 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlexible inference of learning rules from de novo learning data using neural networks
Sep 04, 2025Understanding how animals learn is a central challenge in neuroscience, with growing relevance to the development of animal- or human-aligned artificial intelligence. However, most existing approaches assume specific parametric forms for the learning rule (e.g., Q-learning, policy gradient) or are limited to simplified settings like bandit tasks, which do not involve learning a new input-output mapping from scratch. In contrast, animals must often learn new behaviors de novo, which poses a rich challenge for learning-rule inference. We target this problem by inferring learning rules directly from animal decision-making data during de novo task learning, a setting that requires models flexible enough to capture suboptimality, history dependence, and rich external stimulus integration without strong structural priors. We first propose a nonparametric framework that parameterizes the per-trial update of policy weights with a deep neural network (DNN), and validate it by recovering ground-truth rules in simulation. We then extend to a recurrent variant (RNN) that captures non-Markovian dynamics by allowing updates to depend on trial history. Applied to a large behavioral dataset of mice learning a sensory decision-making task over multiple weeks, our models improved predictions on held-out data. The inferred rules revealed asymmetric updates after correct versus error trials and history dependence, consistent with non-Markovian learning. Overall, these results introduce a flexible framework for inferring biological learning rules from behavioral data in de novo learning tasks, providing insights to inform experimental training protocols and the development of behavioral digital twins.
Can Biologically Plausible Temporal Credit Assignment Rules Match BPTT for Neural Similarity? E-prop as an Example
Jun 07, 2025Understanding how the brain learns may be informed by studying biologically plausible learning rules. These rules, often approximating gradient descent learning to respect biological constraints such as locality, must meet two critical criteria to be considered an appropriate brain model: (1) good neuroscience task performance and (2) alignment with neural recordings. While extensive research has assessed the first criterion, the second remains underexamined. Employing methods such as Procrustes analysis on well-known neuroscience datasets, this study demonstrates the existence of a biologically plausible learning rule -- namely e-prop, which is based on gradient truncation and has demonstrated versatility across a wide range of tasks -- that can achieve neural data similarity comparable to Backpropagation Through Time (BPTT) when matched for task accuracy. Our findings also reveal that model architecture and initial conditions can play a more significant role in determining neural similarity than the specific learning rule. Furthermore, we observe that BPTT-trained models and their biologically plausible counterparts exhibit similar dynamical properties at comparable accuracies. These results underscore the substantial progress made in developing biologically plausible learning rules, highlighting their potential to achieve both competitive task performance and neural data similarity.
How Initial Connectivity Shapes Biologically Plausible Learning in Recurrent Neural Networks
Oct 15, 2024The impact of initial connectivity on learning has been extensively studied in the context of backpropagation-based gradient descent, but it remains largely underexplored in biologically plausible learning settings. Focusing on recurrent neural networks (RNNs), we found that the initial weight magnitude significantly influences the learning performance of biologically plausible learning rules in a similar manner to its previously observed effect on training via backpropagation through time (BPTT). By examining the maximum Lyapunov exponent before and after training, we uncovered the greater demands that certain initialization schemes place on training to achieve desired information propagation properties. Consequently, we extended the recently proposed gradient flossing method, which regularizes the Lyapunov exponents, to biologically plausible learning and observed an improvement in learning performance. To our knowledge, we are the first to examine the impact of initialization on biologically plausible learning rules for RNNs and to subsequently propose a biologically plausible remedy. Such an investigation could lead to predictions about the influence of initial connectivity on learning dynamics and performance, as well as guide neuromorphic design.
Evolutionary algorithms as an alternative to backpropagation for supervised training of Biophysical Neural Networks and Neural ODEs
Nov 21, 2023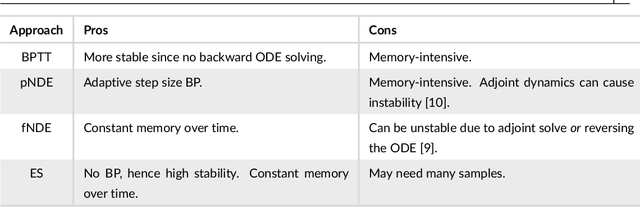
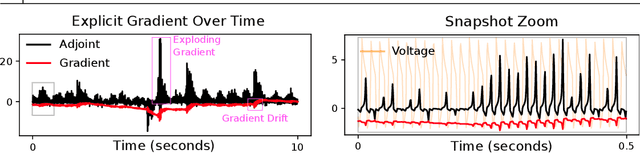
Training networks consisting of biophysically accurate neuron models could allow for new insights into how brain circuits can organize and solve tasks. We begin by analyzing the extent to which the central algorithm for neural network learning -- stochastic gradient descent through backpropagation (BP) -- can be used to train such networks. We find that properties of biophysically based neural network models needed for accurate modelling such as stiffness, high nonlinearity and long evaluation timeframes relative to spike times makes BP unstable and divergent in a variety of cases. To address these instabilities and inspired by recent work, we investigate the use of "gradient-estimating" evolutionary algorithms (EAs) for training biophysically based neural networks. We find that EAs have several advantages making them desirable over direct BP, including being forward-pass only, robust to noisy and rigid losses, allowing for discrete loss formulations, and potentially facilitating a more global exploration of parameters. We apply our method to train a recurrent network of Morris-Lecar neuron models on a stimulus integration and working memory task, and show how it can succeed in cases where direct BP is inapplicable. To expand on the viability of EAs in general, we apply them to a general neural ODE problem and a stiff neural ODE benchmark and find again that EAs can out-perform direct BP here, especially for the over-parameterized regime. Our findings suggest that biophysical neurons could provide useful benchmarks for testing the limits of BP-adjacent methods, and demonstrate the viability of EAs for training networks with complex components.
How connectivity structure shapes rich and lazy learning in neural circuits
Oct 12, 2023In theoretical neuroscience, recent work leverages deep learning tools to explore how some network attributes critically influence its learning dynamics. Notably, initial weight distributions with small (resp. large) variance may yield a rich (resp. lazy) regime, where significant (resp. minor) changes to network states and representation are observed over the course of learning. However, in biology, neural circuit connectivity generally has a low-rank structure and therefore differs markedly from the random initializations generally used for these studies. As such, here we investigate how the structure of the initial weights, in particular their effective rank, influences the network learning regime. Through both empirical and theoretical analyses, we discover that high-rank initializations typically yield smaller network changes indicative of lazier learning, a finding we also confirm with experimentally-driven initial connectivity in recurrent neural networks. Conversely, low-rank initialization biases learning towards richer learning. Importantly, however, as an exception to this rule, we find lazier learning can still occur with a low-rank initialization that aligns with task and data statistics. Our research highlights the pivotal role of initial weight structures in shaping learning regimes, with implications for metabolic costs of plasticity and risks of catastrophic forgetting.
Biologically-plausible backpropagation through arbitrary timespans via local neuromodulators
Jun 02, 2022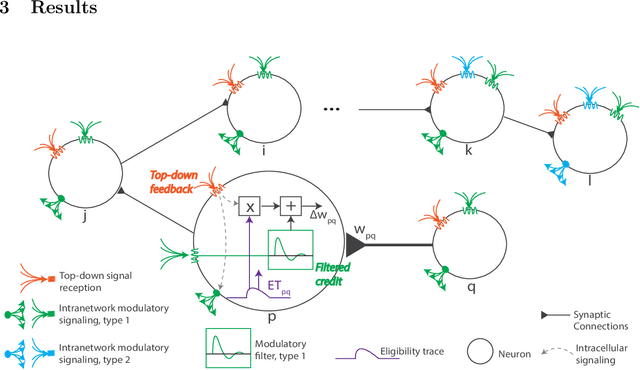
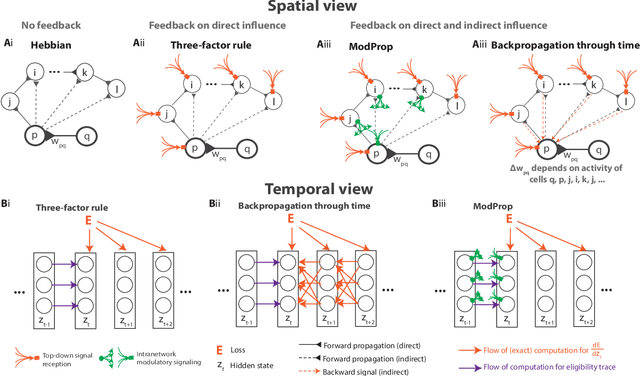
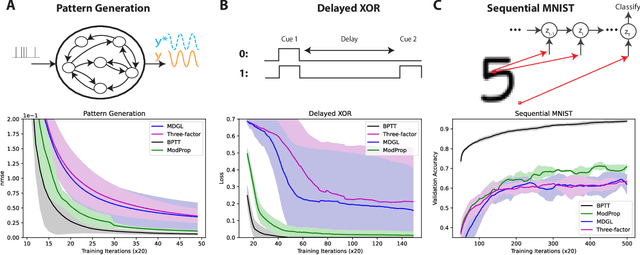
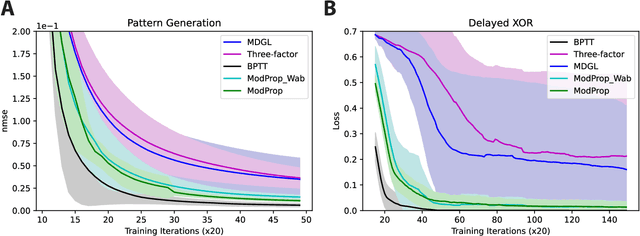
The spectacular successes of recurrent neural network models where key parameters are adjusted via backpropagation-based gradient descent have inspired much thought as to how biological neuronal networks might solve the corresponding synaptic credit assignment problem. There is so far little agreement, however, as to how biological networks could implement the necessary backpropagation through time, given widely recognized constraints of biological synaptic network signaling architectures. Here, we propose that extra-synaptic diffusion of local neuromodulators such as neuropeptides may afford an effective mode of backpropagation lying within the bounds of biological plausibility. Going beyond existing temporal truncation-based gradient approximations, our approximate gradient-based update rule, ModProp, propagates credit information through arbitrary time steps. ModProp suggests that modulatory signals can act on receiving cells by convolving their eligibility traces via causal, time-invariant and synapse-type-specific filter taps. Our mathematical analysis of ModProp learning, together with simulation results on benchmark temporal tasks, demonstrate the advantage of ModProp over existing biologically-plausible temporal credit assignment rules. These results suggest a potential neuronal mechanism for signaling credit information related to recurrent interactions over a longer time horizon. Finally, we derive an in-silico implementation of ModProp that could serve as a low-complexity and causal alternative to backpropagation through time.
Beyond accuracy: generalization properties of bio-plausible temporal credit assignment rules
Jun 02, 2022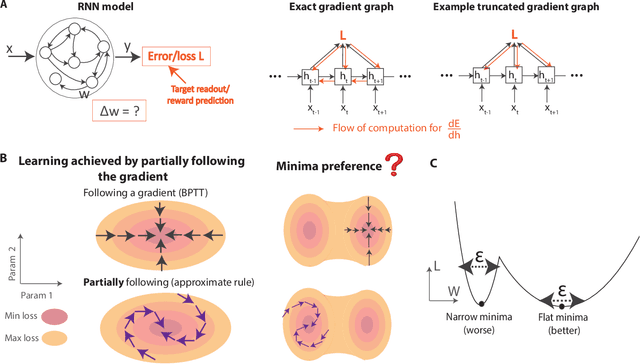
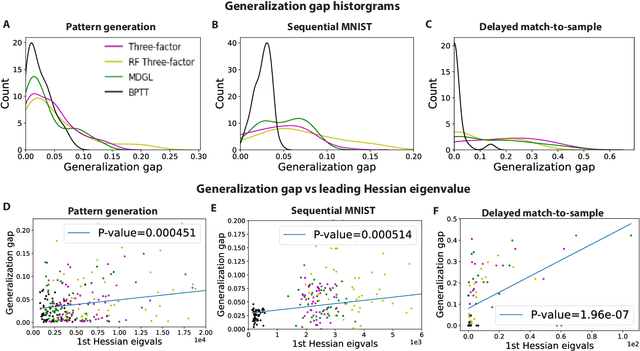
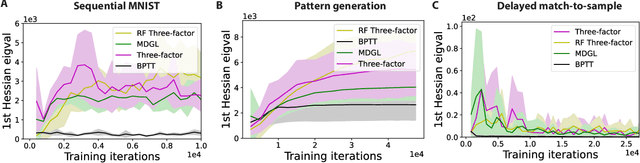
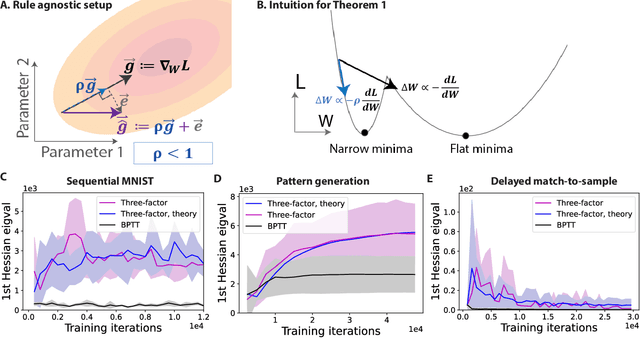
To unveil how the brain learns, ongoing work seeks biologically-plausible approximations of gradient descent algorithms for training recurrent neural networks (RNNs). Yet, beyond task accuracy, it is unclear if such learning rules converge to solutions that exhibit different levels of generalization than their nonbiologically-plausible counterparts. Leveraging results from deep learning theory based on loss landscape curvature, we ask: how do biologically-plausible gradient approximations affect generalization? We first demonstrate that state-of-the-art biologically-plausible learning rules for training RNNs exhibit worse and more variable generalization performance compared to their machine learning counterparts that follow the true gradient more closely. Next, we verify that such generalization performance is correlated significantly with loss landscape curvature, and we show that biologically-plausible learning rules tend to approach high-curvature regions in synaptic weight space. Using tools from dynamical systems, we derive theoretical arguments and present a theorem explaining this phenomenon. This predicts our numerical results, and explains why biologically-plausible rules lead to worse and more variable generalization properties. Finally, we suggest potential remedies that could be used by the brain to mitigate this effect. To our knowledge, our analysis is the first to identify the reason for this generalization gap between artificial and biologically-plausible learning rules, which can help guide future investigations into how the brain learns solutions that generalize.