 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDisentangled representations via score-based variational autoencoders
Dec 18, 2025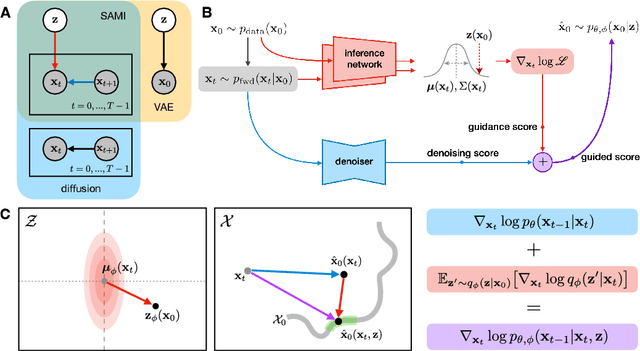
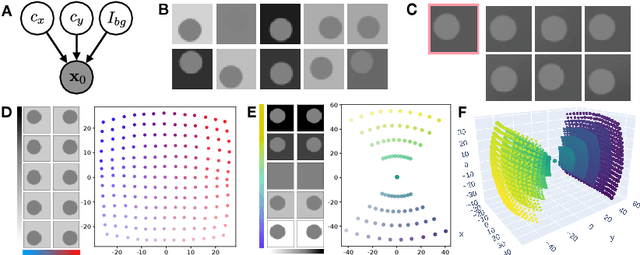
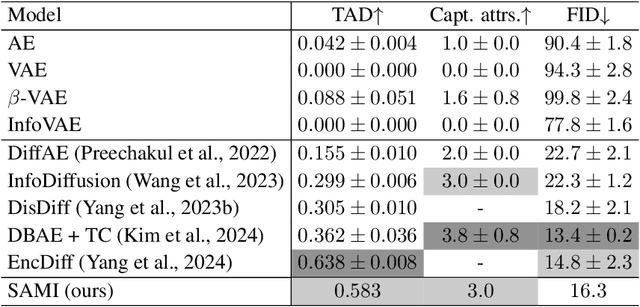
We present the Score-based Autoencoder for Multiscale Inference (SAMI), a method for unsupervised representation learning that combines the theoretical frameworks of diffusion models and VAEs. By unifying their respective evidence lower bounds, SAMI formulates a principled objective that learns representations through score-based guidance of the underlying diffusion process. The resulting representations automatically capture meaningful structure in the data: it recovers ground truth generative factors in our synthetic dataset, learns factorized, semantic latent dimensions from complex natural images, and encodes video sequences into latent trajectories that are straighter than those of alternative encoders, despite training exclusively on static images. Furthermore, SAMI can extract useful representations from pre-trained diffusion models with minimal additional training. Finally, the explicitly probabilistic formulation provides new ways to identify semantically meaningful axes in the absence of supervised labels, and its mathematical exactness allows us to make formal statements about the nature of the learned representation. Overall, these results indicate that implicit structural information in diffusion models can be made explicit and interpretable through synergistic combination with a variational autoencoder.
Learning predictable and robust neural representations by straightening image sequences
Nov 04, 2024Prediction is a fundamental capability of all living organisms, and has been proposed as an objective for learning sensory representations. Recent work demonstrates that in primate visual systems, prediction is facilitated by neural representations that follow straighter temporal trajectories than their initial photoreceptor encoding, which allows for prediction by linear extrapolation. Inspired by these experimental findings, we develop a self-supervised learning (SSL) objective that explicitly quantifies and promotes straightening. We demonstrate the power of this objective in training deep feedforward neural networks on smoothly-rendered synthetic image sequences that mimic commonly-occurring properties of natural videos. The learned model contains neural embeddings that are predictive, but also factorize the geometric, photometric, and semantic attributes of objects. The representations also prove more robust to noise and adversarial attacks compared to previous SSL methods that optimize for invariance to random augmentations. Moreover, these beneficial properties can be transferred to other training procedures by using the straightening objective as a regularizer, suggesting a broader utility for straightening as a principle for robust unsupervised learning.
How does the brain compute with probabilities?
Sep 01, 2024



This perspective piece is the result of a Generative Adversarial Collaboration (GAC) tackling the question `How does neural activity represent probability distributions?'. We have addressed three major obstacles to progress on answering this question: first, we provide a unified language for defining competing hypotheses. Second, we explain the fundamentals of three prominent proposals for probabilistic computations -- Probabilistic Population Codes (PPCs), Distributed Distributional Codes (DDCs), and Neural Sampling Codes (NSCs) -- and describe similarities and differences in that common language. Third, we review key empirical data previously taken as evidence for at least one of these proposal, and describe how it may or may not be explainable by alternative proposals. Finally, we describe some key challenges in resolving the debate, and propose potential directions to address them through a combination of theory and experiments.
Task adaption by biologically inspired stochastic comodulation
Nov 25, 2023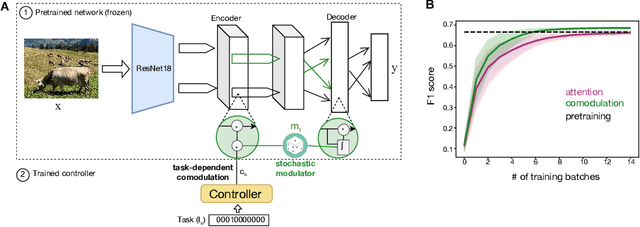
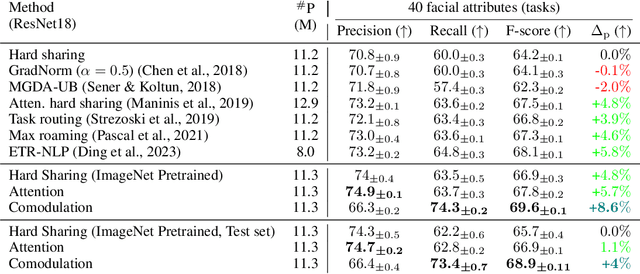
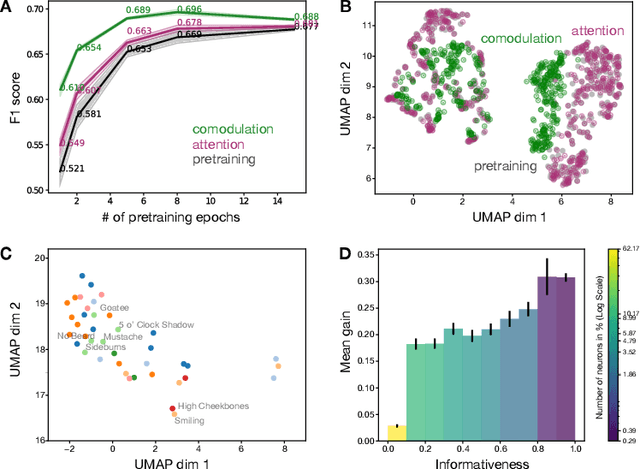
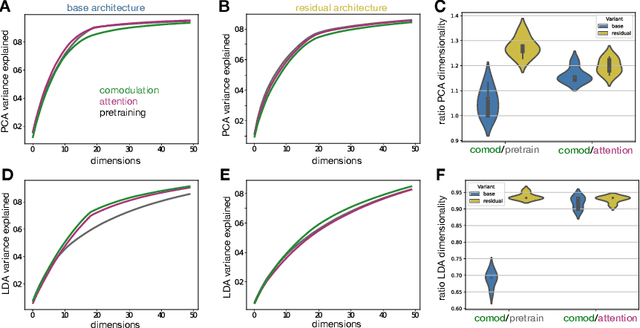
Brain representations must strike a balance between generalizability and adaptability. Neural codes capture general statistical regularities in the world, while dynamically adjusting to reflect current goals. One aspect of this adaptation is stochastically co-modulating neurons' gains based on their task relevance. These fluctuations then propagate downstream to guide decision-making. Here, we test the computational viability of such a scheme in the context of multi-task learning. We show that fine-tuning convolutional networks by stochastic gain modulation improves on deterministic gain modulation, achieving state-of-the-art results on the CelebA dataset. To better understand the mechanisms supporting this improvement, we explore how fine-tuning performance is affected by architecture using Cifar-100. Overall, our results suggest that stochastic comodulation can enhance learning efficiency and performance in multi-task learning, without additional learnable parameters. This offers a promising new direction for developing more flexible and robust intelligent systems.
Toward Next-Generation Artificial Intelligence: Catalyzing the NeuroAI Revolution
Oct 15, 2022Neuroscience has long been an important driver of progress in artificial intelligence (AI). We propose that to accelerate progress in AI, we must invest in fundamental research in NeuroAI.
CCN GAC Workshop: Issues with learning in biological recurrent neural networks
May 12, 2021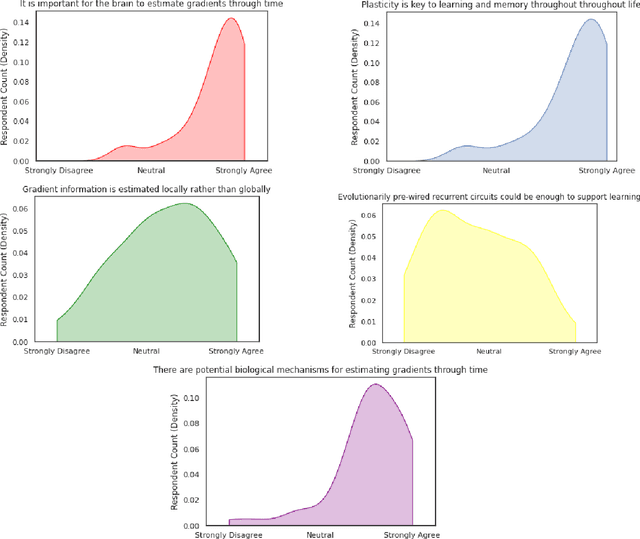
This perspective piece came about through the Generative Adversarial Collaboration (GAC) series of workshops organized by the Computational Cognitive Neuroscience (CCN) conference in 2020. We brought together a number of experts from the field of theoretical neuroscience to debate emerging issues in our understanding of how learning is implemented in biological recurrent neural networks. Here, we will give a brief review of the common assumptions about biological learning and the corresponding findings from experimental neuroscience and contrast them with the efficiency of gradient-based learning in recurrent neural networks commonly used in artificial intelligence. We will then outline the key issues discussed in the workshop: synaptic plasticity, neural circuits, theory-experiment divide, and objective functions. Finally, we conclude with recommendations for both theoretical and experimental neuroscientists when designing new studies that could help to bring clarity to these issues.
Online hyperparameter optimization by real-time recurrent learning
Feb 15, 2021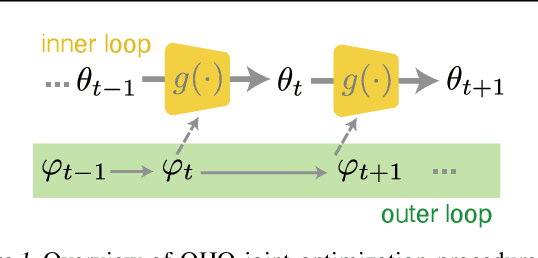
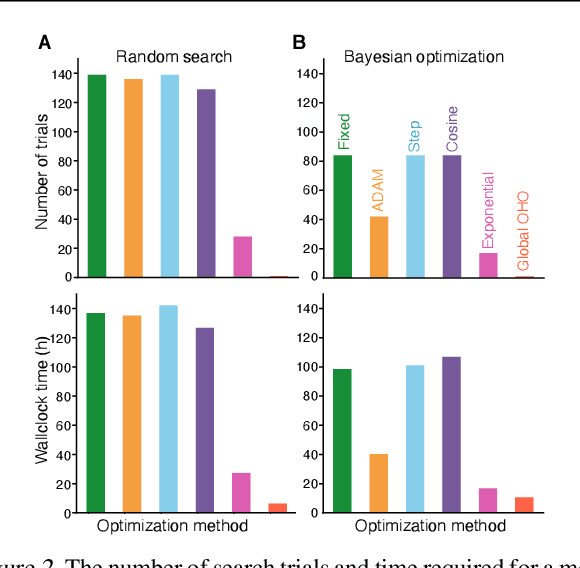
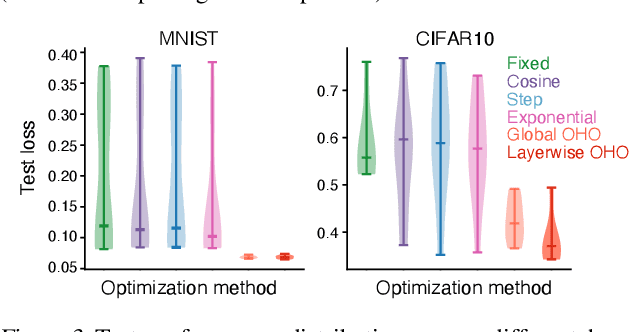
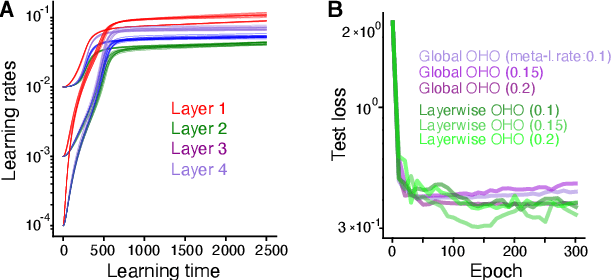
Conventional hyperparameter optimization methods are computationally intensive and hard to generalize to scenarios that require dynamically adapting hyperparameters, such as life-long learning. Here, we propose an online hyperparameter optimization algorithm that is asymptotically exact and computationally tractable, both theoretically and practically. Our framework takes advantage of the analogy between hyperparameter optimization and parameter learning in recurrent neural networks (RNNs). It adapts a well-studied family of online learning algorithms for RNNs to tune hyperparameters and network parameters simultaneously, without repeatedly rolling out iterative optimization. This procedure yields systematically better generalization performance compared to standard methods, at a fraction of wallclock time.
A Unified Framework of Online Learning Algorithms for Training Recurrent Neural Networks
Jul 05, 2019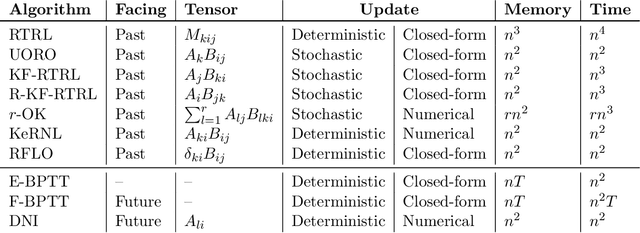
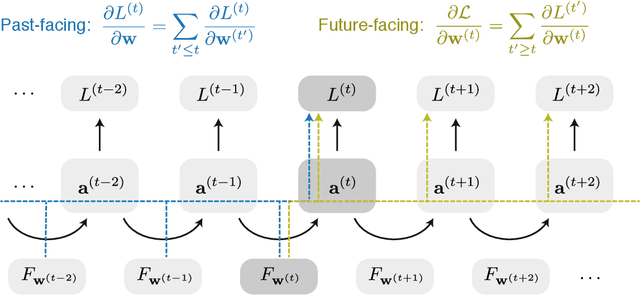
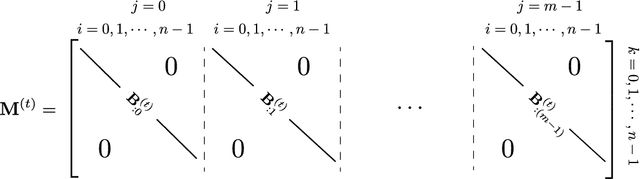
We present a framework for compactly summarizing many recent results in efficient and/or biologically plausible online training of recurrent neural networks (RNN). The framework organizes algorithms according to several criteria: (a) past vs. future facing, (b) tensor structure, (c) stochastic vs. deterministic, and (d) closed form vs. numerical. These axes reveal latent conceptual connections among several recent advances in online learning. Furthermore, we provide novel mathematical intuitions for their degree of success. Testing various algorithms on two synthetic tasks shows that performances cluster according to our criteria. Although a similar clustering is also observed for gradient alignment, alignment with exact methods does not alone explain ultimate performance, especially for stochastic algorithms. This suggests the need for better comparison metrics.
Using local plasticity rules to train recurrent neural networks
May 28, 2019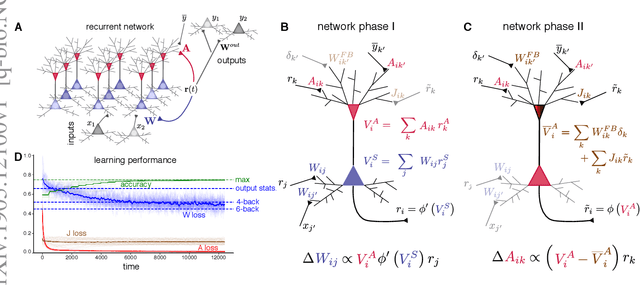
To learn useful dynamics on long time scales, neurons must use plasticity rules that account for long-term, circuit-wide effects of synaptic changes. In other words, neural circuits must solve a credit assignment problem to appropriately assign responsibility for global network behavior to individual circuit components. Furthermore, biological constraints demand that plasticity rules are spatially and temporally local; that is, synaptic changes can depend only on variables accessible to the pre- and postsynaptic neurons. While artificial intelligence offers a computational solution for credit assignment, namely backpropagation through time (BPTT), this solution is wildly biologically implausible. It requires both nonlocal computations and unlimited memory capacity, as any synaptic change is a complicated function of the entire history of network activity. Similar nonlocality issues plague other approaches such as FORCE (Sussillo et al. 2009). Overall, we are still missing a model for learning in recurrent circuits that both works computationally and uses only local updates. Leveraging recent advances in machine learning on approximating gradients for BPTT, we derive biologically plausible plasticity rules that enable recurrent networks to accurately learn long-term dependencies in sequential data. The solution takes the form of neurons with segregated voltage compartments, with several synaptic sub-populations that have different functional properties. The network operates in distinct phases during which each synaptic sub-population is updated by its own local plasticity rule. Our results provide new insights into the potential roles of segregated dendritic compartments, branch-specific inhibition, and global circuit phases in learning.