 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEntailE: Introducing Textual Entailment in Commonsense Knowledge Graph Completion
Feb 15, 2024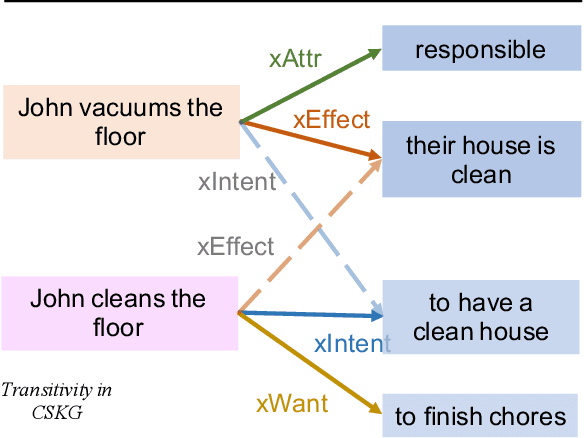
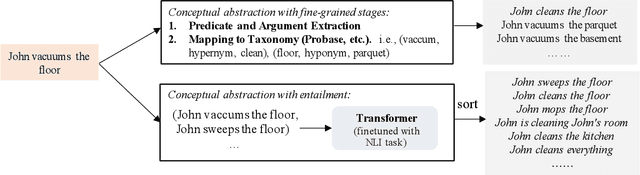
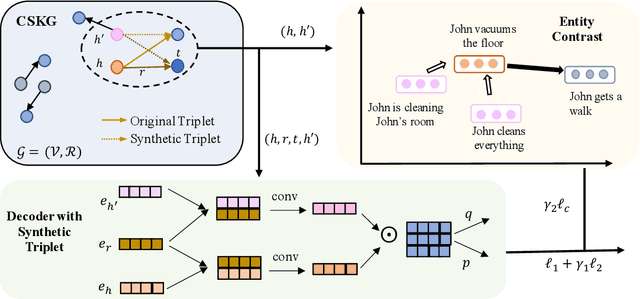
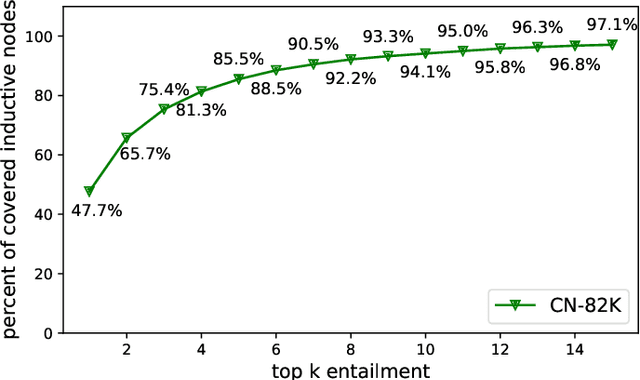
Commonsense knowledge graph completion is a new challenge for commonsense knowledge graph construction and application. In contrast to factual knowledge graphs such as Freebase and YAGO, commonsense knowledge graphs (CSKGs; e.g., ConceptNet) utilize free-form text to represent named entities, short phrases, and events as their nodes. Such a loose structure results in large and sparse CSKGs, which makes the semantic understanding of these nodes more critical for learning rich commonsense knowledge graph embedding. While current methods leverage semantic similarities to increase the graph density, the semantic plausibility of the nodes and their relations are under-explored. Previous works adopt conceptual abstraction to improve the consistency of modeling (event) plausibility, but they are not scalable enough and still suffer from data sparsity. In this paper, we propose to adopt textual entailment to find implicit entailment relations between CSKG nodes, to effectively densify the subgraph connecting nodes within the same conceptual class, which indicates a similar level of plausibility. Each node in CSKG finds its top entailed nodes using a finetuned transformer over natural language inference (NLI) tasks, which sufficiently capture textual entailment signals. The entailment relation between these nodes are further utilized to: 1) build new connections between source triplets and entailed nodes to densify the sparse CSKGs; 2) enrich the generalization ability of node representations by comparing the node embeddings with a contrastive loss. Experiments on two standard CSKGs demonstrate that our proposed framework EntailE can improve the performance of CSKG completion tasks under both transductive and inductive settings.
Complex Hyperbolic Knowledge Graph Embeddings with Fast Fourier Transform
Nov 07, 2022The choice of geometric space for knowledge graph (KG) embeddings can have significant effects on the performance of KG completion tasks. The hyperbolic geometry has been shown to capture the hierarchical patterns due to its tree-like metrics, which addressed the limitations of the Euclidean embedding models. Recent explorations of the complex hyperbolic geometry further improved the hyperbolic embeddings for capturing a variety of hierarchical structures. However, the performance of the hyperbolic KG embedding models for non-transitive relations is still unpromising, while the complex hyperbolic embeddings do not deal with multi-relations. This paper aims to utilize the representation capacity of the complex hyperbolic geometry in multi-relational KG embeddings. To apply the geometric transformations which account for different relations and the attention mechanism in the complex hyperbolic space, we propose to use the fast Fourier transform (FFT) as the conversion between the real and complex hyperbolic space. Constructing the attention-based transformations in the complex space is very challenging, while the proposed Fourier transform-based complex hyperbolic approaches provide a simple and effective solution. Experimental results show that our methods outperform the baselines, including the Euclidean and the real hyperbolic embedding models.
Unit Ball Model for Embedding Hierarchical Structures in the Complex Hyperbolic Space
Jun 05, 2021
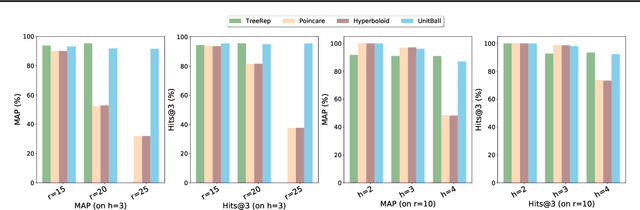
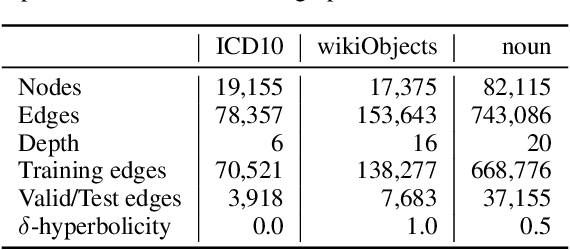
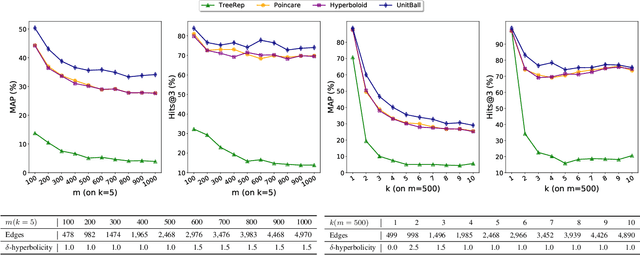
Learning the representation of data with hierarchical structures in the hyperbolic space attracts increasing attention in recent years. Due to the constant negative curvature, the hyperbolic space resembles tree metrics and captures the tree-like properties naturally, which enables the hyperbolic embeddings to improve over traditional Euclidean models. However, many real-world hierarchically structured data such as taxonomies and multitree networks have varying local structures and they are not trees, thus they do not ubiquitously match the constant curvature property of the hyperbolic space. To address this limitation of hyperbolic embeddings, we explore the complex hyperbolic space, which has the variable negative curvature, for representation learning. Specifically, we propose to learn the embeddings of hierarchically structured data in the unit ball model of the complex hyperbolic space. The unit ball model based embeddings have a more powerful representation capacity to capture a variety of hierarchical structures. Through experiments on synthetic and real-world data, we show that our approach improves over the hyperbolic embedding models significantly.
Efficient Path Prediction for Semi-Supervised and Weakly Supervised Hierarchical Text Classification
Feb 25, 2019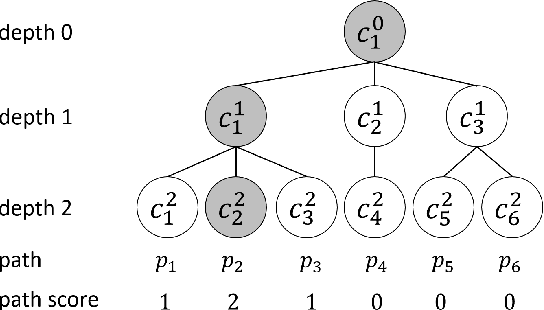
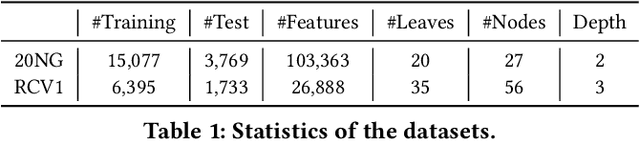
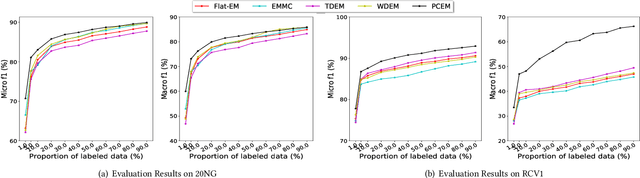
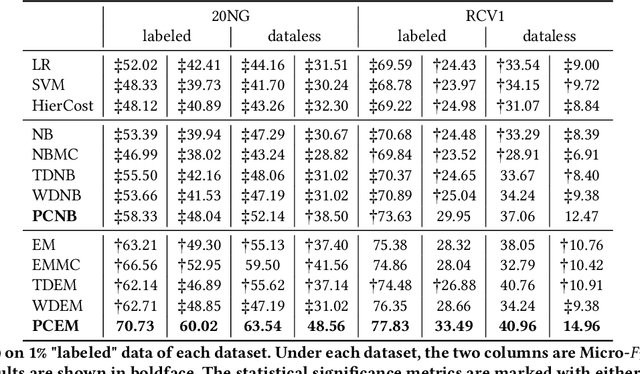
Hierarchical text classification has many real-world applications. However, labeling a large number of documents is costly. In practice, we can use semi-supervised learning or weakly supervised learning (e.g., dataless classification) to reduce the labeling cost. In this paper, we propose a path cost-sensitive learning algorithm to utilize the structural information and further make use of unlabeled and weakly-labeled data. We use a generative model to leverage the large amount of unlabeled data and introduce path constraints into the learning algorithm to incorporate the structural information of the class hierarchy. The posterior probabilities of both unlabeled and weakly labeled data can be incorporated with path-dependent scores. Since we put a structure-sensitive cost to the learning algorithm to constrain the classification consistent with the class hierarchy and do not need to reconstruct the feature vectors for different structures, we can significantly reduce the computational cost compared to structural output learning. Experimental results on two hierarchical text classification benchmarks show that our approach is not only effective but also efficient to handle the semi-supervised and weakly supervised hierarchical text classification.