 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInhibitory normalization of error signals improves learning in neural circuits
Mar 18, 2026Normalization is a critical operation in neural circuits. In the brain, there is evidence that normalization is implemented via inhibitory interneurons and allows neural populations to adjust to changes in the distribution of their inputs. In artificial neural networks (ANNs), normalization is used to improve learning in tasks that involve complex input distributions. However, it is unclear whether inhibition-mediated normalization in biological neural circuits also improves learning. Here, we explore this possibility using ANNs with separate excitatory and inhibitory populations trained on an image recognition task with variable luminosity. We find that inhibition-mediated normalization does not improve learning if normalization is applied only during inference. However, when this normalization is extended to include back-propagated errors, performance improves significantly. These results suggest that if inhibition-mediated normalization improves learning in the brain, it additionally requires the normalization of learning signals.
Learning Successor Features the Simple Way
Oct 29, 2024



In Deep Reinforcement Learning (RL), it is a challenge to learn representations that do not exhibit catastrophic forgetting or interference in non-stationary environments. Successor Features (SFs) offer a potential solution to this challenge. However, canonical techniques for learning SFs from pixel-level observations often lead to representation collapse, wherein representations degenerate and fail to capture meaningful variations in the data. More recent methods for learning SFs can avoid representation collapse, but they often involve complex losses and multiple learning phases, reducing their efficiency. We introduce a novel, simple method for learning SFs directly from pixels. Our approach uses a combination of a Temporal-difference (TD) loss and a reward prediction loss, which together capture the basic mathematical definition of SFs. We show that our approach matches or outperforms existing SF learning techniques in both 2D (Minigrid), 3D (Miniworld) mazes and Mujoco, for both single and continual learning scenarios. As well, our technique is efficient, and can reach higher levels of performance in less time than other approaches. Our work provides a new, streamlined technique for learning SFs directly from pixel observations, with no pretraining required.
Addressing Sample Inefficiency in Multi-View Representation Learning
Dec 17, 2023



Non-contrastive self-supervised learning (NC-SSL) methods like BarlowTwins and VICReg have shown great promise for label-free representation learning in computer vision. Despite the apparent simplicity of these techniques, researchers must rely on several empirical heuristics to achieve competitive performance, most notably using high-dimensional projector heads and two augmentations of the same image. In this work, we provide theoretical insights on the implicit bias of the BarlowTwins and VICReg loss that can explain these heuristics and guide the development of more principled recommendations. Our first insight is that the orthogonality of the features is more critical than projector dimensionality for learning good representations. Based on this, we empirically demonstrate that low-dimensional projector heads are sufficient with appropriate regularization, contrary to the existing heuristic. Our second theoretical insight suggests that using multiple data augmentations better represents the desiderata of the SSL objective. Based on this, we demonstrate that leveraging more augmentations per sample improves representation quality and trainability. In particular, it improves optimization convergence, leading to better features emerging earlier in the training. Remarkably, we demonstrate that we can reduce the pretraining dataset size by up to 4x while maintaining accuracy and improving convergence simply by using more data augmentations. Combining these insights, we present practical pretraining recommendations that improve wall-clock time by 2x and improve performance on CIFAR-10/STL-10 datasets using a ResNet-50 backbone. Thus, this work provides a theoretical insight into NC-SSL and produces practical recommendations for enhancing its sample and compute efficiency.
Synaptic Weight Distributions Depend on the Geometry of Plasticity
May 30, 2023



Most learning algorithms in machine learning rely on gradient descent to adjust model parameters, and a growing literature in computational neuroscience leverages these ideas to study synaptic plasticity in the brain. However, the vast majority of this work ignores a critical underlying assumption: the choice of distance for synaptic changes (i.e. the geometry of synaptic plasticity). Gradient descent assumes that the distance is Euclidean, but many other distances are possible, and there is no reason that biology necessarily uses Euclidean geometry. Here, using the theoretical tools provided by mirror descent, we show that, regardless of the loss being minimized, the distribution of synaptic weights will depend on the geometry of synaptic plasticity. We use these results to show that experimentally-observed log-normal weight distributions found in several brain areas are not consistent with standard gradient descent (i.e. a Euclidean geometry), but rather with non-Euclidean distances. Finally, we show that it should be possible to experimentally test for different synaptic geometries by comparing synaptic weight distributions before and after learning. Overall, this work shows that the current paradigm in theoretical work on synaptic plasticity that assumes Euclidean synaptic geometry may be misguided and that it should be possible to experimentally determine the true geometry of synaptic plasticity in the brain.
Beyond accuracy: generalization properties of bio-plausible temporal credit assignment rules
Jun 02, 2022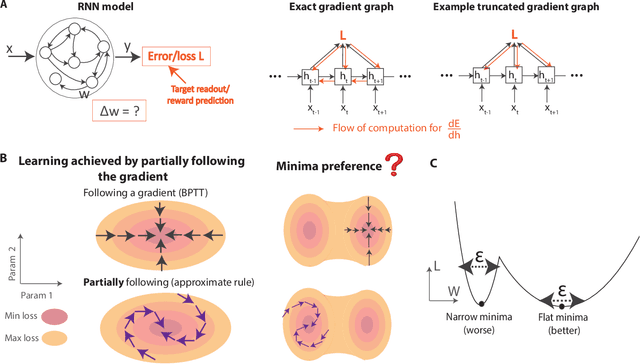
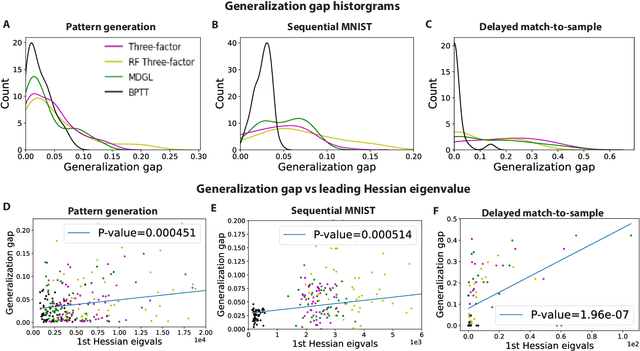
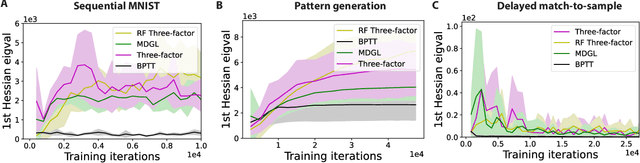
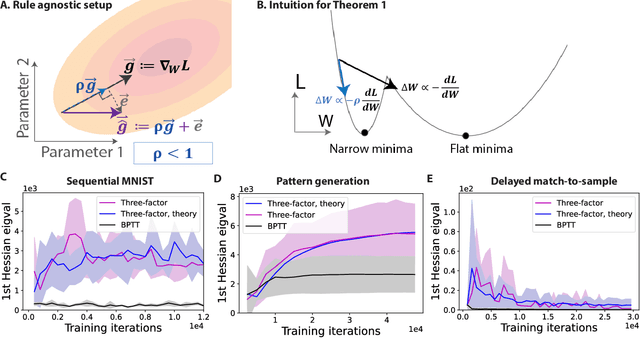
To unveil how the brain learns, ongoing work seeks biologically-plausible approximations of gradient descent algorithms for training recurrent neural networks (RNNs). Yet, beyond task accuracy, it is unclear if such learning rules converge to solutions that exhibit different levels of generalization than their nonbiologically-plausible counterparts. Leveraging results from deep learning theory based on loss landscape curvature, we ask: how do biologically-plausible gradient approximations affect generalization? We first demonstrate that state-of-the-art biologically-plausible learning rules for training RNNs exhibit worse and more variable generalization performance compared to their machine learning counterparts that follow the true gradient more closely. Next, we verify that such generalization performance is correlated significantly with loss landscape curvature, and we show that biologically-plausible learning rules tend to approach high-curvature regions in synaptic weight space. Using tools from dynamical systems, we derive theoretical arguments and present a theorem explaining this phenomenon. This predicts our numerical results, and explains why biologically-plausible rules lead to worse and more variable generalization properties. Finally, we suggest potential remedies that could be used by the brain to mitigate this effect. To our knowledge, our analysis is the first to identify the reason for this generalization gap between artificial and biologically-plausible learning rules, which can help guide future investigations into how the brain learns solutions that generalize.
Investigating Power laws in Deep Representation Learning
Feb 11, 2022Representation learning that leverages large-scale labelled datasets, is central to recent progress in machine learning. Access to task relevant labels at scale is often scarce or expensive, motivating the need to learn from unlabelled datasets with self-supervised learning (SSL). Such large unlabelled datasets (with data augmentations) often provide a good coverage of the underlying input distribution. However evaluating the representations learned by SSL algorithms still requires task-specific labelled samples in the training pipeline. Additionally, the generalization of task-specific encoding is often sensitive to potential distribution shift. Inspired by recent advances in theoretical machine learning and vision neuroscience, we observe that the eigenspectrum of the empirical feature covariance matrix often follows a power law. For visual representations, we estimate the coefficient of the power law, $\alpha$, across three key attributes which influence representation learning: learning objective (supervised, SimCLR, Barlow Twins and BYOL), network architecture (VGG, ResNet and Vision Transformer), and tasks (object and scene recognition). We observe that under mild conditions, proximity of $\alpha$ to 1, is strongly correlated to the downstream generalization performance. Furthermore, $\alpha \approx 1$ is a strong indicator of robustness to label noise during fine-tuning. Notably, $\alpha$ is computable from the representations without knowledge of any labels, thereby offering a framework to evaluate the quality of representations in unlabelled datasets.
CCN GAC Workshop: Issues with learning in biological recurrent neural networks
May 12, 2021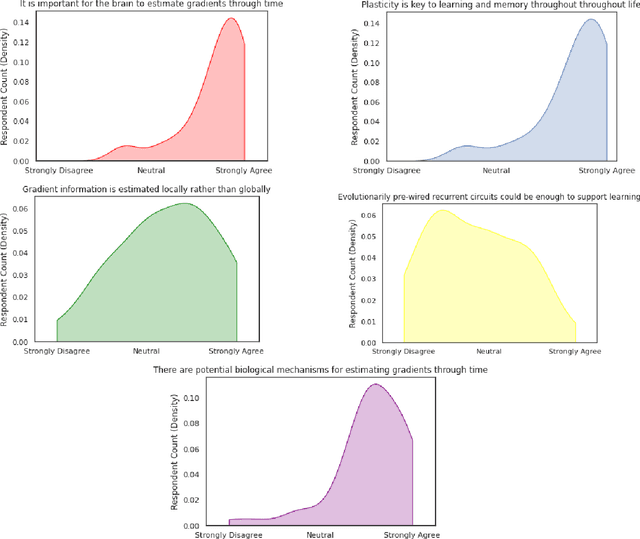
This perspective piece came about through the Generative Adversarial Collaboration (GAC) series of workshops organized by the Computational Cognitive Neuroscience (CCN) conference in 2020. We brought together a number of experts from the field of theoretical neuroscience to debate emerging issues in our understanding of how learning is implemented in biological recurrent neural networks. Here, we will give a brief review of the common assumptions about biological learning and the corresponding findings from experimental neuroscience and contrast them with the efficiency of gradient-based learning in recurrent neural networks commonly used in artificial intelligence. We will then outline the key issues discussed in the workshop: synaptic plasticity, neural circuits, theory-experiment divide, and objective functions. Finally, we conclude with recommendations for both theoretical and experimental neuroscientists when designing new studies that could help to bring clarity to these issues.
Deep Semantic Architecture with discriminative feature visualization for neuroimage analysis
Jun 29, 2018
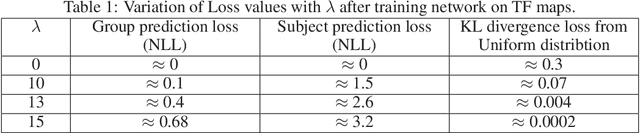

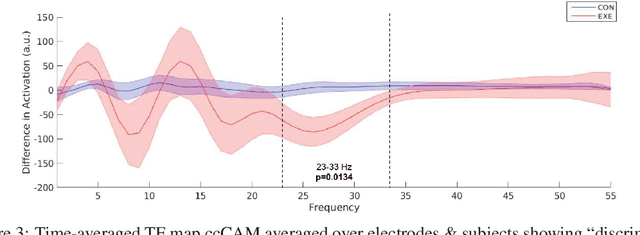
Neuroimaging data analysis often involves \emph{a-priori} selection of data features to study the underlying neural activity. Since this could lead to sub-optimal feature selection and thereby prevent the detection of subtle patterns in neural activity, data-driven methods have recently gained popularity for optimizing neuroimaging data analysis pipelines and thereby, improving our understanding of neural mechanisms. In this context, we developed a deep convolutional architecture that can identify discriminating patterns in neuroimaging data and applied it to electroencephalography (EEG) recordings collected from 25 subjects performing a hand motor task before and after a rest period or a bout of exercise. The deep network was trained to classify subjects into exercise and control groups based on differences in their EEG signals. Subsequently, we developed a novel method termed the cue-combination for Class Activation Map (ccCAM), which enabled us to identify discriminating spatio-temporal features within definite frequency bands (23--33 Hz) and assess the effects of exercise on the brain. Additionally, the proposed architecture allowed the visualization of the differences in the propagation of underlying neural activity across the cortex between the two groups, for the first time in our knowledge. Our results demonstrate the feasibility of using deep network architectures for neuroimaging analysis in different contexts such as, for the identification of robust brain biomarkers to better characterize and potentially treat neurological disorders.
SIMILARnet: Simultaneous Intelligent Localization and Recognition Network
Nov 08, 2017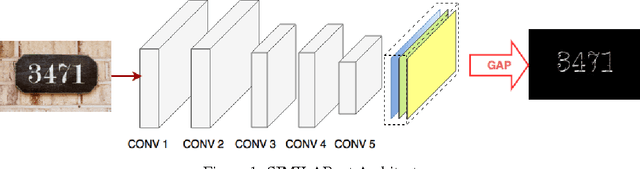
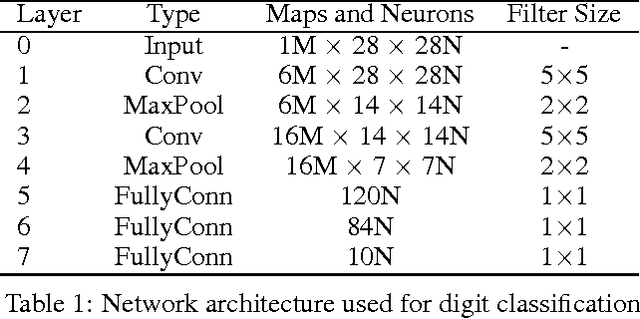

Global Average Pooling (GAP) [4] has been used previously to generate class activation for image classification tasks. The motivation behind SIMILARnet comes from the fact that the convolutional filters possess position information of the essential features and hence, combination of the feature maps could help us locate the class instances in an image. We propose a biologically inspired model that is free of differential connections and doesn't require separate training thereby reducing computation overhead. Our novel architecture generates promising results and unlike existing methods, the model is not sensitive to the input image size, thus promising wider application. Codes for the experiment and illustrations can be found at: https://github.com/brcsomnath/Advanced-GAP .
Handwriting Profiling using Generative Adversarial Networks
Nov 27, 2016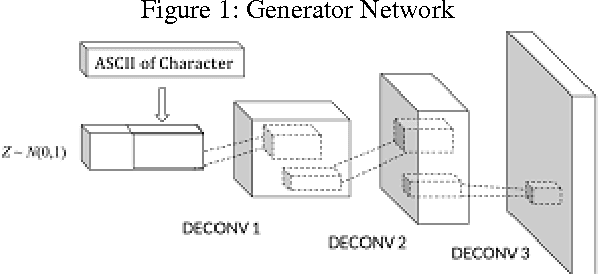
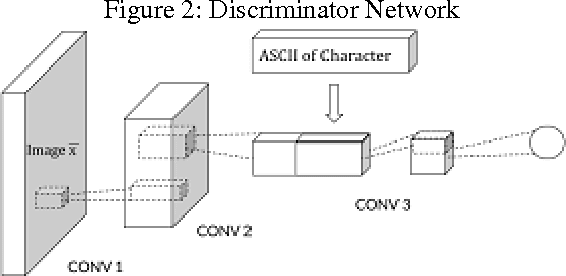
Handwriting is a skill learned by humans from a very early age. The ability to develop one's own unique handwriting as well as mimic another person's handwriting is a task learned by the brain with practice. This paper deals with this very problem where an intelligent system tries to learn the handwriting of an entity using Generative Adversarial Networks (GANs). We propose a modified architecture of DCGAN (Radford, Metz, and Chintala 2015) to achieve this. We also discuss about applying reinforcement learning techniques to achieve faster learning. Our algorithm hopes to give new insights in this area and its uses include identification of forged documents, signature verification, computer generated art, digitization of documents among others. Our early implementation of the algorithm illustrates a good performance with MNIST datasets.