 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Variational Latent Equilibrium for Learning in Neuronal Circuits
Mar 12, 2026Brains remain unrivaled in their ability to recognize and generate complex spatiotemporal patterns. While AI is able to reproduce some of these capabilities, deep learning algorithms remain largely at odds with our current understanding of brain circuitry and dynamics. This is prominently the case for backpropagation through time (BPTT), the go-to algorithm for learning complex temporal dependencies. In this work we propose a general formalism to approximate BPTT in a controlled, biologically plausible manner. Our approach builds on, unifies and extends several previous approaches to local, time-continuous, phase-free spatiotemporal credit assignment based on principles of energy conservation and extremal action. Our starting point is a prospective energy function of neuronal states, from which we calculate real-time error dynamics for time-continuous neuronal networks. In the general case, this provides a simple and straightforward derivation of the adjoint method result for neuronal networks, the time-continuous equivalent to BPTT. With a few modifications, we can turn this into a fully local (in space and time) set of equations for neuron and synapse dynamics. Our theory provides a rigorous framework for spatiotemporal deep learning in the brain, while simultaneously suggesting a blueprint for physical circuits capable of carrying out these computations. These results reframe and extend the recently proposed Generalized Latent Equilibrium (GLE) model.
Teaching signal synchronization in deep neural networks with prospective neurons
Nov 18, 2025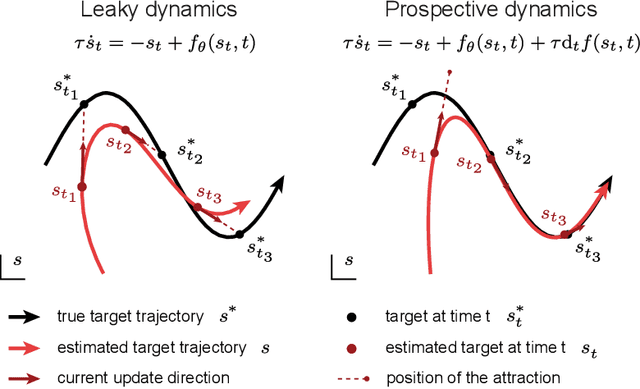
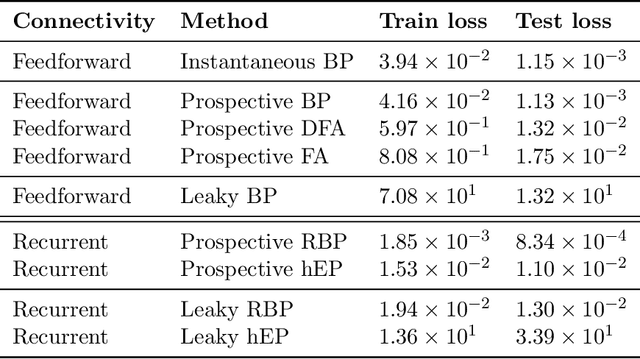
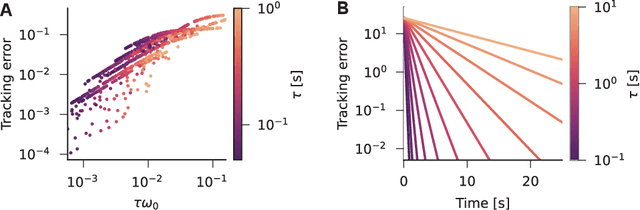
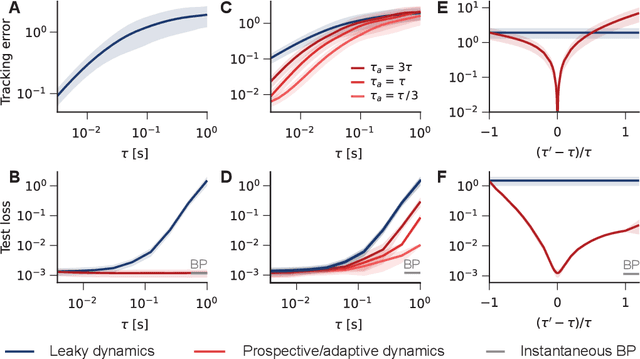
Working memory requires the brain to maintain information from the recent past to guide ongoing behavior. Neurons can contribute to this capacity by slowly integrating their inputs over time, creating persistent activity that outlasts the original stimulus. However, when these slowly integrating neurons are organized hierarchically, they introduce cumulative delays that create a fundamental challenge for learning: teaching signals that indicate whether behavior was correct or incorrect arrive out-of-sync with the neural activity they are meant to instruct. Here, we demonstrate that neurons enhanced with an adaptive current can compensate for these delays by responding to external stimuli prospectively -- effectively predicting future inputs to synchronize with them. First, we show that such prospective neurons enable teaching signal synchronization across a range of learning algorithms that propagate error signals through hierarchical networks. Second, we demonstrate that this successfully guides learning in slowly integrating neurons, enabling the formation and retrieval of memories over extended timescales. We support our findings with a mathematical analysis of the prospective coding mechanism and learning experiments on motor control tasks. Together, our results reveal how neural adaptation could solve a critical timing problem and enable efficient learning in dynamic environments.
Multihead self-attention in cortico-thalamic circuits
Apr 08, 2025Both biological cortico-thalamic networks and artificial transformer networks use canonical computations to perform a wide range of cognitive tasks. In this work, we propose that the structure of cortico-thalamic circuits is well suited to realize a computation analogous to multihead self-attention, the main algorithmic innovation of transformers. We start with the concept of a cortical unit module or microcolumn, and propose that superficial and deep pyramidal cells carry distinct computational roles. Specifically, superficial pyramidal cells encode an attention mask applied onto deep pyramidal cells to compute attention-modulated values. We show how to wire such microcolumns into a circuit equivalent to a single head of self-attention. We then suggest the parallel between one head of attention and a cortical area. On this basis, we show how to wire cortico-thalamic circuits to perform multihead self-attention. Along these constructions, we refer back to existing experimental data, and find noticeable correspondence. Finally, as a first step towards a mechanistic theory of synaptic learning in this framework, we derive formal gradients of a tokenwise mean squared error loss for a multihead linear self-attention block.
Order from chaos: Interplay of development and learning in recurrent networks of structured neurons
Feb 26, 2024



Behavior can be described as a temporal sequence of actions driven by neural activity. To learn complex sequential patterns in neural networks, memories of past activities need to persist on significantly longer timescales than relaxation times of single-neuron activity. While recurrent networks can produce such long transients, training these networks in a biologically plausible way is challenging. One approach has been reservoir computing, where only weights from a recurrent network to a readout are learned. Other models achieve learning of recurrent synaptic weights using propagated errors. However, their biological plausibility typically suffers from issues with locality, resource allocation or parameter scales and tuning. We suggest that many of these issues can be alleviated by considering dendritic information storage and computation. By applying a fully local, always-on plasticity rule we are able to learn complex sequences in a recurrent network comprised of two populations. Importantly, our model is resource-efficient, enabling the learning of complex sequences using only a small number of neurons. We demonstrate these features in a mock-up of birdsong learning, in which our networks first learn a long, non-Markovian sequence that they can then reproduce robustly despite external disturbances.
Precision estimation and second-order prediction errors in cortical circuits
Sep 27, 2023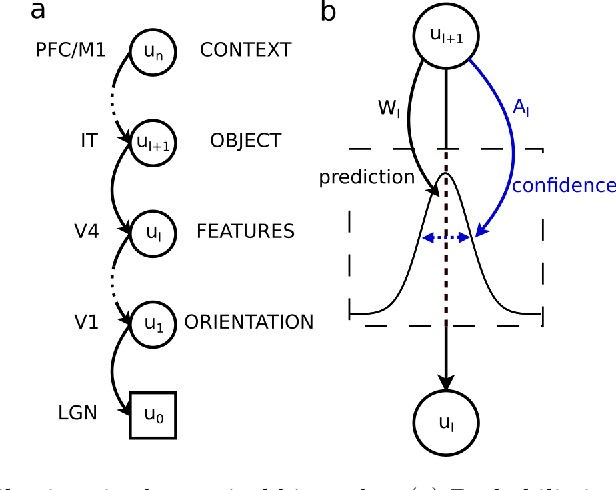
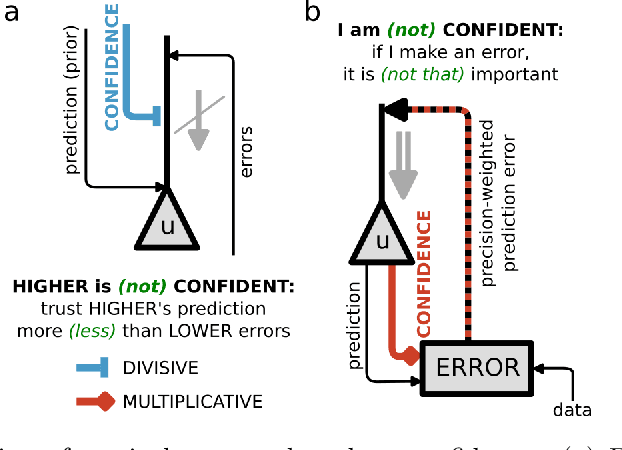
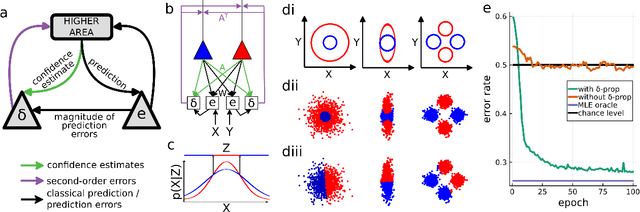
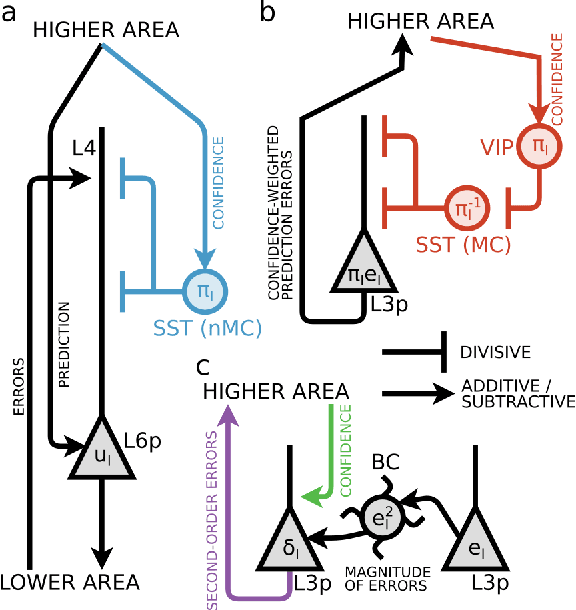
Minimization of cortical prediction errors is believed to be a key canonical computation of the cerebral cortex underlying perception, action and learning. However, it is still unclear how the cortex should form and use knowledge about uncertainty in this process of prediction error minimization. Here we derive neural dynamics minimizing prediction errors under the assumption that cortical areas must not only predict the activity in other areas and sensory streams, but also jointly estimate the precision of their predictions. This leads to a dynamic modulatory balancing of cortical streams based on context-dependent precision estimates. Moreover, the theory predicts the existence of second-order prediction errors, i.e. errors on precision estimates, computed and propagated through the cortical hierarchy alongside classical prediction errors. These second-order errors are used to learn weights of synapses responsible for precision estimation through an error-correcting synaptic learning rule. Finally, we propose a mapping of the theory to cortical circuitry.
Learning beyond sensations: how dreams organize neuronal representations
Aug 03, 2023


Semantic representations in higher sensory cortices form the basis for robust, yet flexible behavior. These representations are acquired over the course of development in an unsupervised fashion and continuously maintained over an organism's lifespan. Predictive learning theories propose that these representations emerge from predicting or reconstructing sensory inputs. However, brains are known to generate virtual experiences, such as during imagination and dreaming, that go beyond previously experienced inputs. Here, we suggest that virtual experiences may be just as relevant as actual sensory inputs in shaping cortical representations. In particular, we discuss two complementary learning principles that organize representations through the generation of virtual experiences. First, "adversarial dreaming" proposes that creative dreams support a cortical implementation of adversarial learning in which feedback and feedforward pathways engage in a productive game of trying to fool each other. Second, "contrastive dreaming" proposes that the invariance of neuronal representations to irrelevant factors of variation is acquired by trying to map similar virtual experiences together via a contrastive learning process. These principles are compatible with known cortical structure and dynamics and the phenomenology of sleep thus providing promising directions to explain cortical learning beyond the classical predictive learning paradigm.
Learning efficient backprojections across cortical hierarchies in real time
Dec 20, 2022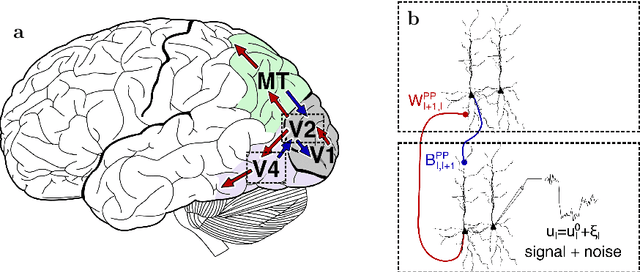
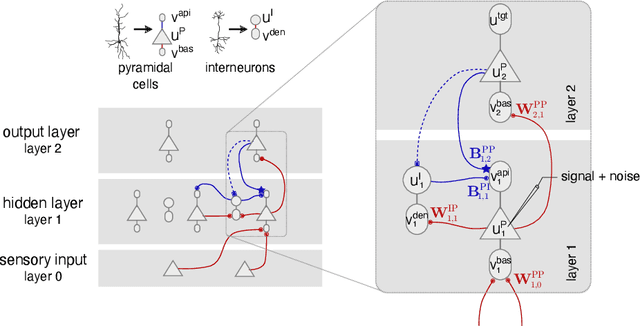
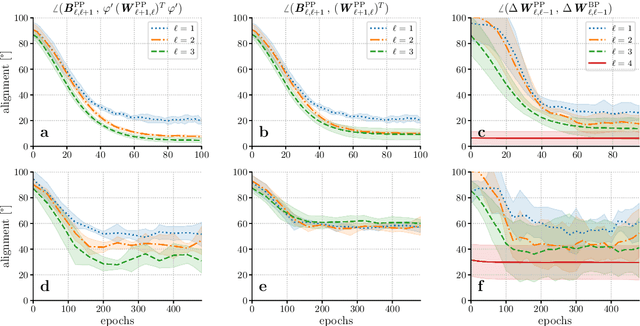
Models of sensory processing and learning in the cortex need to efficiently assign credit to synapses in all areas. In deep learning, a known solution is error backpropagation, which however requires biologically implausible weight transport from feed-forward to feedback paths. We introduce Phaseless Alignment Learning (PAL), a bio-plausible method to learn efficient feedback weights in layered cortical hierarchies. This is achieved by exploiting the noise naturally found in biophysical systems as an additional carrier of information. In our dynamical system, all weights are learned simultaneously with always-on plasticity and using only information locally available to the synapses. Our method is completely phase-free (no forward and backward passes or phased learning) and allows for efficient error propagation across multi-layer cortical hierarchies, while maintaining biologically plausible signal transport and learning. Our method is applicable to a wide class of models and improves on previously known biologically plausible ways of credit assignment: compared to random synaptic feedback, it can solve complex tasks with less neurons and learn more useful latent representations. We demonstrate this on various classification tasks using a cortical microcircuit model with prospective coding.
Latent Equilibrium: A unified learning theory for arbitrarily fast computation with arbitrarily slow neurons
Oct 27, 2021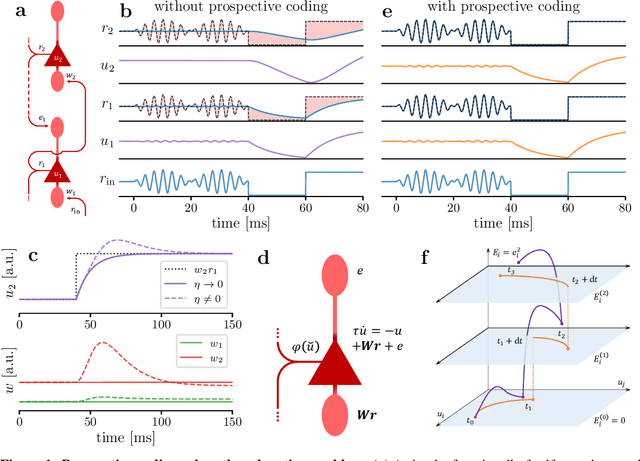
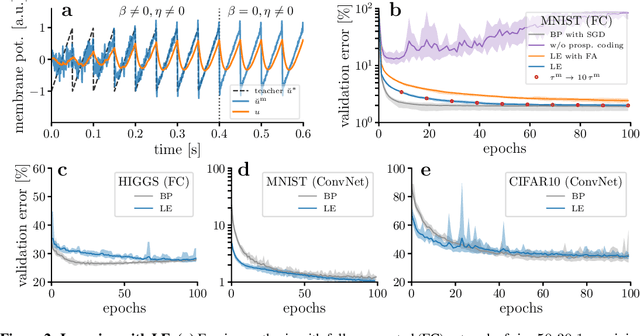

The response time of physical computational elements is finite, and neurons are no exception. In hierarchical models of cortical networks each layer thus introduces a response lag. This inherent property of physical dynamical systems results in delayed processing of stimuli and causes a timing mismatch between network output and instructive signals, thus afflicting not only inference, but also learning. We introduce Latent Equilibrium, a new framework for inference and learning in networks of slow components which avoids these issues by harnessing the ability of biological neurons to phase-advance their output with respect to their membrane potential. This principle enables quasi-instantaneous inference independent of network depth and avoids the need for phased plasticity or computationally expensive network relaxation phases. We jointly derive disentangled neuron and synapse dynamics from a prospective energy function that depends on a network's generalized position and momentum. The resulting model can be interpreted as a biologically plausible approximation of error backpropagation in deep cortical networks with continuous-time, leaky neuronal dynamics and continuously active, local plasticity. We demonstrate successful learning of standard benchmark datasets, achieving competitive performance using both fully-connected and convolutional architectures, and show how our principle can be applied to detailed models of cortical microcircuitry. Furthermore, we study the robustness of our model to spatio-temporal substrate imperfections to demonstrate its feasibility for physical realization, be it in vivo or in silico.
Memory semantization through perturbed and adversarial dreaming
Sep 09, 2021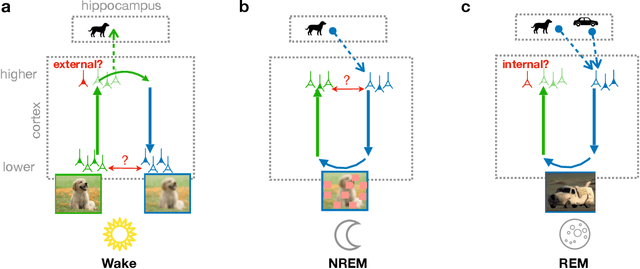

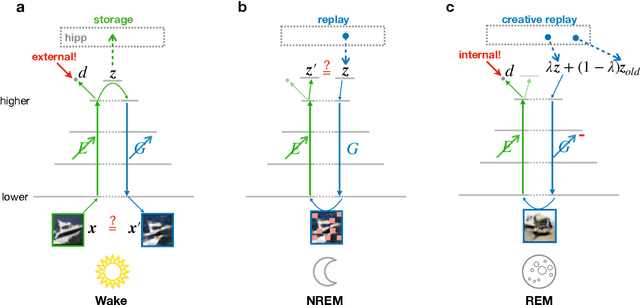
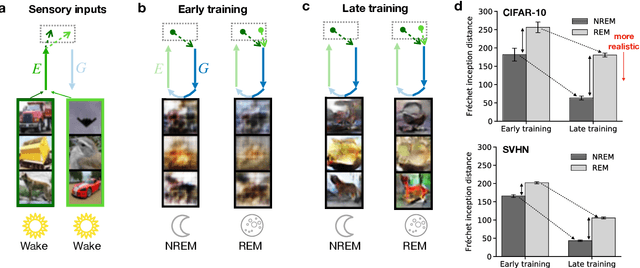
Classical theories of memory consolidation emphasize the importance of replay in extracting semantic information from episodic memories. However, the characteristic creative nature of dreams suggests that memory semantization may go beyond merely replaying previous experiences. We propose that rapid-eye-movement (REM) dreaming is essential for efficient memory semantization by randomly combining episodic memories to create new, virtual sensory experiences. We support this hypothesis by implementing a cortical architecture with hierarchically organized feedforward and feedback pathways, inspired by generative adversarial networks (GANs). Learning in our model is organized across three different global brain states mimicking wakefulness, non-REM (NREM) and REM sleep, optimizing different, but complementary objective functions. We train the model in an unsupervised fashion on standard datasets of natural images and evaluate the quality of the learned representations. Our results suggest that adversarial dreaming during REM sleep is essential for extracting memory contents, while perturbed dreaming during NREM sleep improves robustness of the latent representation to noisy sensory inputs. The model provides a new computational perspective on sleep states, memory replay and dreams and suggests a cortical implementation of GANs.
Evolving Neuronal Plasticity Rules using Cartesian Genetic Programming
Feb 08, 2021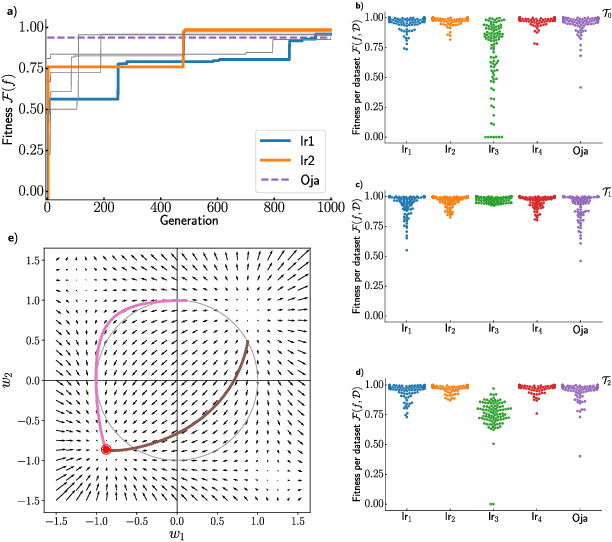
We formulate the search for phenomenological models of synaptic plasticity as an optimization problem. We employ Cartesian genetic programming to evolve biologically plausible human-interpretable plasticity rules that allow a given network to successfully solve tasks from specific task families. While our evolving-to-learn approach can be applied to various learning paradigms, here we illustrate its power by evolving plasticity rules that allow a network to efficiently determine the first principal component of its input distribution. We demonstrate that the evolved rules perform competitively with known hand-designed solutions. We explore how the statistical properties of the datasets used during the evolutionary search influences the form of the plasticity rules and discover new rules which are adapted to the structure of the corresponding datasets.