 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExtreme Video Compression with Pre-trained Diffusion Models
Paper and Code
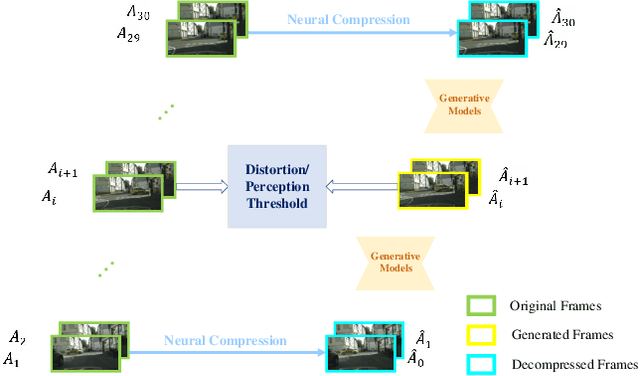
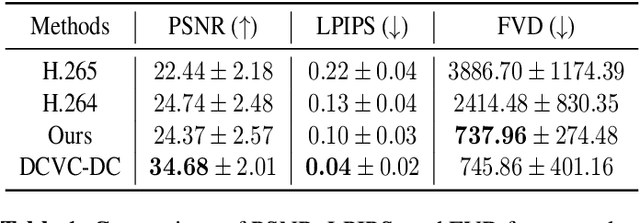
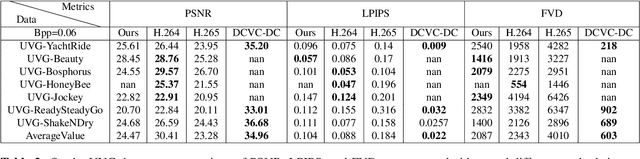
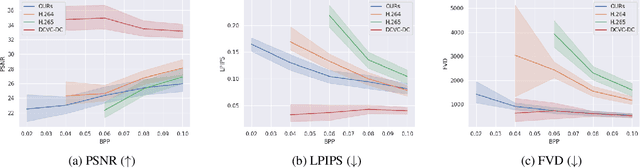
Diffusion models have achieved remarkable success in generating high quality image and video data. More recently, they have also been used for image compression with high perceptual quality. In this paper, we present a novel approach to extreme video compression leveraging the predictive power of diffusion-based generative models at the decoder. The conditional diffusion model takes several neural compressed frames and generates subsequent frames. When the reconstruction quality drops below the desired level, new frames are encoded to restart prediction. The entire video is sequentially encoded to achieve a visually pleasing reconstruction, considering perceptual quality metrics such as the learned perceptual image patch similarity (LPIPS) and the Frechet video distance (FVD), at bit rates as low as 0.02 bits per pixel (bpp). Experimental results demonstrate the effectiveness of the proposed scheme compared to standard codecs such as H.264 and H.265 in the low bpp regime. The results showcase the potential of exploiting the temporal relations in video data using generative models. Code is available at: https://github.com/ElesionKyrie/Extreme-Video-Compression-With-Prediction-Using-Pre-trainded-Diffusion-Models-