 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamical similarity analysis uniquely captures how computations develop in RNNs
Oct 31, 2024



Methods for analyzing representations in neural systems are increasingly popular tools in neuroscience and mechanistic interpretability. Measures comparing neural activations across conditions, architectures, and species give scalable ways to understand information transformation within different neural networks. However, recent findings show that some metrics respond to spurious signals, leading to misleading results. Establishing benchmark test cases is thus essential for identifying the most reliable metric and potential improvements. We propose that compositional learning in recurrent neural networks (RNNs) can provide a test case for dynamical representation alignment metrics. Implementing this case allows us to evaluate if metrics can identify representations that develop throughout learning and determine if representations identified by metrics reflect the network's actual computations. Building both attractor and RNN based test cases, we show that the recently proposed Dynamical Similarity Analysis (DSA) is more noise robust and reliably identifies behaviorally relevant representations compared to prior metrics (Procrustes, CKA). We also demonstrate how such test cases can extend beyond metric evaluation to study new architectures. Specifically, testing DSA in modern (Mamba) state space models suggests that these models, unlike RNNs, may not require changes in recurrent dynamics due to their expressive hidden states. Overall, we develop test cases that showcase how DSA's enhanced ability to detect dynamical motifs makes it highly effective for identifying ongoing computations in RNNs and revealing how networks learn tasks.
BP(λ): Online Learning via Synthetic Gradients
Jan 13, 2024Training recurrent neural networks typically relies on backpropagation through time (BPTT). BPTT depends on forward and backward passes to be completed, rendering the network locked to these computations before loss gradients are available. Recently, Jaderberg et al. proposed synthetic gradients to alleviate the need for full BPTT. In their implementation synthetic gradients are learned through a mixture of backpropagated gradients and bootstrapped synthetic gradients, analogous to the temporal difference (TD) algorithm in Reinforcement Learning (RL). However, as in TD learning, heavy use of bootstrapping can result in bias which leads to poor synthetic gradient estimates. Inspired by the accumulate $\mathrm{TD}(\lambda)$ in RL, we propose a fully online method for learning synthetic gradients which avoids the use of BPTT altogether: accumulate $BP(\lambda)$. As in accumulate $\mathrm{TD}(\lambda)$, we show analytically that accumulate $\mathrm{BP}(\lambda)$ can control the level of bias by using a mixture of temporal difference errors and recursively defined eligibility traces. We next demonstrate empirically that our model outperforms the original implementation for learning synthetic gradients in a variety of tasks, and is particularly suited for capturing longer timescales. Finally, building on recent work we reflect on accumulate $\mathrm{BP}(\lambda)$ as a principle for learning in biological circuits. In summary, inspired by RL principles we introduce an algorithm capable of bias-free online learning via synthetic gradients.
Single-phase deep learning in cortico-cortical networks
Jun 23, 2022



The error-backpropagation (backprop) algorithm remains the most common solution to the credit assignment problem in artificial neural networks. In neuroscience, it is unclear whether the brain could adopt a similar strategy to correctly modify its synapses. Recent models have attempted to bridge this gap while being consistent with a range of experimental observations. However, these models are either unable to effectively backpropagate error signals across multiple layers or require a multi-phase learning process, neither of which are reminiscent of learning in the brain. Here, we introduce a new model, bursting cortico-cortical networks (BurstCCN), which solves these issues by integrating known properties of cortical networks namely bursting activity, short-term plasticity (STP) and dendrite-targeting interneurons. BurstCCN relies on burst multiplexing via connection-type-specific STP to propagate backprop-like error signals within deep cortical networks. These error signals are encoded at distal dendrites and induce burst-dependent plasticity as a result of excitatory-inhibitory topdown inputs. First, we demonstrate that our model can effectively backpropagate errors through multiple layers using a single-phase learning process. Next, we show both empirically and analytically that learning in our model approximates backprop-derived gradients. Finally, we demonstrate that our model is capable of learning complex image classification tasks (MNIST and CIFAR-10). Overall, our results suggest that cortical features across sub-cellular, cellular, microcircuit and systems levels jointly underlie single-phase efficient deep learning in the brain.
Lost in Latent Space: Disentangled Models and the Challenge of Combinatorial Generalisation
Apr 05, 2022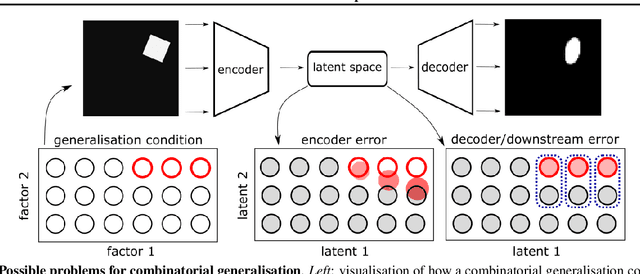
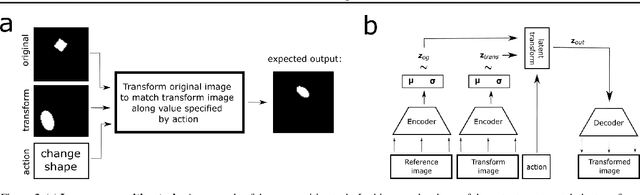
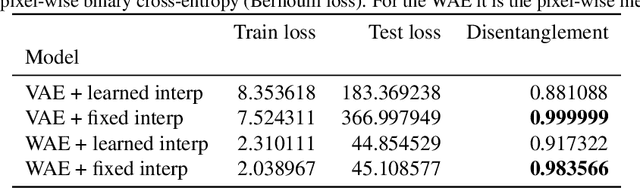
Recent research has shown that generative models with highly disentangled representations fail to generalise to unseen combination of generative factor values. These findings contradict earlier research which showed improved performance in out-of-training distribution settings when compared to entangled representations. Additionally, it is not clear if the reported failures are due to (a) encoders failing to map novel combinations to the proper regions of the latent space or (b) novel combinations being mapped correctly but the decoder/downstream process is unable to render the correct output for the unseen combinations. We investigate these alternatives by testing several models on a range of datasets and training settings. We find that (i) when models fail, their encoders also fail to map unseen combinations to correct regions of the latent space and (ii) when models succeed, it is either because the test conditions do not exclude enough examples, or because excluded generative factors determine independent parts of the output image. Based on these results, we argue that to generalise properly, models not only need to capture factors of variation, but also understand how to invert the generative process that was used to generate the data.
Cortico-cerebellar networks as decoupling neural interfaces
Oct 28, 2021



The brain solves the credit assignment problem remarkably well. For credit to be assigned across neural networks they must, in principle, wait for specific neural computations to finish. How the brain deals with this inherent locking problem has remained unclear. Deep learning methods suffer from similar locking constraints both on the forward and feedback phase. Recently, decoupled neural interfaces (DNIs) were introduced as a solution to the forward and feedback locking problems in deep networks. Here we propose that a specialised brain region, the cerebellum, helps the cerebral cortex solve similar locking problems akin to DNIs. To demonstrate the potential of this framework we introduce a systems-level model in which a recurrent cortical network receives online temporal feedback predictions from a cerebellar module. We test this cortico-cerebellar recurrent neural network (ccRNN) model on a number of sensorimotor (line and digit drawing) and cognitive tasks (pattern recognition and caption generation) that have been shown to be cerebellar-dependent. In all tasks, we observe that ccRNNs facilitates learning while reducing ataxia-like behaviours, consistent with classical experimental observations. Moreover, our model also explains recent behavioural and neuronal observations while making several testable predictions across multiple levels. Overall, our work offers a novel perspective on the cerebellum as a brain-wide decoupling machine for efficient credit assignment and opens a new avenue between deep learning and neuroscience.
Learning offline: memory replay in biological and artificial reinforcement learning
Sep 21, 2021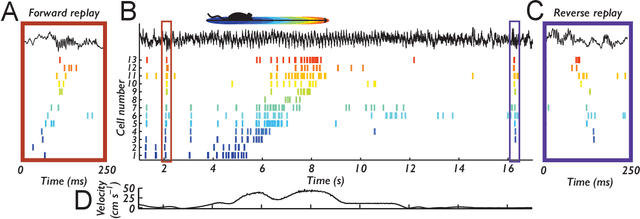
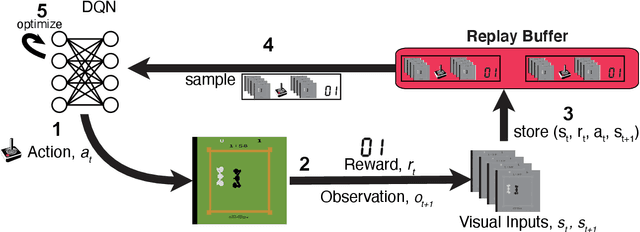
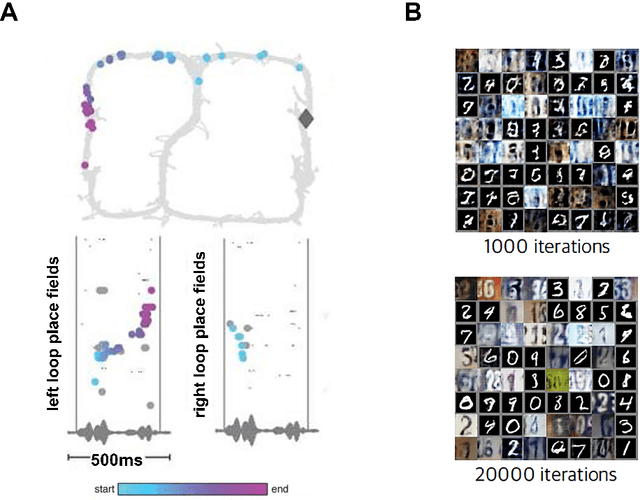
Learning to act in an environment to maximise rewards is among the brain's key functions. This process has often been conceptualised within the framework of reinforcement learning, which has also gained prominence in machine learning and artificial intelligence (AI) as a way to optimise decision-making. A common aspect of both biological and machine reinforcement learning is the reactivation of previously experienced episodes, referred to as replay. Replay is important for memory consolidation in biological neural networks, and is key to stabilising learning in deep neural networks. Here, we review recent developments concerning the functional roles of replay in the fields of neuroscience and AI. Complementary progress suggests how replay might support learning processes, including generalisation and continual learning, affording opportunities to transfer knowledge across the two fields to advance the understanding of biological and artificial learning and memory.
CCN GAC Workshop: Issues with learning in biological recurrent neural networks
May 12, 2021
This perspective piece came about through the Generative Adversarial Collaboration (GAC) series of workshops organized by the Computational Cognitive Neuroscience (CCN) conference in 2020. We brought together a number of experts from the field of theoretical neuroscience to debate emerging issues in our understanding of how learning is implemented in biological recurrent neural networks. Here, we will give a brief review of the common assumptions about biological learning and the corresponding findings from experimental neuroscience and contrast them with the efficiency of gradient-based learning in recurrent neural networks commonly used in artificial intelligence. We will then outline the key issues discussed in the workshop: synaptic plasticity, neural circuits, theory-experiment divide, and objective functions. Finally, we conclude with recommendations for both theoretical and experimental neuroscientists when designing new studies that could help to bring clarity to these issues.
Dendritic cortical microcircuits approximate the backpropagation algorithm
Oct 26, 2018
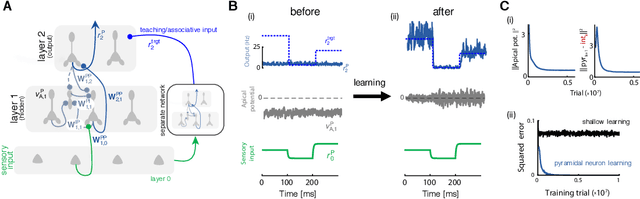
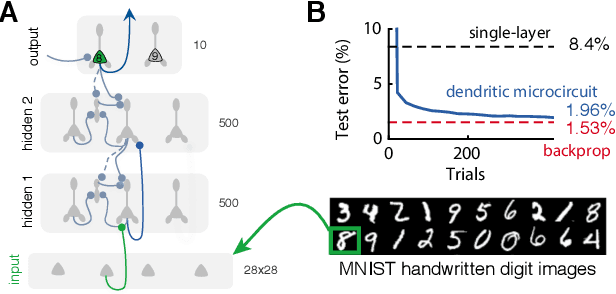
Deep learning has seen remarkable developments over the last years, many of them inspired by neuroscience. However, the main learning mechanism behind these advances - error backpropagation - appears to be at odds with neurobiology. Here, we introduce a multilayer neuronal network model with simplified dendritic compartments in which error-driven synaptic plasticity adapts the network towards a global desired output. In contrast to previous work our model does not require separate phases and synaptic learning is driven by local dendritic prediction errors continuously in time. Such errors originate at apical dendrites and occur due to a mismatch between predictive input from lateral interneurons and activity from actual top-down feedback. Through the use of simple dendritic compartments and different cell-types our model can represent both error and normal activity within a pyramidal neuron. We demonstrate the learning capabilities of the model in regression and classification tasks, and show analytically that it approximates the error backpropagation algorithm. Moreover, our framework is consistent with recent observations of learning between brain areas and the architecture of cortical microcircuits. Overall, we introduce a novel view of learning on dendritic cortical circuits and on how the brain may solve the long-standing synaptic credit assignment problem.
Cortical microcircuits as gated-recurrent neural networks
Jan 03, 2018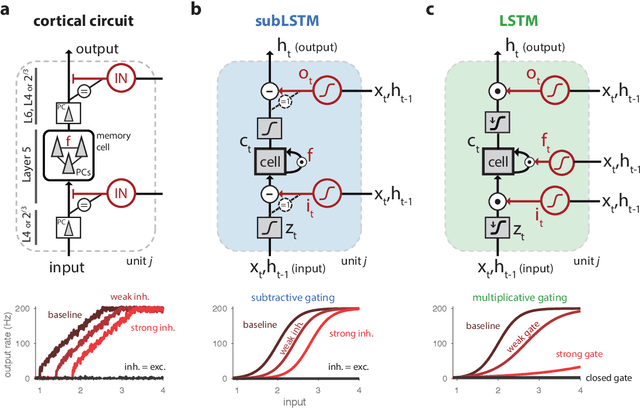
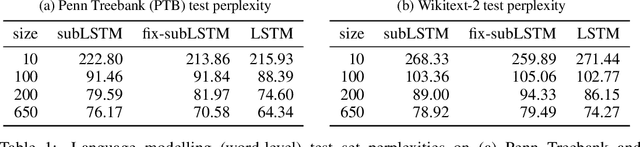
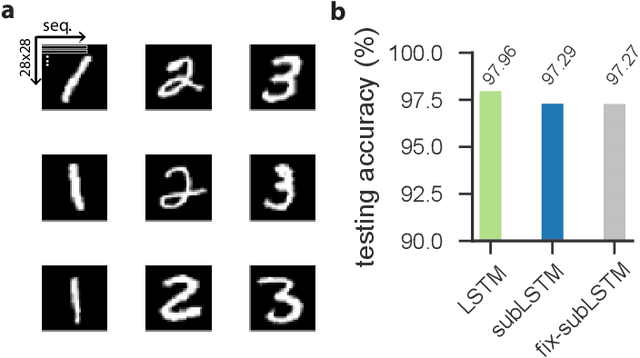
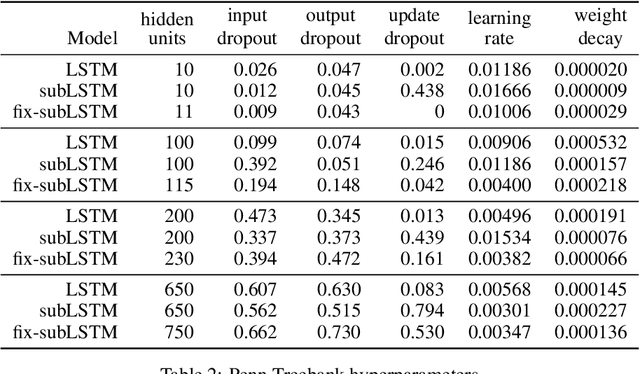
Cortical circuits exhibit intricate recurrent architectures that are remarkably similar across different brain areas. Such stereotyped structure suggests the existence of common computational principles. However, such principles have remained largely elusive. Inspired by gated-memory networks, namely long short-term memory networks (LSTMs), we introduce a recurrent neural network in which information is gated through inhibitory cells that are subtractive (subLSTM). We propose a natural mapping of subLSTMs onto known canonical excitatory-inhibitory cortical microcircuits. Our empirical evaluation across sequential image classification and language modelling tasks shows that subLSTM units can achieve similar performance to LSTM units. These results suggest that cortical circuits can be optimised to solve complex contextual problems and proposes a novel view on their computational function. Overall our work provides a step towards unifying recurrent networks as used in machine learning with their biological counterparts.
Dendritic error backpropagation in deep cortical microcircuits
Dec 30, 2017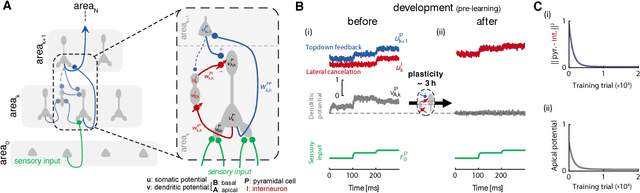
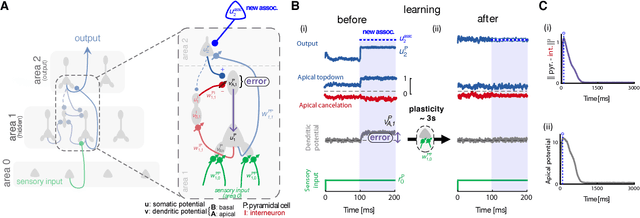
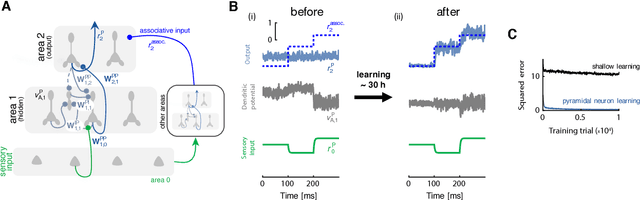
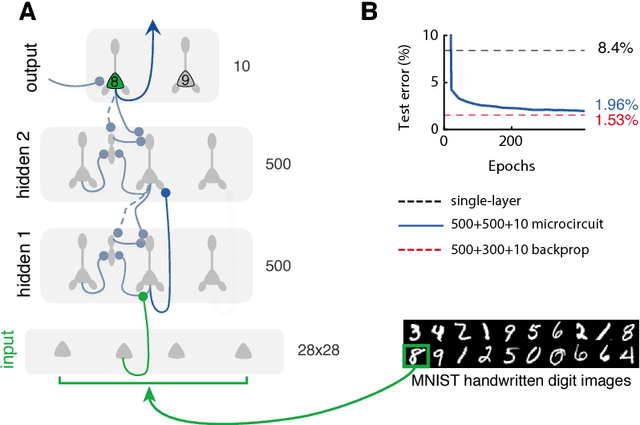
Animal behaviour depends on learning to associate sensory stimuli with the desired motor command. Understanding how the brain orchestrates the necessary synaptic modifications across different brain areas has remained a longstanding puzzle. Here, we introduce a multi-area neuronal network model in which synaptic plasticity continuously adapts the network towards a global desired output. In this model synaptic learning is driven by a local dendritic prediction error that arises from a failure to predict the top-down input given the bottom-up activities. Such errors occur at apical dendrites of pyramidal neurons where both long-range excitatory feedback and local inhibitory predictions are integrated. When local inhibition fails to match excitatory feedback an error occurs which triggers plasticity at bottom-up synapses at basal dendrites of the same pyramidal neurons. We demonstrate the learning capabilities of the model in a number of tasks and show that it approximates the classical error backpropagation algorithm. Finally, complementing this cortical circuit with a disinhibitory mechanism enables attention-like stimulus denoising and generation. Our framework makes several experimental predictions on the function of dendritic integration and cortical microcircuits, is consistent with recent observations of cross-area learning, and suggests a biological implementation of deep learning.