 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeuralDB: Scaling Knowledge Editing in LLMs to 100,000 Facts with Neural KV Database
Jul 24, 2025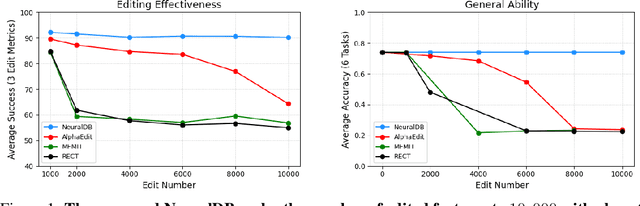
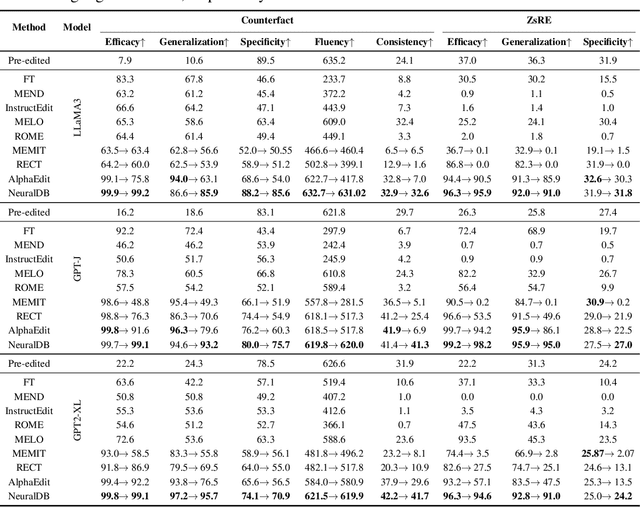
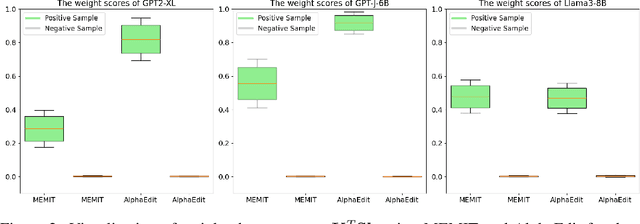

Efficiently editing knowledge stored in large language models (LLMs) enables model updates without large-scale training. One possible solution is Locate-and-Edit (L\&E), allowing simultaneous modifications of a massive number of facts. However, such editing may compromise the general abilities of LLMs and even result in forgetting edited facts when scaling up to thousands of edits. In this paper, we model existing linear L\&E methods as querying a Key-Value (KV) database. From this perspective, we then propose NeuralDB, an editing framework that explicitly represents the edited facts as a neural KV database equipped with a non-linear gated retrieval module, % In particular, our gated module only operates when inference involves the edited facts, effectively preserving the general abilities of LLMs. Comprehensive experiments involving the editing of 10,000 facts were conducted on the ZsRE and CounterFacts datasets, using GPT2-XL, GPT-J (6B) and Llama-3 (8B). The results demonstrate that NeuralDB not only excels in editing efficacy, generalization, specificity, fluency, and consistency, but also preserves overall performance across six representative text understanding and generation tasks. Further experiments indicate that NeuralDB maintains its effectiveness even when scaled to 100,000 facts (\textbf{50x} more than in prior work).
Efficient and Scalable Neural Symbolic Search for Knowledge Graph Complex Query Answering
May 13, 2025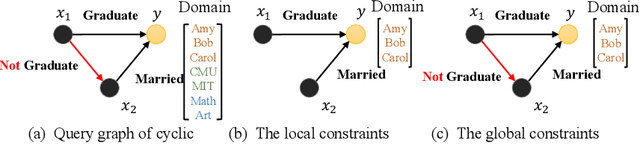
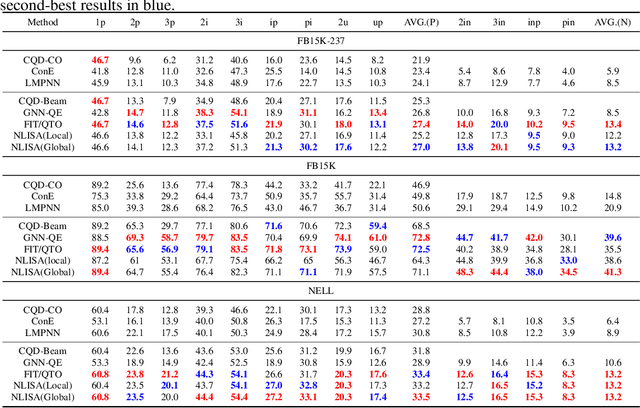


Complex Query Answering (CQA) aims to retrieve answer sets for complex logical formulas from incomplete knowledge graphs, which is a crucial yet challenging task in knowledge graph reasoning. While neuro-symbolic search utilized neural link predictions achieve superior accuracy, they encounter significant complexity bottlenecks: (i) Data complexity typically scales quadratically with the number of entities in the knowledge graph, and (ii) Query complexity becomes NP-hard for cyclic queries. Consequently, these approaches struggle to effectively scale to larger knowledge graphs and more complex queries. To address these challenges, we propose an efficient and scalable symbolic search framework. First, we propose two constraint strategies to compute neural logical indices to reduce the domain of variables, thereby decreasing the data complexity of symbolic search. Additionally, we introduce an approximate algorithm based on local search to tackle the NP query complexity of cyclic queries. Experiments on various CQA benchmarks demonstrate that our framework reduces the computational load of symbolic methods by 90\% while maintaining nearly the same performance, thus alleviating both efficiency and scalability issues.
Top Ten Challenges Towards Agentic Neural Graph Databases
Jan 24, 2025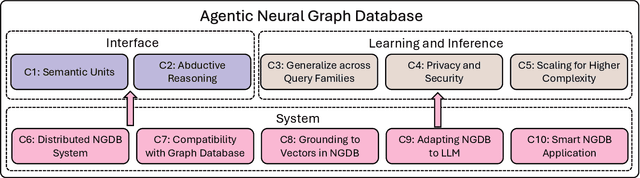
Graph databases (GDBs) like Neo4j and TigerGraph excel at handling interconnected data but lack advanced inference capabilities. Neural Graph Databases (NGDBs) address this by integrating Graph Neural Networks (GNNs) for predictive analysis and reasoning over incomplete or noisy data. However, NGDBs rely on predefined queries and lack autonomy and adaptability. This paper introduces Agentic Neural Graph Databases (Agentic NGDBs), which extend NGDBs with three core functionalities: autonomous query construction, neural query execution, and continuous learning. We identify ten key challenges in realizing Agentic NGDBs: semantic unit representation, abductive reasoning, scalable query execution, and integration with foundation models like large language models (LLMs). By addressing these challenges, Agentic NGDBs can enable intelligent, self-improving systems for modern data-driven applications, paving the way for adaptable and autonomous data management solutions.
Retrieval Meets Reasoning: Dynamic In-Context Editing for Long-Text Understanding
Jun 18, 2024



Current Large Language Models (LLMs) face inherent limitations due to their pre-defined context lengths, which impede their capacity for multi-hop reasoning within extensive textual contexts. While existing techniques like Retrieval-Augmented Generation (RAG) have attempted to bridge this gap by sourcing external information, they fall short when direct answers are not readily available. We introduce a novel approach that re-imagines information retrieval through dynamic in-context editing, inspired by recent breakthroughs in knowledge editing. By treating lengthy contexts as malleable external knowledge, our method interactively gathers and integrates relevant information, thereby enabling LLMs to perform sophisticated reasoning steps. Experimental results demonstrate that our method effectively empowers context-limited LLMs, such as Llama2, to engage in multi-hop reasoning with improved performance, which outperforms state-of-the-art context window extrapolation methods and even compares favorably to more advanced commercial long-context models. Our interactive method not only enhances reasoning capabilities but also mitigates the associated training and computational costs, making it a pragmatic solution for enhancing LLMs' reasoning within expansive contexts.
Soft Reasoning on Uncertain Knowledge Graphs
Mar 03, 2024The study of machine learning-based logical query-answering enables reasoning with large-scale and incomplete knowledge graphs. This paper further advances this line of research by considering the uncertainty in the knowledge. The uncertain nature of knowledge is widely observed in the real world, but \textit{does not} align seamlessly with the first-order logic underpinning existing studies. To bridge this gap, we study the setting of soft queries on uncertain knowledge, which is motivated by the establishment of soft constraint programming. We further propose an ML-based approach with both forward inference and backward calibration to answer soft queries on large-scale, incomplete, and uncertain knowledge graphs. Theoretical discussions present that our methods share the same complexity as state-of-the-art inference algorithms for first-order queries. Empirical results justify the superior performance of our approach against previous ML-based methods with number embedding extensions.
Extending Context Window of Large Language Models via Semantic Compression
Dec 15, 2023
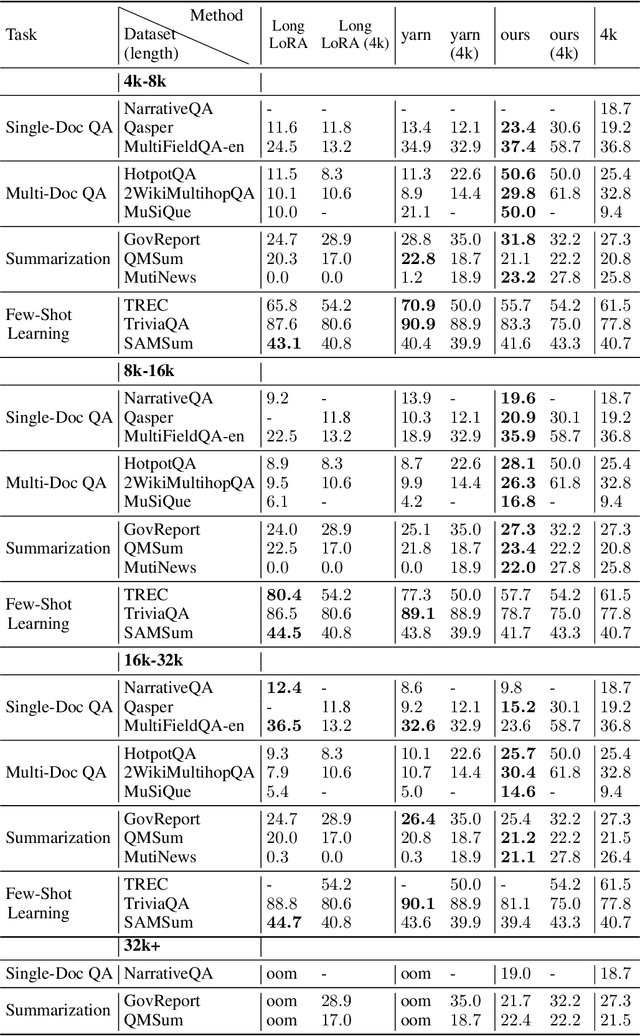
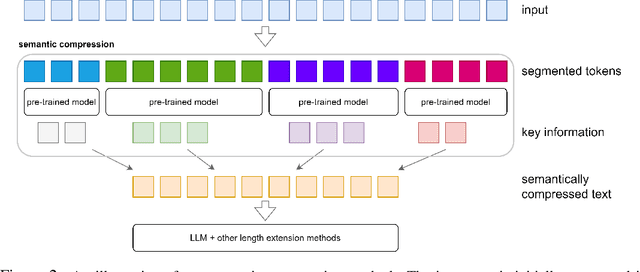
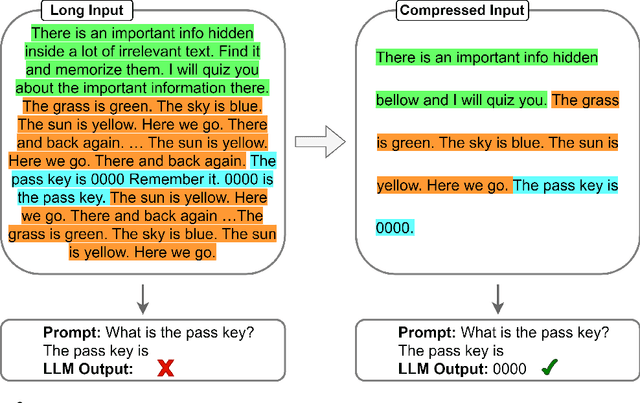
Transformer-based Large Language Models (LLMs) often impose limitations on the length of the text input to ensure the generation of fluent and relevant responses. This constraint restricts their applicability in scenarios involving long texts. We propose a novel semantic compression method that enables generalization to texts that are 6-8 times longer, without incurring significant computational costs or requiring fine-tuning. Our proposed framework draws inspiration from source coding in information theory and employs a pre-trained model to reduce the semantic redundancy of long inputs before passing them to the LLMs for downstream tasks. Experimental results demonstrate that our method effectively extends the context window of LLMs across a range of tasks including question answering, summarization, few-shot learning, and information retrieval. Furthermore, the proposed semantic compression method exhibits consistent fluency in text generation while reducing the associated computational overhead.
$\text{EFO}_{k}$-CQA: Towards Knowledge Graph Complex Query Answering beyond Set Operation
Jul 15, 2023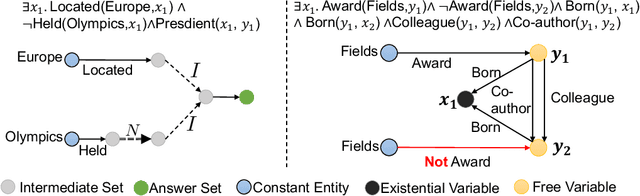
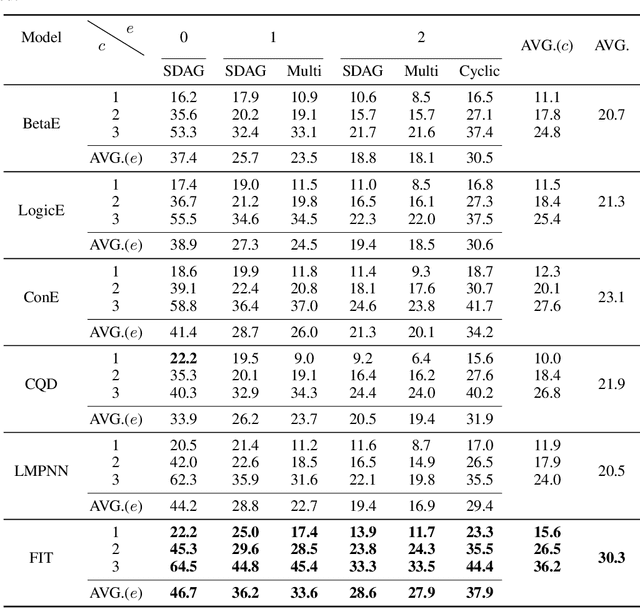
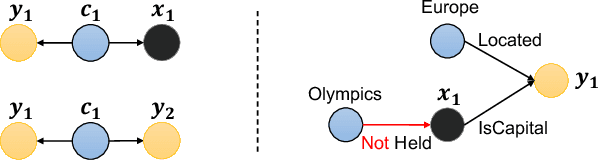
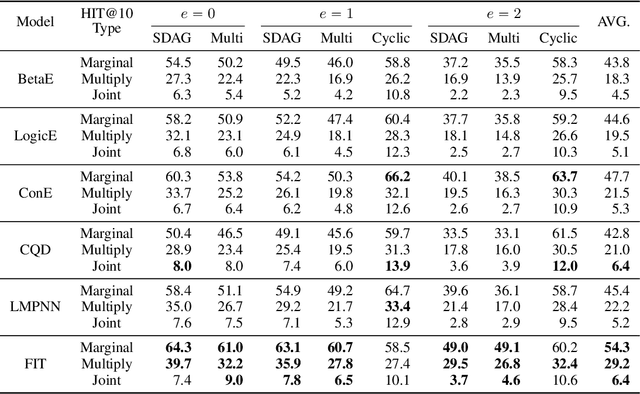
To answer complex queries on knowledge graphs, logical reasoning over incomplete knowledge is required due to the open-world assumption. Learning-based methods are essential because they are capable of generalizing over unobserved knowledge. Therefore, an appropriate dataset is fundamental to both obtaining and evaluating such methods under this paradigm. In this paper, we propose a comprehensive framework for data generation, model training, and method evaluation that covers the combinatorial space of Existential First-order Queries with multiple variables ($\text{EFO}_{k}$). The combinatorial query space in our framework significantly extends those defined by set operations in the existing literature. Additionally, we construct a dataset, $\text{EFO}_{k}$-CQA, with 741 types of query for empirical evaluation, and our benchmark results provide new insights into how query hardness affects the results. Furthermore, we demonstrate that the existing dataset construction process is systematically biased that hinders the appropriate development of query-answering methods, highlighting the importance of our work. Our code and data are provided in~\url{https://github.com/HKUST-KnowComp/EFOK-CQA}.
Wasserstein-Fisher-Rao Embedding: Logical Query Embeddings with Local Comparison and Global Transport
May 06, 2023
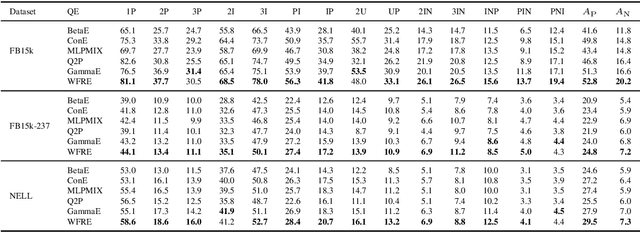
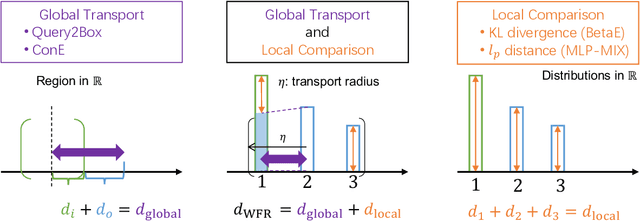

Answering complex queries on knowledge graphs is important but particularly challenging because of the data incompleteness. Query embedding methods address this issue by learning-based models and simulating logical reasoning with set operators. Previous works focus on specific forms of embeddings, but scoring functions between embeddings are underexplored. In contrast to existing scoring functions motivated by local comparison or global transport, this work investigates the local and global trade-off with unbalanced optimal transport theory. Specifically, we embed sets as bounded measures in $\real$ endowed with a scoring function motivated by the Wasserstein-Fisher-Rao metric. Such a design also facilitates closed-form set operators in the embedding space. Moreover, we introduce a convolution-based algorithm for linear time computation and a block-diagonal kernel to enforce the trade-off. Results show that WFRE can outperform existing query embedding methods on standard datasets, evaluation sets with combinatorially complex queries, and hierarchical knowledge graphs. Ablation study shows that finding a better local and global trade-off is essential for performance improvement.