 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChLogic: Evaluating Robustness of Logical Reasoning in Chinese Expressions
Jun 16, 2026Large language models perform increasingly well on standardized logical reasoning benchmarks, but whether this ability remains robust beyond English is unclear. We introduce ChLogic, an English--Chinese aligned benchmark that tests whether models preserve logical reasoning performance when the same latent logical structure is expressed in English and diverse Chinese surface realizations. Built from formal logical templates, the benchmark contains three data sets: (i) the General aligned set, derived from 60 General Propositions across nine template families; (ii) the Difficult aligned set, derived from 40 Difficult Problems; and (iii) the Chinese-only set, covering 15 language-specific phenomenon types. Each aligned item pairs one English reference expression with five Chinese realizations. Experiments on Qwen3, Ministral, and GLM models reveal a persistent English--Chinese performance gap. Back-translation from standard Chinese into English often improves performance on the General aligned set, but produces mixed effects on the Difficult aligned set, where Qwen3-32B and GLM-5.1 perform worse after translation. These results indicate that Chinese surface realization, translation artifacts, and model-specific behavior jointly affect multilingual logical reasoning. Overall, ChLogic provides a useful stress test for the robustness of multilingual reasoning.
On the Non-decoupling of Supervised Fine-tuning and Reinforcement Learning in Post-training
Jan 12, 2026Post-training of large language models routinely interleaves supervised fine-tuning (SFT) with reinforcement learning (RL). These two methods have different objectives: SFT minimizes the cross-entropy loss between model outputs and expert responses, while RL maximizes reward signals derived from human preferences or rule-based verifiers. Modern reasoning models have widely adopted the practice of alternating SFT and RL training. However, there is no theoretical account of whether they can be decoupled. We prove that decoupling is impossible in either order: (1) SFT-then-RL coupling: RL increases SFT loss under SFT optimality and (2) RL-then-SFT coupling: SFT lowers the reward achieved by RL. Experiments on Qwen3-0.6B confirm the predicted degradation, verifying that SFT and RL cannot be separated without loss of prior performance in the post-training
NeuralDB: Scaling Knowledge Editing in LLMs to 100,000 Facts with Neural KV Database
Jul 24, 2025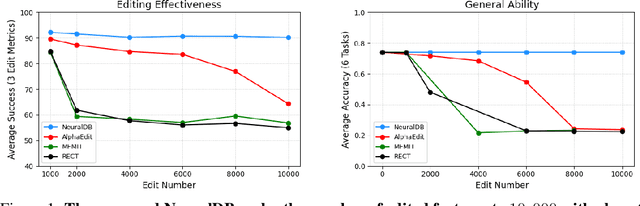
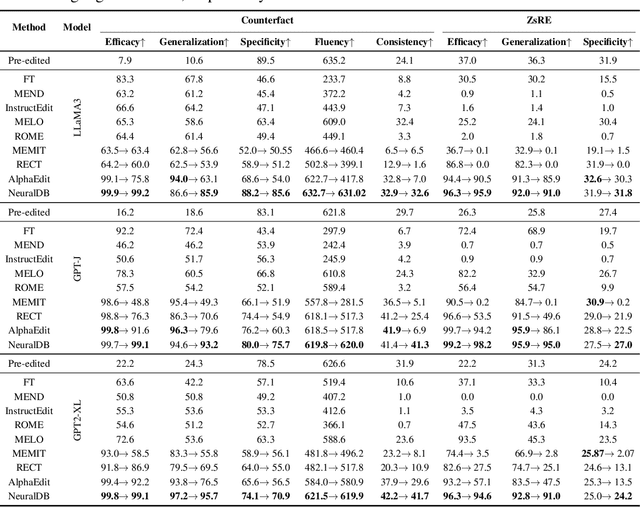
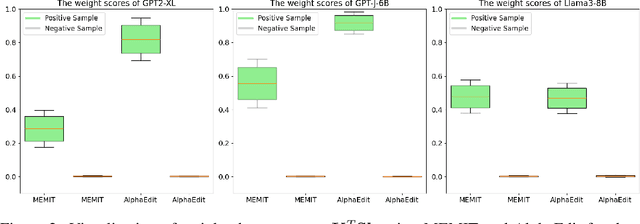

Efficiently editing knowledge stored in large language models (LLMs) enables model updates without large-scale training. One possible solution is Locate-and-Edit (L\&E), allowing simultaneous modifications of a massive number of facts. However, such editing may compromise the general abilities of LLMs and even result in forgetting edited facts when scaling up to thousands of edits. In this paper, we model existing linear L\&E methods as querying a Key-Value (KV) database. From this perspective, we then propose NeuralDB, an editing framework that explicitly represents the edited facts as a neural KV database equipped with a non-linear gated retrieval module, % In particular, our gated module only operates when inference involves the edited facts, effectively preserving the general abilities of LLMs. Comprehensive experiments involving the editing of 10,000 facts were conducted on the ZsRE and CounterFacts datasets, using GPT2-XL, GPT-J (6B) and Llama-3 (8B). The results demonstrate that NeuralDB not only excels in editing efficacy, generalization, specificity, fluency, and consistency, but also preserves overall performance across six representative text understanding and generation tasks. Further experiments indicate that NeuralDB maintains its effectiveness even when scaled to 100,000 facts (\textbf{50x} more than in prior work).
Learning predictable and robust neural representations by straightening image sequences
Nov 04, 2024Prediction is a fundamental capability of all living organisms, and has been proposed as an objective for learning sensory representations. Recent work demonstrates that in primate visual systems, prediction is facilitated by neural representations that follow straighter temporal trajectories than their initial photoreceptor encoding, which allows for prediction by linear extrapolation. Inspired by these experimental findings, we develop a self-supervised learning (SSL) objective that explicitly quantifies and promotes straightening. We demonstrate the power of this objective in training deep feedforward neural networks on smoothly-rendered synthetic image sequences that mimic commonly-occurring properties of natural videos. The learned model contains neural embeddings that are predictive, but also factorize the geometric, photometric, and semantic attributes of objects. The representations also prove more robust to noise and adversarial attacks compared to previous SSL methods that optimize for invariance to random augmentations. Moreover, these beneficial properties can be transferred to other training procedures by using the straightening objective as a regularizer, suggesting a broader utility for straightening as a principle for robust unsupervised learning.
Retrieval Meets Reasoning: Dynamic In-Context Editing for Long-Text Understanding
Jun 18, 2024



Current Large Language Models (LLMs) face inherent limitations due to their pre-defined context lengths, which impede their capacity for multi-hop reasoning within extensive textual contexts. While existing techniques like Retrieval-Augmented Generation (RAG) have attempted to bridge this gap by sourcing external information, they fall short when direct answers are not readily available. We introduce a novel approach that re-imagines information retrieval through dynamic in-context editing, inspired by recent breakthroughs in knowledge editing. By treating lengthy contexts as malleable external knowledge, our method interactively gathers and integrates relevant information, thereby enabling LLMs to perform sophisticated reasoning steps. Experimental results demonstrate that our method effectively empowers context-limited LLMs, such as Llama2, to engage in multi-hop reasoning with improved performance, which outperforms state-of-the-art context window extrapolation methods and even compares favorably to more advanced commercial long-context models. Our interactive method not only enhances reasoning capabilities but also mitigates the associated training and computational costs, making it a pragmatic solution for enhancing LLMs' reasoning within expansive contexts.
Beyond Scaling Laws: Understanding Transformer Performance with Associative Memory
May 14, 2024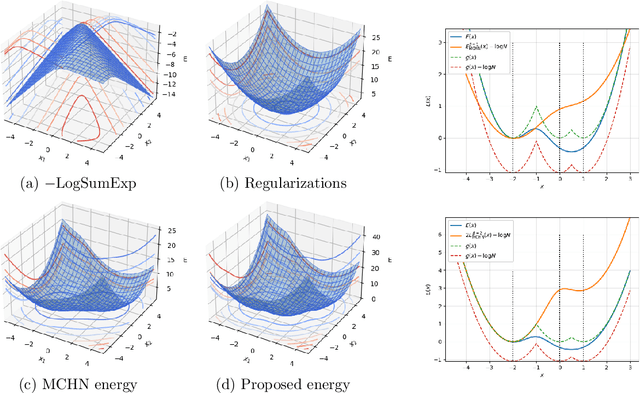

Increasing the size of a Transformer model does not always lead to enhanced performance. This phenomenon cannot be explained by the empirical scaling laws. Furthermore, improved generalization ability occurs as the model memorizes the training samples. We present a theoretical framework that sheds light on the memorization process and performance dynamics of transformer-based language models. We model the behavior of Transformers with associative memories using Hopfield networks, such that each transformer block effectively conducts an approximate nearest-neighbor search. Based on this, we design an energy function analogous to that in the modern continuous Hopfield network which provides an insightful explanation for the attention mechanism. Using the majorization-minimization technique, we construct a global energy function that captures the layered architecture of the Transformer. Under specific conditions, we show that the minimum achievable cross-entropy loss is bounded from below by a constant approximately equal to 1. We substantiate our theoretical results by conducting experiments with GPT-2 on various data sizes, as well as training vanilla Transformers on a dataset of 2M tokens.
Extreme Video Compression with Pre-trained Diffusion Models
Feb 14, 2024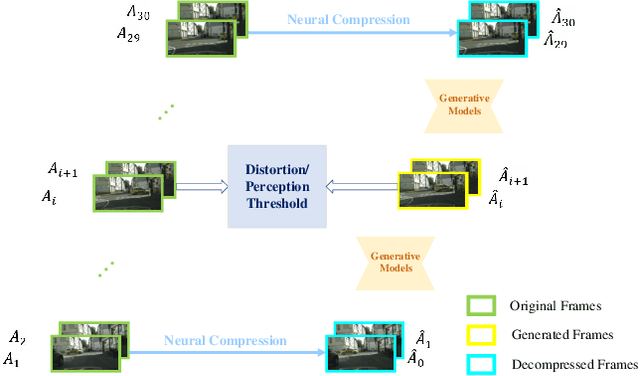
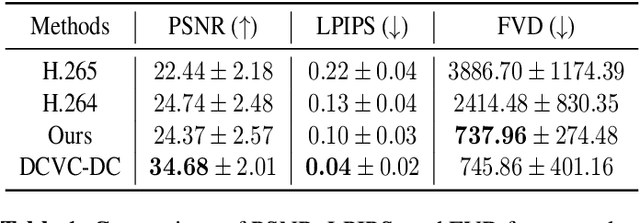
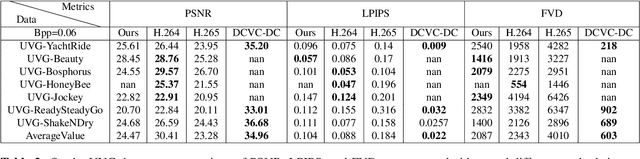
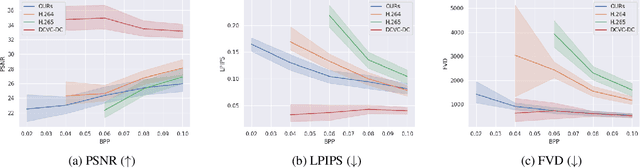
Diffusion models have achieved remarkable success in generating high quality image and video data. More recently, they have also been used for image compression with high perceptual quality. In this paper, we present a novel approach to extreme video compression leveraging the predictive power of diffusion-based generative models at the decoder. The conditional diffusion model takes several neural compressed frames and generates subsequent frames. When the reconstruction quality drops below the desired level, new frames are encoded to restart prediction. The entire video is sequentially encoded to achieve a visually pleasing reconstruction, considering perceptual quality metrics such as the learned perceptual image patch similarity (LPIPS) and the Frechet video distance (FVD), at bit rates as low as 0.02 bits per pixel (bpp). Experimental results demonstrate the effectiveness of the proposed scheme compared to standard codecs such as H.264 and H.265 in the low bpp regime. The results showcase the potential of exploiting the temporal relations in video data using generative models. Code is available at: https://github.com/ElesionKyrie/Extreme-Video-Compression-With-Prediction-Using-Pre-trainded-Diffusion-Models-
Extending Context Window of Large Language Models via Semantic Compression
Dec 15, 2023
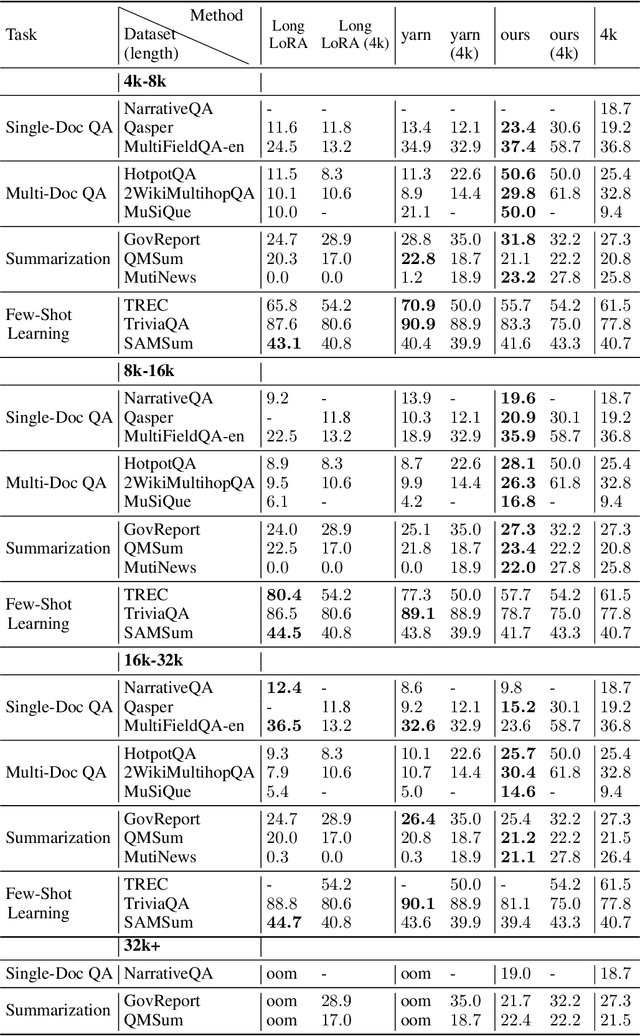
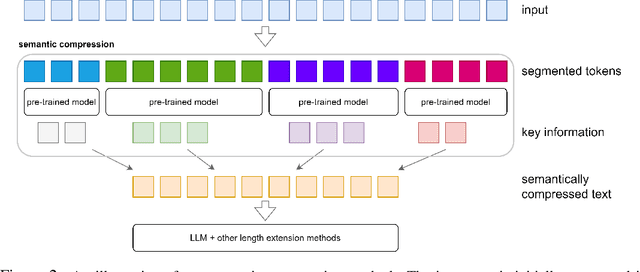
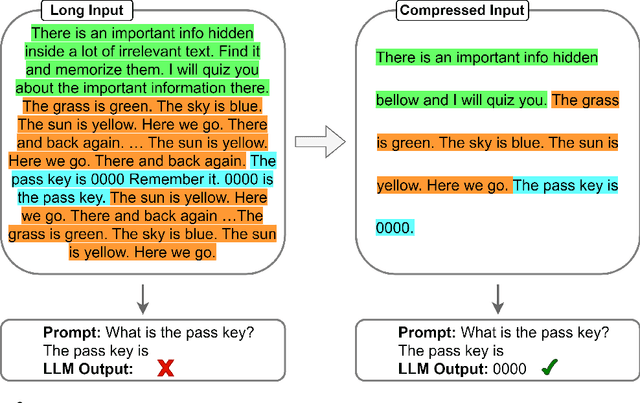
Transformer-based Large Language Models (LLMs) often impose limitations on the length of the text input to ensure the generation of fluent and relevant responses. This constraint restricts their applicability in scenarios involving long texts. We propose a novel semantic compression method that enables generalization to texts that are 6-8 times longer, without incurring significant computational costs or requiring fine-tuning. Our proposed framework draws inspiration from source coding in information theory and employs a pre-trained model to reduce the semantic redundancy of long inputs before passing them to the LLMs for downstream tasks. Experimental results demonstrate that our method effectively extends the context window of LLMs across a range of tasks including question answering, summarization, few-shot learning, and information retrieval. Furthermore, the proposed semantic compression method exhibits consistent fluency in text generation while reducing the associated computational overhead.
High Perceptual Quality Wireless Image Delivery with Denoising Diffusion Models
Sep 27, 2023

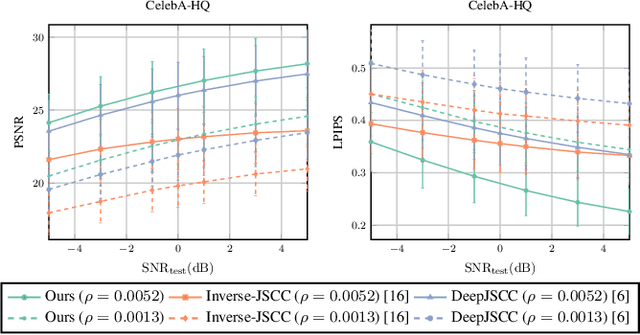

We consider the image transmission problem over a noisy wireless channel via deep learning-based joint source-channel coding (DeepJSCC) along with a denoising diffusion probabilistic model (DDPM) at the receiver. Specifically, we are interested in the perception-distortion trade-off in the practical finite block length regime, in which separate source and channel coding can be highly suboptimal. We introduce a novel scheme that utilizes the range-null space decomposition of the target image. We transmit the range-space of the image after encoding and employ DDPM to progressively refine its null space contents. Through extensive experiments, we demonstrate significant improvements in distortion and perceptual quality of reconstructed images compared to standard DeepJSCC and the state-of-the-art generative learning-based method. We will publicly share our source code to facilitate further research and reproducibility.
A Hybrid Wireless Image Transmission Scheme with Diffusion
Aug 16, 2023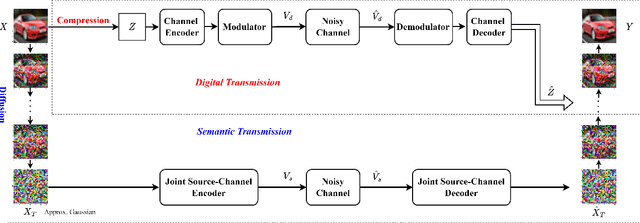
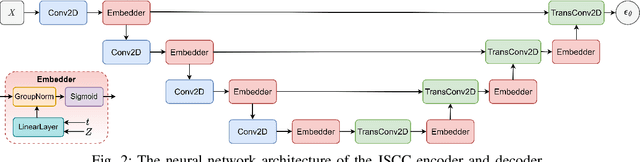

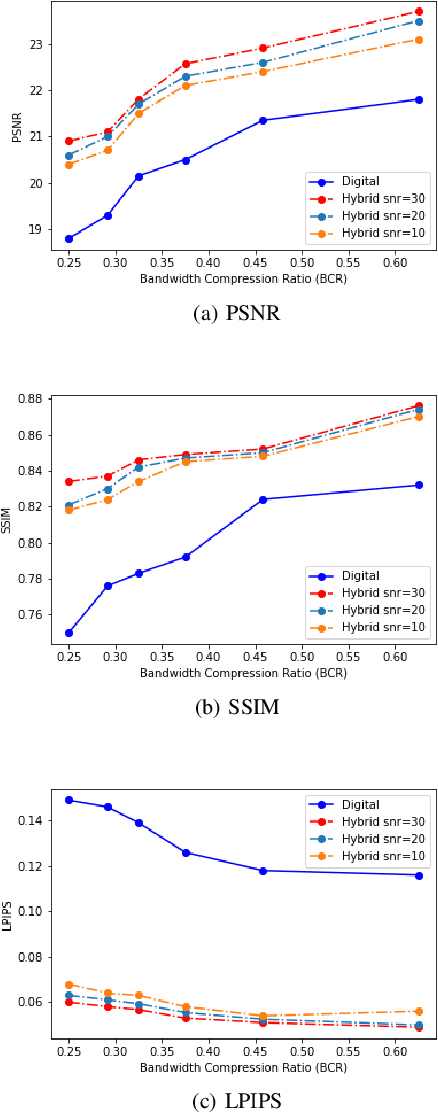
We propose a hybrid joint source-channel coding (JSCC) scheme, in which the conventional digital communication scheme is complemented with a generative refinement component to improve the perceptual quality of the reconstruction. The input image is decomposed into two components: the first is a coarse compressed version, and is transmitted following the conventional separation based approach. An additional component is obtained through the diffusion process by adding independent Gaussian noise to the input image, and is transmitted using DeepJSCC. The decoder combines the two signals to produce a high quality reconstruction of the source. Experimental results show that the hybrid design provides bandwidth savings and enables graceful performance improvement as the channel quality improves.