 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeParameter-Efficient Checkpoint Merging via Metrics-Weighted Averaging
Apr 23, 2025


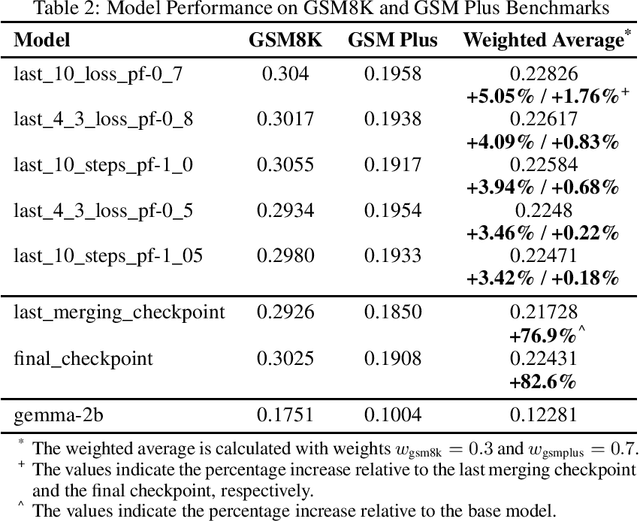
Checkpoint merging is a technique for combining multiple model snapshots into a single superior model, potentially reducing training time for large language models. This paper explores checkpoint merging in the context of parameter-efficient fine-tuning (PEFT), where only small adapter modules (e.g. LoRA) are trained. We propose Metrics-Weighted Averaging (MWA), a simple yet effective method to merge model checkpoints by weighting their parameters according to performance metrics. In particular, we investigate weighting by training loss and by training steps, under the intuition that lower-loss or later-step checkpoints are more valuable. We introduce a formula with a penalty factor to adjust weight distribution, requiring only one hyperparameter regardless of the number of checkpoints. Experiments on three fine-tuning tasks (mathematical reasoning, preference alignment, and general instruction tuning) show that MWA consistently produces merged models that outperform the naive uniform average of checkpoints. Notably, loss-weighted merging often yields the best results, delivering up to 5% higher task accuracy than the baseline uniform merge and even surpassing the final individual checkpoint's performance. These findings validate checkpoint merging for PEFT and demonstrate that a metric-driven weighting heuristic can efficiently boost model performance with minimal computational overhead.
Cross-Architecture Transfer Learning for Linear-Cost Inference Transformers
Apr 03, 2024Recently, multiple architectures has been proposed to improve the efficiency of the Transformer Language Models through changing the design of the self-attention block to have a linear-cost inference (LCI). A notable approach in this realm is the State-Space Machines (SSMs) architecture, which showed on-par performance on language modeling tasks with the self-attention transformers. However, such an architectural change requires a full pretraining of the weights from scratch, which incurs a huge cost to researchers and practitioners who want to use the new architectures. In the more traditional linear attention works, it has been proposed to approximate full attention with linear attention by swap-and-finetune framework. Motivated by this approach, we propose Cross-Architecture Transfer Learning (XATL), in which the weights of the shared components between LCI and self-attention-based transformers, such as layernorms, MLPs, input/output embeddings, are directly transferred to the new architecture from already pre-trained model parameters. We experimented the efficacy of the method on varying sizes and alternative attention architectures and show that \methodabbr significantly reduces the training time up to 2.5x times and converges to a better minimum with up to 2.6% stronger model on the LM benchmarks within the same compute budget.
AbsInstruct: Eliciting Abstraction Ability from LLMs through Explanation Tuning with Plausibility Estimation
Feb 16, 2024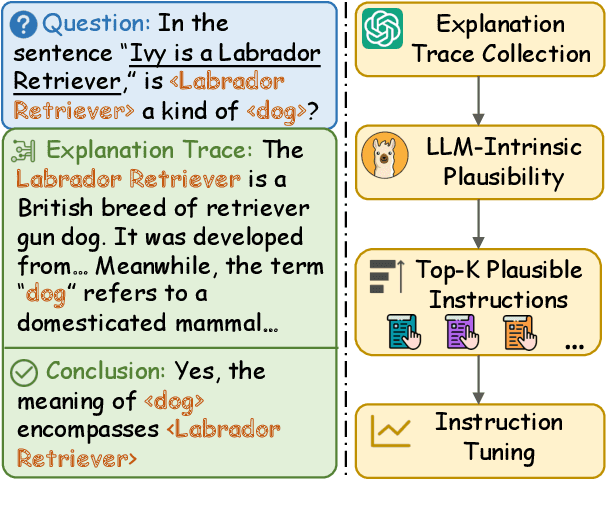

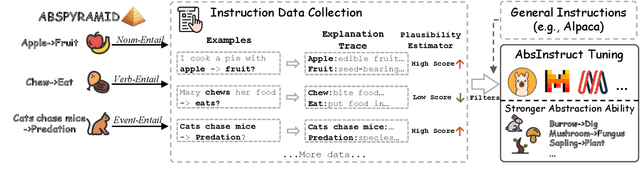
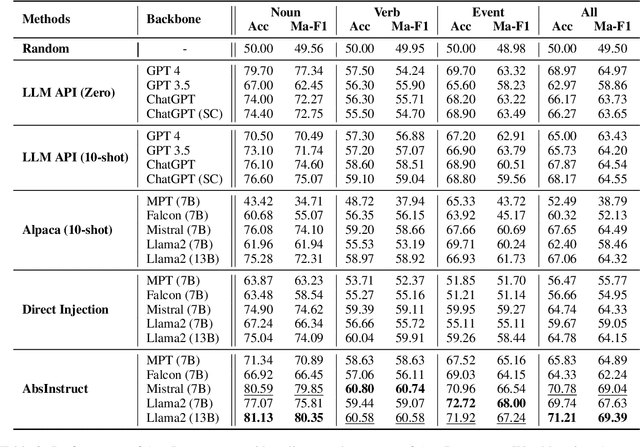
Abstraction ability is crucial in human intelligence, which can also benefit various tasks in NLP study. Existing work shows that LLMs are deficient in abstract ability, and how to improve it remains unexplored. In this work, we design the framework AbsInstruct to enhance LLMs' abstraction ability through instruction tuning. The framework builds instructions with in-depth explanations to assist LLMs in capturing the underlying rationale of abstraction. Meanwhile, we introduce a plausibility estimator to select instructions that are more consistent with the abstraction knowledge of LLMs to be aligned. Then, our framework combines abstraction instructions with general-purpose ones to build a hybrid dataset. Extensive experiments and analyses demonstrate that our framework can considerably enhance LLMs' abstraction ability with strong generalization performance while maintaining their general instruction-following abilities.
AbsPyramid: Benchmarking the Abstraction Ability of Language Models with a Unified Entailment Graph
Nov 16, 2023



Cognitive research indicates that abstraction ability is essential in human intelligence, which remains under-explored in language models. In this paper, we present AbsPyramid, a unified entailment graph of 221K textual descriptions of abstraction knowledge. While existing resources only touch nouns or verbs within simplified events or specific domains, AbsPyramid collects abstract knowledge for three components of diverse events to comprehensively evaluate the abstraction ability of language models in the open domain. Experimental results demonstrate that current LLMs face challenges comprehending abstraction knowledge in zero-shot and few-shot settings. By training on our rich abstraction knowledge, we find LLMs can acquire basic abstraction abilities and generalize to unseen events. In the meantime, we empirically show that our benchmark is comprehensive to enhance LLMs across two previous abstraction tasks.
KCTS: Knowledge-Constrained Tree Search Decoding with Token-Level Hallucination Detection
Oct 13, 2023


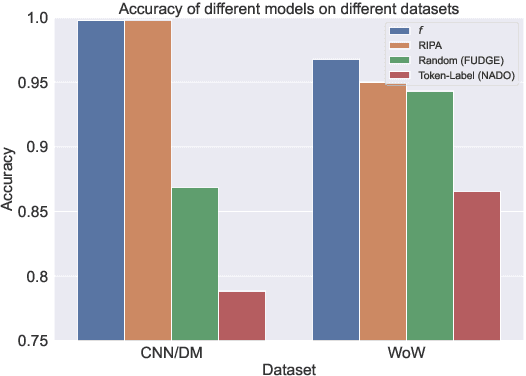
Large Language Models (LLMs) have demonstrated remarkable human-level natural language generation capabilities. However, their potential to generate misinformation, often called the hallucination problem, poses a significant risk to their deployment. A common approach to address this issue is to retrieve relevant knowledge and fine-tune the LLM with the knowledge in its input. Unfortunately, this method incurs high training costs and may cause catastrophic forgetting for multi-tasking models. To overcome these limitations, we propose a knowledge-constrained decoding method called KCTS (Knowledge-Constrained Tree Search), which guides a frozen LM to generate text aligned with the reference knowledge at each decoding step using a knowledge classifier score and MCTS (Monte-Carlo Tree Search). To adapt the sequence-level knowledge classifier to token-level guidance, we also propose a novel token-level hallucination detection method called RIPA (Reward Inflection Point Approximation). Our empirical results on knowledge-grounded dialogue and abstractive summarization demonstrate the strength of KCTS as a plug-and-play, model-agnostic decoding method that can effectively reduce hallucinations in natural language generation.
CKBP v2: An Expert-Annotated Evaluation Set for Commonsense Knowledge Base Population
Apr 20, 2023



Populating Commonsense Knowledge Bases (CSKB) is an important yet hard task in NLP, as it tackles knowledge from external sources with unseen events and entities. Fang et al. (2021a) proposed a CSKB Population benchmark with an evaluation set CKBP v1. However, CKBP v1 adopts crowdsourced annotations that suffer from a substantial fraction of incorrect answers, and the evaluation set is not well-aligned with the external knowledge source as a result of random sampling. In this paper, we introduce CKBP v2, a new high-quality CSKB Population benchmark, which addresses the two mentioned problems by using experts instead of crowd-sourced annotation and by adding diversified adversarial samples to make the evaluation set more representative. We conduct extensive experiments comparing state-of-the-art methods for CSKB Population on the new evaluation set for future research comparisons. Empirical results show that the population task is still challenging, even for large language models (LLM) such as ChatGPT. Codes and data are available at https://github.com/HKUST-KnowComp/CSKB-Population.
Benchmarking Commonsense Knowledge Base Population with an Effective Evaluation Dataset
Sep 16, 2021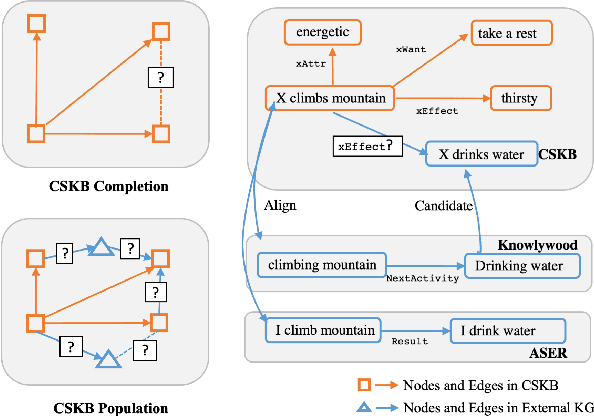
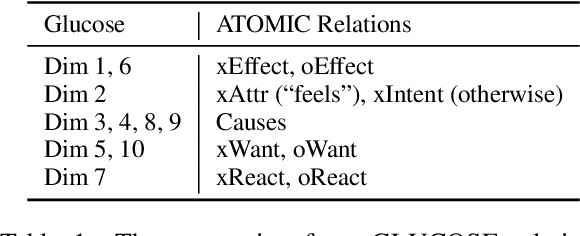
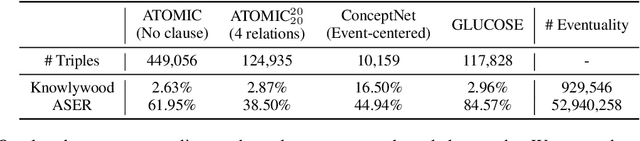

Reasoning over commonsense knowledge bases (CSKB) whose elements are in the form of free-text is an important yet hard task in NLP. While CSKB completion only fills the missing links within the domain of the CSKB, CSKB population is alternatively proposed with the goal of reasoning unseen assertions from external resources. In this task, CSKBs are grounded to a large-scale eventuality (activity, state, and event) graph to discriminate whether novel triples from the eventuality graph are plausible or not. However, existing evaluations on the population task are either not accurate (automatic evaluation with randomly sampled negative examples) or of small scale (human annotation). In this paper, we benchmark the CSKB population task with a new large-scale dataset by first aligning four popular CSKBs, and then presenting a high-quality human-annotated evaluation set to probe neural models' commonsense reasoning ability. We also propose a novel inductive commonsense reasoning model that reasons over graphs. Experimental results show that generalizing commonsense reasoning on unseen assertions is inherently a hard task. Models achieving high accuracy during training perform poorly on the evaluation set, with a large gap between human performance. We will make the data publicly available for future contributions. Codes and data are available at https://github.com/HKUST-KnowComp/CSKB-Population.