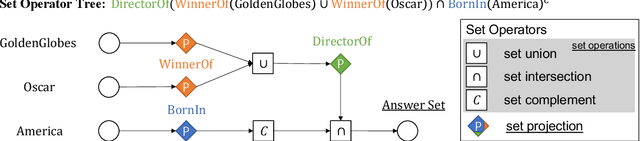
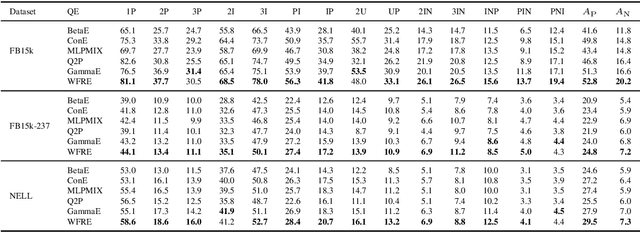
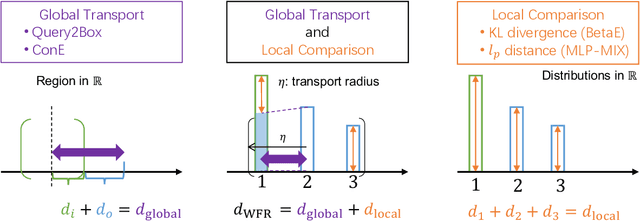

Answering complex queries on knowledge graphs is important but particularly challenging because of the data incompleteness. Query embedding methods address this issue by learning-based models and simulating logical reasoning with set operators. Previous works focus on specific forms of embeddings, but scoring functions between embeddings are underexplored. In contrast to existing scoring functions motivated by local comparison or global transport, this work investigates the local and global trade-off with unbalanced optimal transport theory. Specifically, we embed sets as bounded measures in $\real$ endowed with a scoring function motivated by the Wasserstein-Fisher-Rao metric. Such a design also facilitates closed-form set operators in the embedding space. Moreover, we introduce a convolution-based algorithm for linear time computation and a block-diagonal kernel to enforce the trade-off. Results show that WFRE can outperform existing query embedding methods on standard datasets, evaluation sets with combinatorially complex queries, and hierarchical knowledge graphs. Ablation study shows that finding a better local and global trade-off is essential for performance improvement.
Logical Message Passing Networks with One-hop Inference on Atomic Formulas
Jan 21, 2023Complex Query Answering (CQA) over Knowledge Graphs (KGs) has attracted a lot of attention to potentially support many applications. Given that KGs are usually incomplete, neural models are proposed to answer logical queries by parameterizing set operators with complex neural networks. However, such methods usually train neural set operators with a large number of entity and relation embeddings from zero, where whether and how the embeddings or the neural set operators contribute to the performance remains not clear. In this paper, we propose a simple framework for complex query answering that decomposes the KG embeddings from neural set operators. We propose to represent the complex queries in the query graph. On top of the query graph, we propose the Logical Message Passing Neural Network (LMPNN) that connects the \textit{local} one-hop inferences on atomic formulas to the \textit{global} logical reasoning for complex query answering. We leverage existing effective KG embeddings to conduct one-hop inferences on atomic formulas, the results of which are regarded as the messages passed in LMPNN. The reasoning process over the overall logical formulas is turned into the forward pass of LMPNN that incrementally aggregates local information to predict the answers' embeddings finally. The complex logical inference across different types of queries will then be learned from training examples based on the LMPNN architecture. Theoretically, our query-graph representation is more general than the prevailing operator-tree formulation, so our approach applies to a broader range of complex KG queries. Empirically, our approach yields a new state-of-the-art neural CQA model. Our research bridges the gap between complex KG query answering tasks and the long-standing achievements of knowledge graph representation learning.
Complex Hyperbolic Knowledge Graph Embeddings with Fast Fourier Transform
Nov 07, 2022The choice of geometric space for knowledge graph (KG) embeddings can have significant effects on the performance of KG completion tasks. The hyperbolic geometry has been shown to capture the hierarchical patterns due to its tree-like metrics, which addressed the limitations of the Euclidean embedding models. Recent explorations of the complex hyperbolic geometry further improved the hyperbolic embeddings for capturing a variety of hierarchical structures. However, the performance of the hyperbolic KG embedding models for non-transitive relations is still unpromising, while the complex hyperbolic embeddings do not deal with multi-relations. This paper aims to utilize the representation capacity of the complex hyperbolic geometry in multi-relational KG embeddings. To apply the geometric transformations which account for different relations and the attention mechanism in the complex hyperbolic space, we propose to use the fast Fourier transform (FFT) as the conversion between the real and complex hyperbolic space. Constructing the attention-based transformations in the complex space is very challenging, while the proposed Fourier transform-based complex hyperbolic approaches provide a simple and effective solution. Experimental results show that our methods outperform the baselines, including the Euclidean and the real hyperbolic embedding models.