 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNAACL: Noise-AwAre Verbal Confidence Calibration for LLMs in RAG Systems
Jan 16, 2026Accurately assessing model confidence is essential for deploying large language models (LLMs) in mission-critical factual domains. While retrieval-augmented generation (RAG) is widely adopted to improve grounding, confidence calibration in RAG settings remains poorly understood. We conduct a systematic study across four benchmarks, revealing that LLMs exhibit poor calibration performance due to noisy retrieved contexts. Specifically, contradictory or irrelevant evidence tends to inflate the model's false certainty, leading to severe overconfidence. To address this, we propose NAACL Rules (Noise-AwAre Confidence CaLibration Rules) to provide a principled foundation for resolving overconfidence under noise. We further design NAACL, a noise-aware calibration framework that synthesizes supervision from about 2K HotpotQA examples guided by these rules. By performing supervised fine-tuning (SFT) with this data, NAACL equips models with intrinsic noise awareness without relying on stronger teacher models. Empirical results show that NAACL yields substantial gains, improving ECE scores by 10.9% in-domain and 8.0% out-of-domain. By bridging the gap between retrieval noise and verbal calibration, NAACL paves the way for both accurate and epistemically reliable LLMs.
Prospect Theory Fails for LLMs: Revealing Instability of Decision-Making under Epistemic Uncertainty
Aug 12, 2025
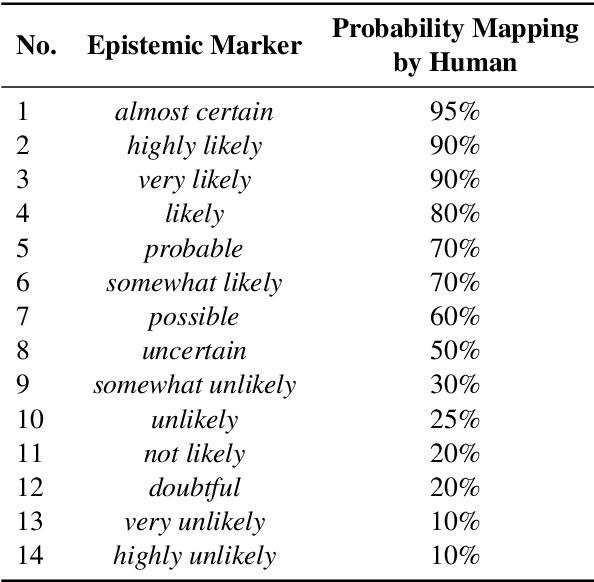

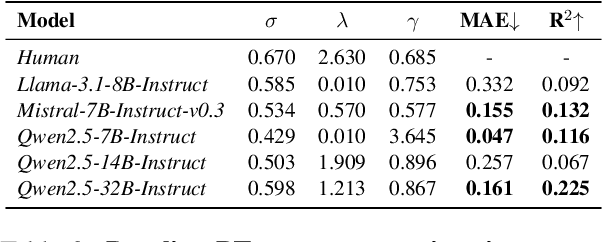
Prospect Theory (PT) models human decision-making under uncertainty, while epistemic markers (e.g., maybe) serve to express uncertainty in language. However, it remains largely unexplored whether Prospect Theory applies to contemporary Large Language Models and whether epistemic markers, which express human uncertainty, affect their decision-making behaviour. To address these research gaps, we design a three-stage experiment based on economic questionnaires. We propose a more general and precise evaluation framework to model LLMs' decision-making behaviour under PT, introducing uncertainty through the empirical probability values associated with commonly used epistemic markers in comparable contexts. We then incorporate epistemic markers into the evaluation framework based on their corresponding probability values to examine their influence on LLM decision-making behaviours. Our findings suggest that modelling LLMs' decision-making with PT is not consistently reliable, particularly when uncertainty is expressed in diverse linguistic forms. Our code is released in https://github.com/HKUST-KnowComp/MarPT.
SessionIntentBench: A Multi-task Inter-session Intention-shift Modeling Benchmark for E-commerce Customer Behavior Understanding
Jul 27, 2025Session history is a common way of recording user interacting behaviors throughout a browsing activity with multiple products. For example, if an user clicks a product webpage and then leaves, it might because there are certain features that don't satisfy the user, which serve as an important indicator of on-the-spot user preferences. However, all prior works fail to capture and model customer intention effectively because insufficient information exploitation and only apparent information like descriptions and titles are used. There is also a lack of data and corresponding benchmark for explicitly modeling intention in E-commerce product purchase sessions. To address these issues, we introduce the concept of an intention tree and propose a dataset curation pipeline. Together, we construct a sibling multimodal benchmark, SessionIntentBench, that evaluates L(V)LMs' capability on understanding inter-session intention shift with four subtasks. With 1,952,177 intention entries, 1,132,145 session intention trajectories, and 13,003,664 available tasks mined using 10,905 sessions, we provide a scalable way to exploit the existing session data for customer intention understanding. We conduct human annotations to collect ground-truth label for a subset of collected data to form an evaluation gold set. Extensive experiments on the annotated data further confirm that current L(V)LMs fail to capture and utilize the intention across the complex session setting. Further analysis show injecting intention enhances LLMs' performances.
Revisiting Epistemic Markers in Confidence Estimation: Can Markers Accurately Reflect Large Language Models' Uncertainty?
May 30, 2025



As large language models (LLMs) are increasingly used in high-stakes domains, accurately assessing their confidence is crucial. Humans typically express confidence through epistemic markers (e.g., "fairly confident") instead of numerical values. However, it remains unclear whether LLMs consistently use these markers to reflect their intrinsic confidence due to the difficulty of quantifying uncertainty associated with various markers. To address this gap, we first define marker confidence as the observed accuracy when a model employs an epistemic marker. We evaluate its stability across multiple question-answering datasets in both in-distribution and out-of-distribution settings for open-source and proprietary LLMs. Our results show that while markers generalize well within the same distribution, their confidence is inconsistent in out-of-distribution scenarios. These findings raise significant concerns about the reliability of epistemic markers for confidence estimation, underscoring the need for improved alignment between marker based confidence and actual model uncertainty. Our code is available at https://github.com/HKUST-KnowComp/MarCon.
AutoSchemaKG: Autonomous Knowledge Graph Construction through Dynamic Schema Induction from Web-Scale Corpora
May 29, 2025
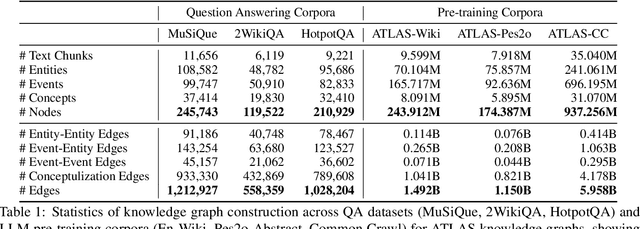
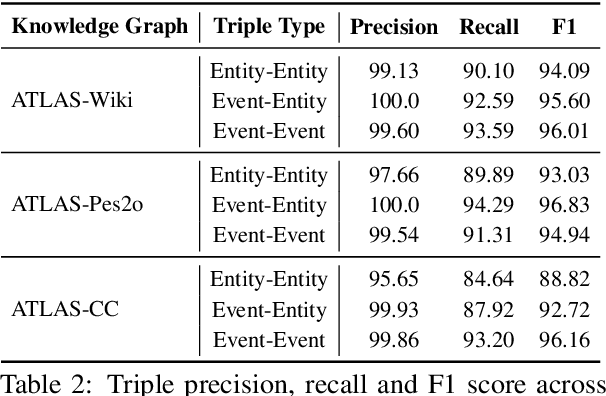

We present AutoSchemaKG, a framework for fully autonomous knowledge graph construction that eliminates the need for predefined schemas. Our system leverages large language models to simultaneously extract knowledge triples and induce comprehensive schemas directly from text, modeling both entities and events while employing conceptualization to organize instances into semantic categories. Processing over 50 million documents, we construct ATLAS (Automated Triple Linking And Schema induction), a family of knowledge graphs with 900+ million nodes and 5.9 billion edges. This approach outperforms state-of-the-art baselines on multi-hop QA tasks and enhances LLM factuality. Notably, our schema induction achieves 95\% semantic alignment with human-crafted schemas with zero manual intervention, demonstrating that billion-scale knowledge graphs with dynamically induced schemas can effectively complement parametric knowledge in large language models.
The Curse of CoT: On the Limitations of Chain-of-Thought in In-Context Learning
Apr 07, 2025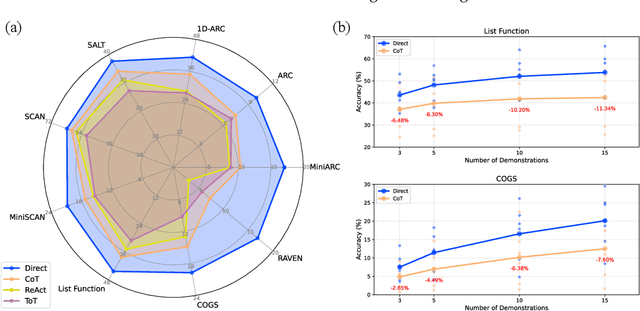
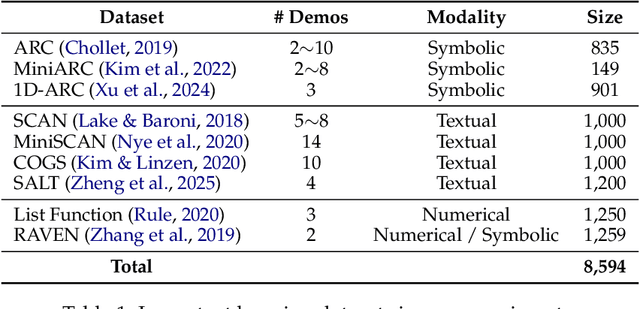
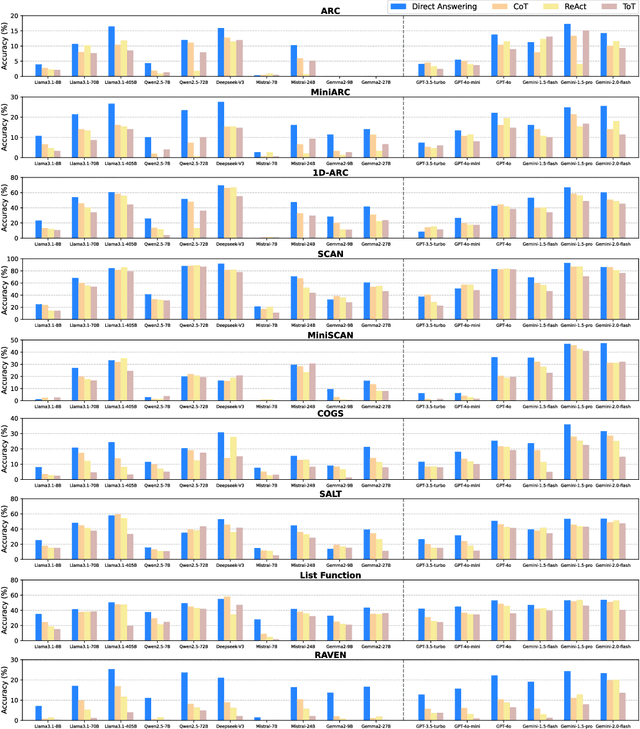
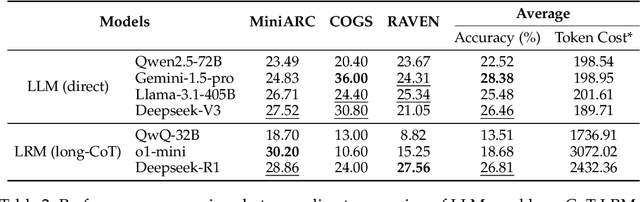
Chain-of-Thought (CoT) prompting has been widely recognized for its ability to enhance reasoning capabilities in large language models (LLMs) through the generation of explicit explanatory rationales. However, our study reveals a surprising contradiction to this prevailing perspective. Through extensive experiments involving 16 state-of-the-art LLMs and nine diverse pattern-based in-context learning (ICL) datasets, we demonstrate that CoT and its reasoning variants consistently underperform direct answering across varying model scales and benchmark complexities. To systematically investigate this unexpected phenomenon, we designed extensive experiments to validate several hypothetical explanations. Our analysis uncovers a fundamental explicit-implicit duality driving CoT's performance in pattern-based ICL: while explicit reasoning falters due to LLMs' struggles to infer underlying patterns from demonstrations, implicit reasoning-disrupted by the increased contextual distance of CoT rationales-often compensates, delivering correct answers despite flawed rationales. This duality explains CoT's relative underperformance, as noise from weak explicit inference undermines the process, even as implicit mechanisms partially salvage outcomes. Notably, even long-CoT reasoning models, which excel in abstract and symbolic reasoning, fail to fully overcome these limitations despite higher computational costs. Our findings challenge existing assumptions regarding the universal efficacy of CoT, yielding novel insights into its limitations and guiding future research toward more nuanced and effective reasoning methodologies for LLMs.
ComparisonQA: Evaluating Factuality Robustness of LLMs Through Knowledge Frequency Control and Uncertainty
Dec 28, 2024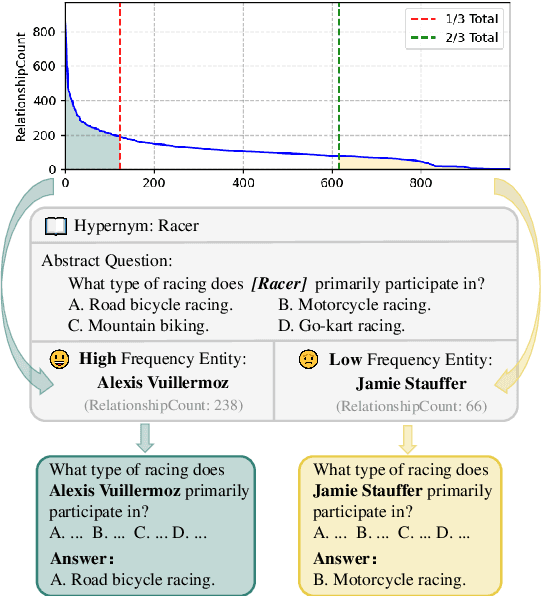
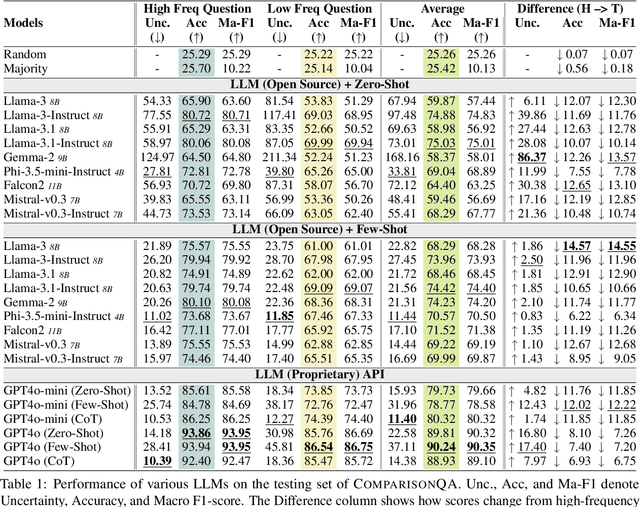
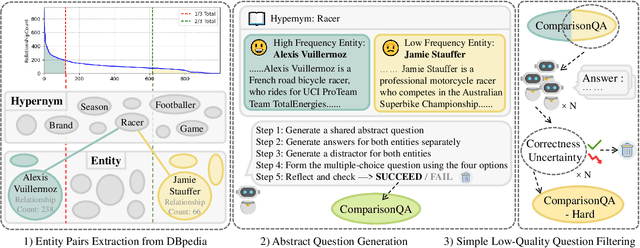
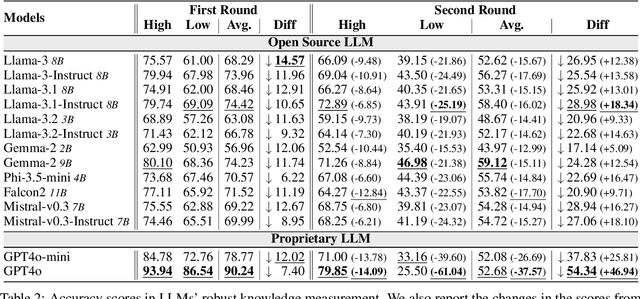
The rapid development of LLMs has sparked extensive research into their factual knowledge. Current works claim that LLMs fall short on questions requiring less frequent knowledge. However, their proof is incomplete since they only study the influence of entity frequency, which can not fully represent knowledge frequency. So we introduce ComparisonQA benchmark, containing 283K abstract questions, each instantiated by a pair of high-frequency and low-frequency entities. It ensures a controllable comparison because the difference of knowledge frequency between such a pair is only related to entity frequency. In addition, to avoid possible semantic shortcuts, which is a severe problem of current LLMs study, we design a two-round method for knowledge robustness measurement utilizing both correctness and uncertainty. Experiments reveal that LLMs exhibit particularly low robustness regarding low-frequency knowledge, and GPT-4o is even the worst under this measurement. Besides, we introduce an automatic method to filter out questions with low-quality and shortcuts to form ComparisonQA-Hard. We find that uncertainty effectively identifies such questions while maintaining the data size.
KNOWCOMP POKEMON Team at DialAM-2024: A Two-Stage Pipeline for Detecting Relations in Dialogical Argument Mining
Jul 29, 2024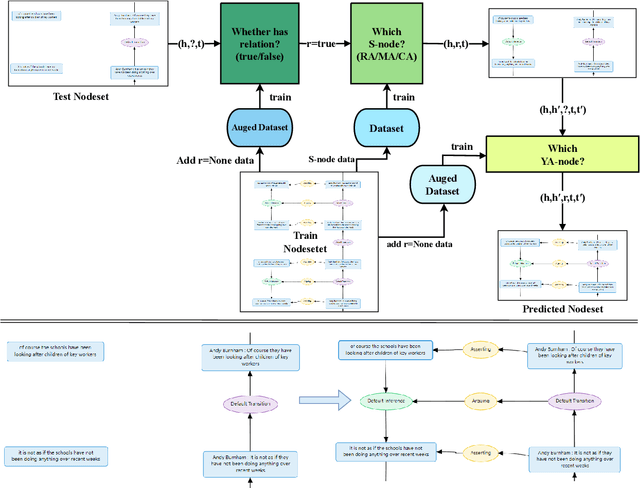
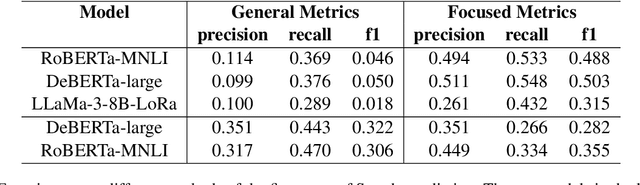
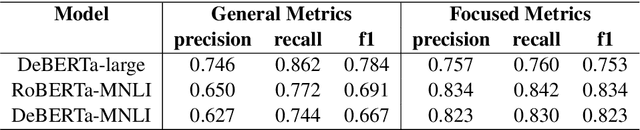

Dialogical Argument Mining(DialAM) is an important branch of Argument Mining(AM). DialAM-2024 is a shared task focusing on dialogical argument mining, which requires us to identify argumentative relations and illocutionary relations among proposition nodes and locution nodes. To accomplish this, we propose a two-stage pipeline, which includes the Two-Step S-Node Prediction Model in Stage 1 and the YA-Node Prediction Model in Stage 2. We also augment the training data in both stages and introduce context in Stage 2. We successfully completed the task and achieved good results. Our team Pokemon ranked 1st in the ARI Focused score and 4th in the Global Focused score.
AbsInstruct: Eliciting Abstraction Ability from LLMs through Explanation Tuning with Plausibility Estimation
Feb 16, 2024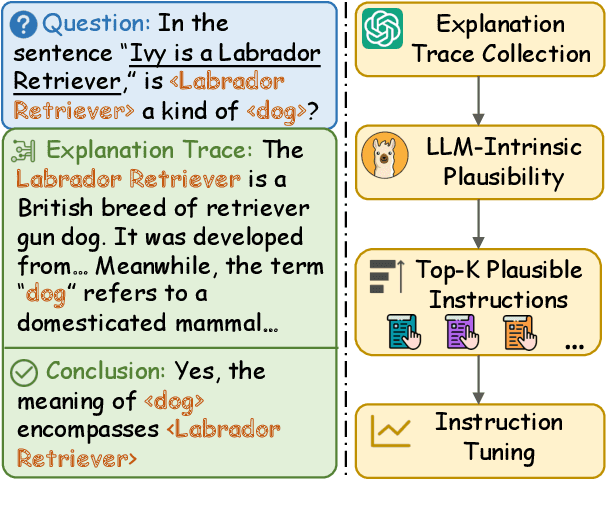

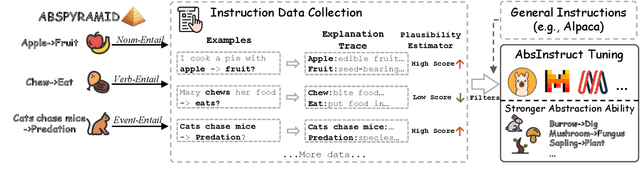
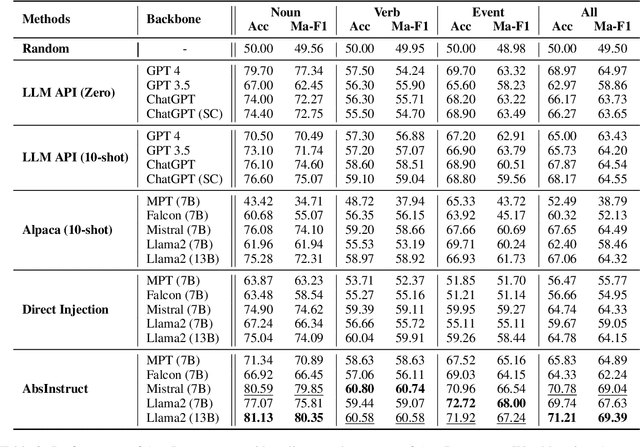
Abstraction ability is crucial in human intelligence, which can also benefit various tasks in NLP study. Existing work shows that LLMs are deficient in abstract ability, and how to improve it remains unexplored. In this work, we design the framework AbsInstruct to enhance LLMs' abstraction ability through instruction tuning. The framework builds instructions with in-depth explanations to assist LLMs in capturing the underlying rationale of abstraction. Meanwhile, we introduce a plausibility estimator to select instructions that are more consistent with the abstraction knowledge of LLMs to be aligned. Then, our framework combines abstraction instructions with general-purpose ones to build a hybrid dataset. Extensive experiments and analyses demonstrate that our framework can considerably enhance LLMs' abstraction ability with strong generalization performance while maintaining their general instruction-following abilities.
TILFA: A Unified Framework for Text, Image, and Layout Fusion in Argument Mining
Oct 08, 2023A main goal of Argument Mining (AM) is to analyze an author's stance. Unlike previous AM datasets focusing only on text, the shared task at the 10th Workshop on Argument Mining introduces a dataset including both text and images. Importantly, these images contain both visual elements and optical characters. Our new framework, TILFA (A Unified Framework for Text, Image, and Layout Fusion in Argument Mining), is designed to handle this mixed data. It excels at not only understanding text but also detecting optical characters and recognizing layout details in images. Our model significantly outperforms existing baselines, earning our team, KnowComp, the 1st place in the leaderboard of Argumentative Stance Classification subtask in this shared task.