 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmulating insect brains for neuromorphic navigation
Dec 31, 2023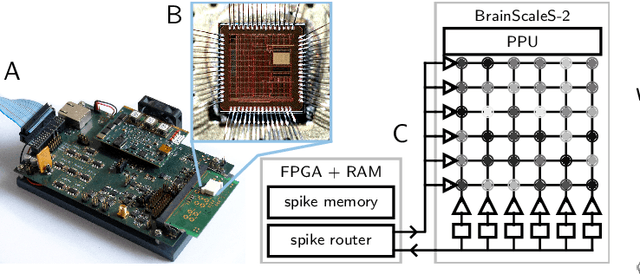
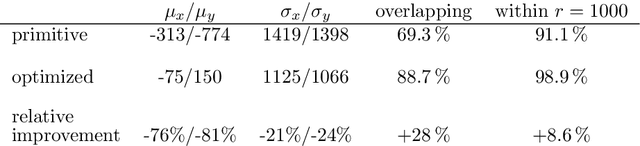
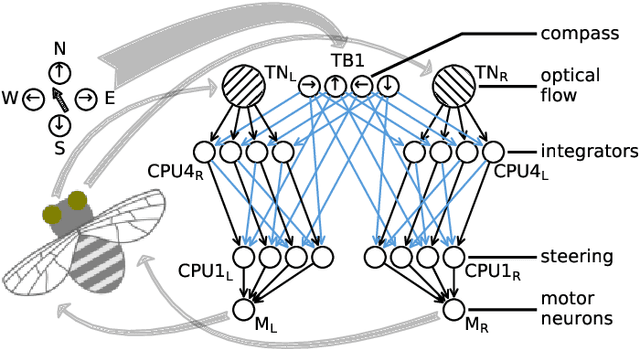
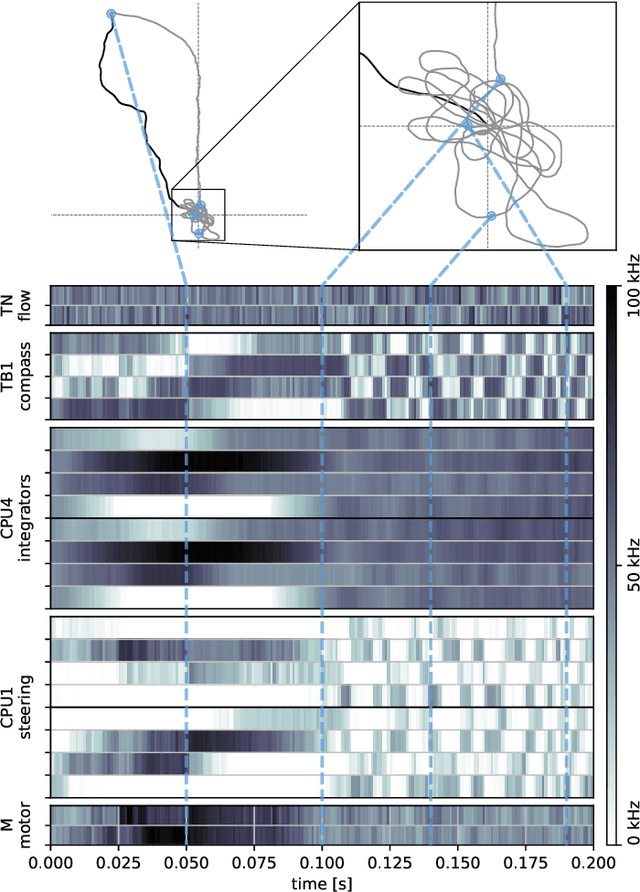
Bees display the remarkable ability to return home in a straight line after meandering excursions to their environment. Neurobiological imaging studies have revealed that this capability emerges from a path integration mechanism implemented within the insect's brain. In the present work, we emulate this neural network on the neuromorphic mixed-signal processor BrainScaleS-2 to guide bees, virtually embodied on a digital co-processor, back to their home location after randomly exploring their environment. To realize the underlying neural integrators, we introduce single-neuron spike-based short-term memory cells with axo-axonic synapses. All entities, including environment, sensory organs, brain, actuators, and the virtual body, run autonomously on a single BrainScaleS-2 microchip. The functioning network is fine-tuned for better precision and reliability through an evolution strategy. As BrainScaleS-2 emulates neural processes 1000 times faster than biology, 4800 consecutive bee journeys distributed over 320 generations occur within only half an hour on a single neuromorphic core.
Versatile emulation of spiking neural networks on an accelerated neuromorphic substrate
Dec 30, 2019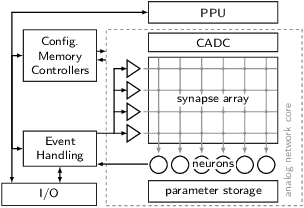
We present first experimental results on the novel BrainScaleS-2 neuromorphic architecture based on an analog neuro-synaptic core and augmented by embedded microprocessors for complex plasticity and experiment control. The high acceleration factor of 1000 compared to biological dynamics enables the execution of computationally expensive tasks, by allowing the fast emulation of long-duration experiments or rapid iteration over many consecutive trials. The flexibility of our architecture is demonstrated in a suite of five distinct experiments, which emphasize different aspects of the BrainScaleS-2 system.
Structural plasticity on an accelerated analog neuromorphic hardware system
Dec 27, 2019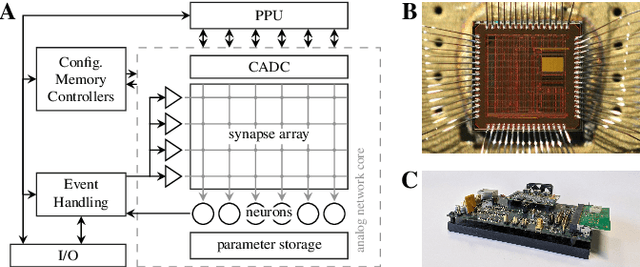
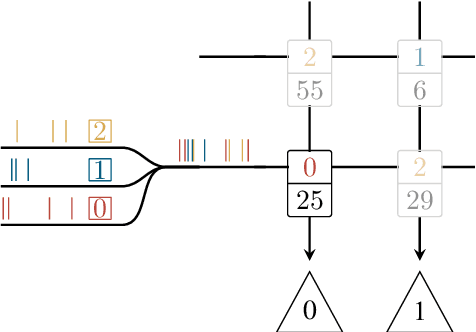
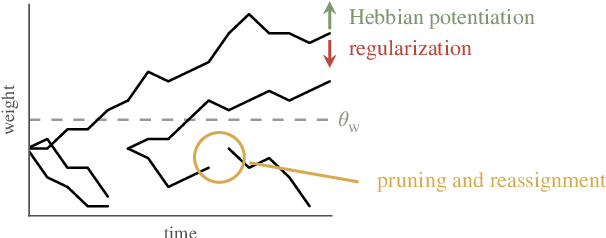
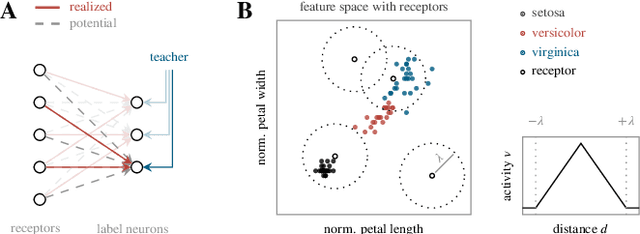
In computational neuroscience, as well as in machine learning, neuromorphic devices promise an accelerated and scalable alternative to neural network simulations. Their neural connectivity and synaptic capacity depends on their specific design choices, but is always intrinsically limited. Here, we present a strategy to achieve structural plasticity that optimizes resource allocation under these constraints by constantly rewiring the pre- and postsynaptic partners while keeping the neuronal fan-in constant and the connectome sparse. In our implementation, the algorithm is executed on a custom embedded digital processor that accompanies a mixed-signal substrate consisting of spiking neurons and synapse circuits. We evaluated our proposed algorithm in a simple supervised learning scenario, showing its ability to optimize the network topology with respect to the nature of its training data, as well as its overall computational efficiency.
Fast and deep neuromorphic learning with time-to-first-spike coding
Dec 24, 2019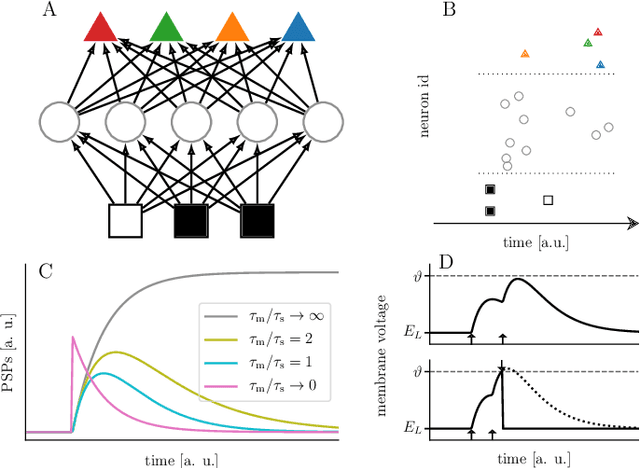
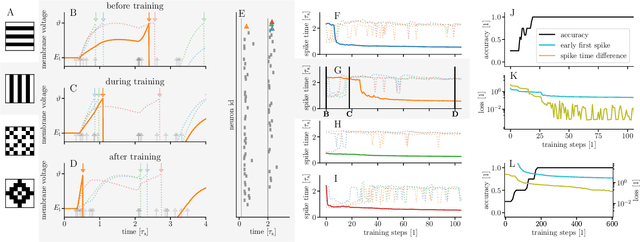
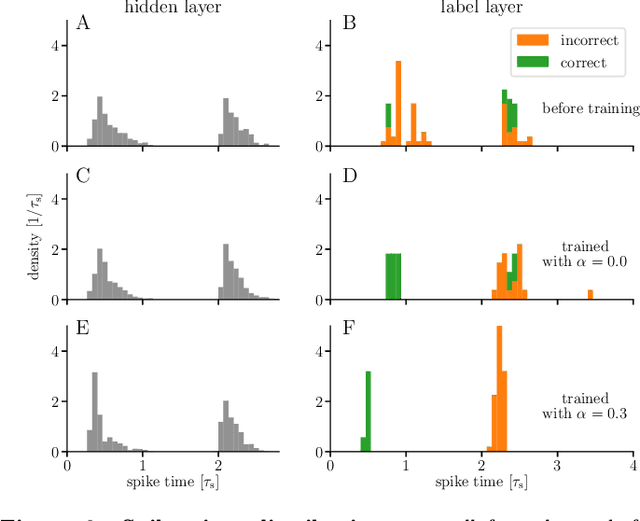
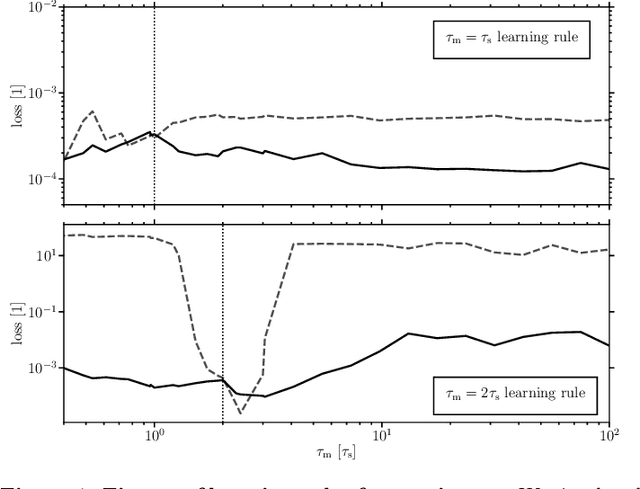
For a biological agent operating under environmental pressure, energy consumption and reaction times are of critical importance. Similarly, engineered systems also strive for short time-to-solution and low energy-to-solution characteristics. At the level of neuronal implementation, this implies achieving the desired results with as few and as early spikes as possible. In the time-to-first-spike coding framework, both of these goals are inherently emerging features of learning. Here, we describe a rigorous derivation of error-backpropagation-based learning for hierarchical networks of leaky integrate-and-fire neurons. We explicitly address two issues that are relevant for both biological plausibility and applicability to neuromorphic substrates by incorporating dynamics with finite time constants and by optimizing the backward pass with respect to substrate variability. This narrows the gap between previous models of first-spike-time learning and biological neuronal dynamics, thereby also enabling fast and energy-efficient inference on analog neuromorphic devices that inherit these dynamics from their biological archetypes, which we demonstrate on two generations of the BrainScaleS analog neuromorphic architecture.
Neuromorphic Hardware learns to learn
Mar 18, 2019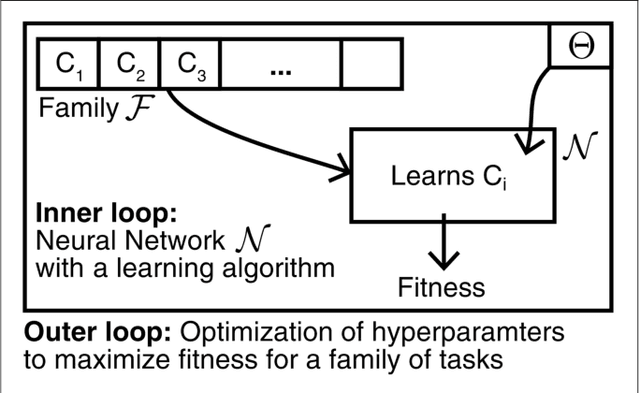

Hyperparameters and learning algorithms for neuromorphic hardware are usually chosen by hand. In contrast, the hyperparameters and learning algorithms of networks of neurons in the brain, which they aim to emulate, have been optimized through extensive evolutionary and developmental processes for specific ranges of computing and learning tasks. Occasionally this process has been emulated through genetic algorithms, but these require themselves hand-design of their details and tend to provide a limited range of improvements. We employ instead other powerful gradient-free optimization tools, such as cross-entropy methods and evolutionary strategies, in order to port the function of biological optimization processes to neuromorphic hardware. As an example, we show that this method produces neuromorphic agents that learn very efficiently from rewards. In particular, meta-plasticity, i.e., the optimization of the learning rule which they use, substantially enhances reward-based learning capability of the hardware. In addition, we demonstrate for the first time Learning-to-Learn benefits from such hardware, in particular, the capability to extract abstract knowledge from prior learning experiences that speeds up the learning of new but related tasks. Learning-to-Learn is especially suited for accelerated neuromorphic hardware, since it makes it feasible to carry out the required very large number of network computations.
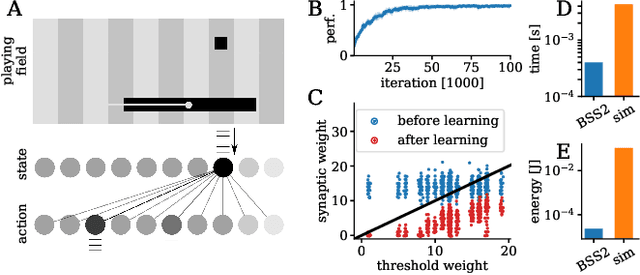
Demonstrating Advantages of Neuromorphic Computation: A Pilot Study
Nov 29, 2018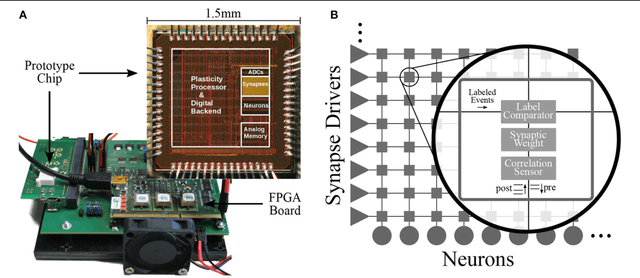
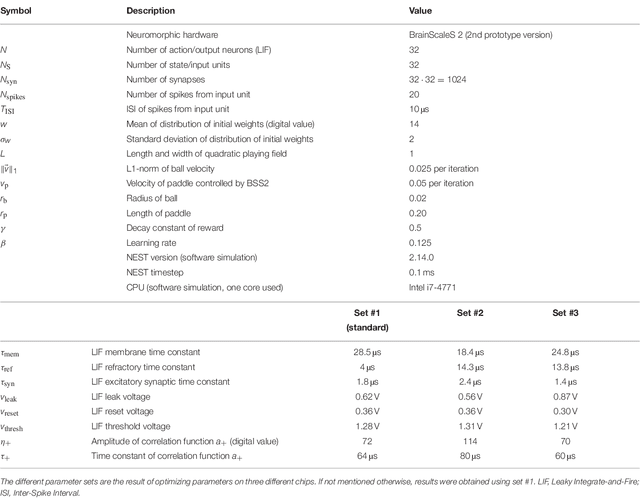
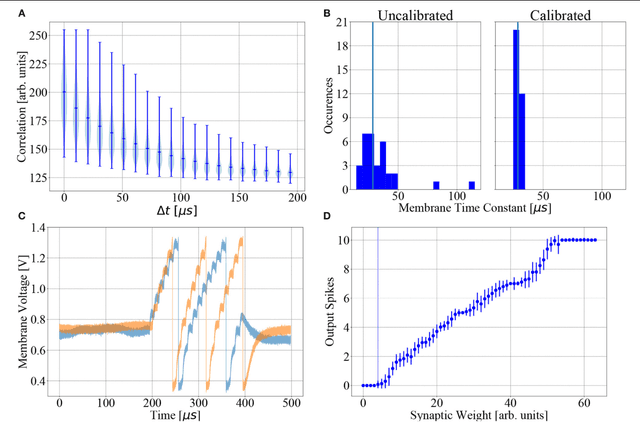
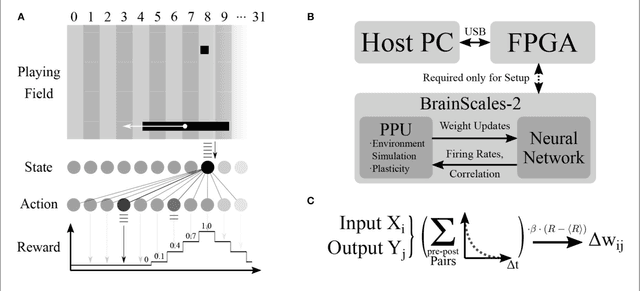
Neuromorphic devices represent an attempt to mimic aspects of the brain's architecture and dynamics with the aim of replicating its hallmark functional capabilities in terms of computational power, robust learning and energy efficiency. We employ a single-chip prototype of the BrainScaleS 2 neuromorphic system to implement a proof-of-concept demonstration of reward-modulated spike-timing-dependent plasticity in a spiking network that learns to play the Pong video game by smooth pursuit. This system combines an electronic mixed-signal substrate for emulating neuron and synapse dynamics with an embedded digital processor for on-chip learning, which in this work also serves to simulate the virtual environment and learning agent. The analog emulation of neuronal membrane dynamics enables a 1000-fold acceleration with respect to biological real-time, with the entire chip operating on a power budget of 57mW. Compared to an equivalent simulation using state-of-the-art software, the on-chip emulation is at least one order of magnitude faster and three orders of magnitude more energy-efficient. We demonstrate how on-chip learning can mitigate the effects of fixed-pattern noise, which is unavoidable in analog substrates, while making use of temporal variability for action exploration. Learning compensates imperfections of the physical substrate, as manifested in neuronal parameter variability, by adapting synaptic weights to match respective excitability of individual neurons.
Stochasticity from function - why the Bayesian brain may need no noise
Sep 21, 2018
An increasing body of evidence suggests that the trial-to-trial variability of spiking activity in the brain is not mere noise, but rather the reflection of a sampling-based encoding scheme for probabilistic computing. Since the precise statistical properties of neural activity are important in this context, many models assume an ad-hoc source of well-behaved, explicit noise, either on the input or on the output side of single neuron dynamics, most often assuming an independent Poisson process in either case. However, these assumptions are somewhat problematic: neighboring neurons tend to share receptive fields, rendering both their input and their output correlated; at the same time, neurons are known to behave largely deterministically, as a function of their membrane potential and conductance. We suggest that spiking neural networks may, in fact, have no need for noise to perform sampling-based Bayesian inference. We study analytically the effect of auto- and cross-correlations in functionally Bayesian spiking networks and demonstrate how their effect translates to synaptic interaction strengths, rendering them controllable through synaptic plasticity. This allows even small ensembles of interconnected deterministic spiking networks to simultaneously and co-dependently shape their output activity through learning, enabling them to perform complex Bayesian computation without any need for noise, which we demonstrate in silico, both in classical simulation and in neuromorphic emulation. These results close a gap between the abstract models and the biology of functionally Bayesian spiking networks, effectively reducing the architectural constraints imposed on physical neural substrates required to perform probabilistic computing, be they biological or artificial.
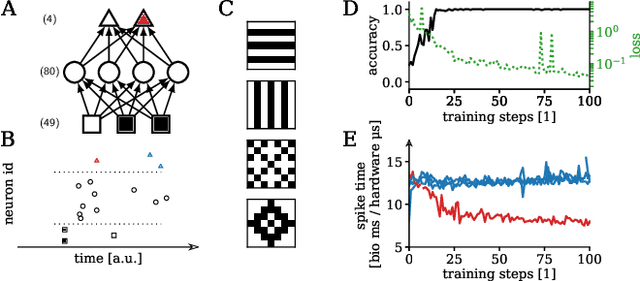
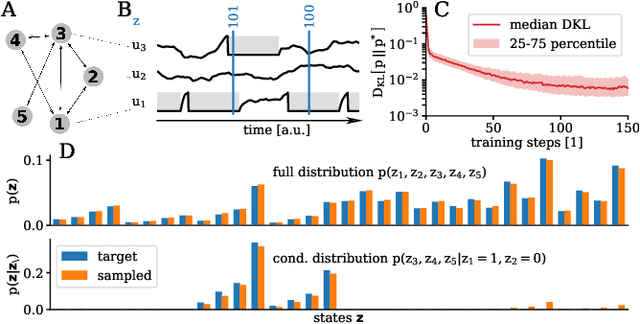
Generative models on accelerated neuromorphic hardware
Jul 11, 2018
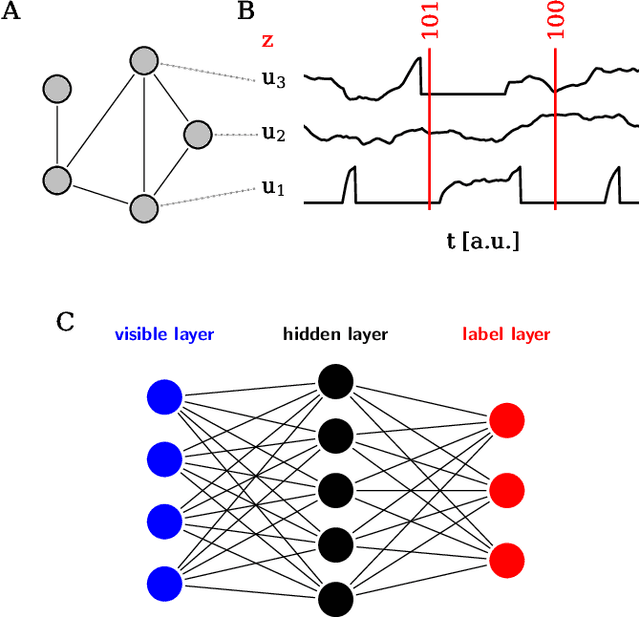
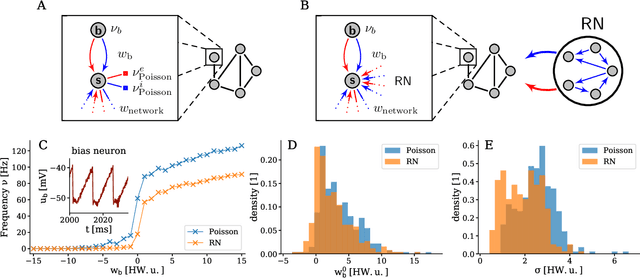
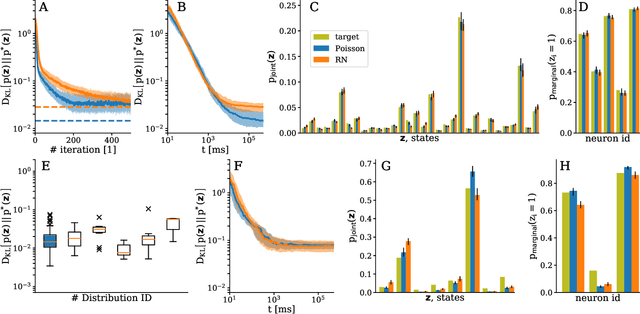
The traditional von Neumann computer architecture faces serious obstacles, both in terms of miniaturization and in terms of heat production, with increasing performance. Artificial neural (neuromorphic) substrates represent an alternative approach to tackle this challenge. A special subset of these systems follow the principle of "physical modeling" as they directly use the physical properties of the underlying substrate to realize computation with analog components. While these systems are potentially faster and/or more energy efficient than conventional computers, they require robust models that can cope with their inherent limitations in terms of controllability and range of parameters. A natural source of inspiration for robust models is neuroscience as the brain faces similar challenges. It has been recently suggested that sampling with the spiking dynamics of neurons is potentially suitable both as a generative and a discriminative model for artificial neural substrates. In this work we present the implementation of sampling with leaky integrate-and-fire neurons on the BrainScaleS physical model system. We prove the sampling property of the network and demonstrate its applicability to high-dimensional datasets. The required stochasticity is provided by a spiking random network on the same substrate. This allows the system to run in a self-contained fashion without external stochastic input from the host environment. The implementation provides a basis as a building block in large-scale biologically relevant emulations, as a fast approximate sampler or as a framework to realize on-chip learning on (future generations of) accelerated spiking neuromorphic hardware. Our work contributes to the development of robust computation on physical model systems.
Full Wafer Redistribution and Wafer Embedding as Key Technologies for a Multi-Scale Neuromorphic Hardware Cluster
Jan 15, 2018

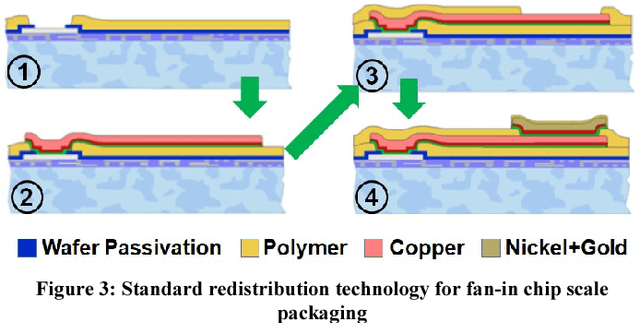
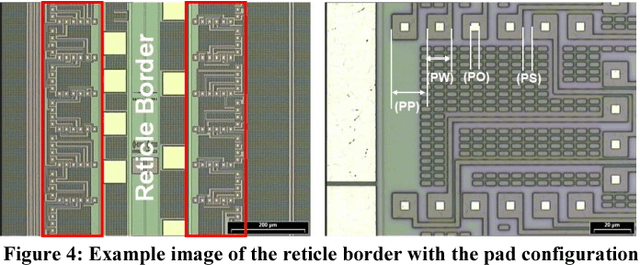
Together with the Kirchhoff-Institute for Physics(KIP) the Fraunhofer IZM has developed a full wafer redistribution and embedding technology as base for a large-scale neuromorphic hardware system. The paper will give an overview of the neuromorphic computing platform at the KIP and the associated hardware requirements which drove the described technological developments. In the first phase of the project standard redistribution technologies from wafer level packaging were adapted to enable a high density reticle-to-reticle routing on 200mm CMOS wafers. Neighboring reticles were interconnected across the scribe lines with an 8{\mu}m pitch routing based on semi-additive copper metallization. Passivation by photo sensitive benzocyclobutene was used to enable a second intra-reticle routing layer. Final IO pads with flash gold were generated on top of each reticle. With that concept neuromorphic systems based on full wafers could be assembled and tested. The fabricated high density inter-reticle routing revealed a very high yield of larger than 99.9%. In order to allow an upscaling of the system size to a large number of wafers with feasible effort a full wafer embedding concept for printed circuit boards was developed and proven in the second phase of the project. The wafers were thinned to 250{\mu}m and laminated with additional prepreg layers and copper foils into a core material. After lamination of the PCB panel the reticle IOs of the embedded wafer were accessed by micro via drilling, copper electroplating, lithography and subtractive etching of the PCB wiring structure. The created wiring with 50um line width enabled an access of the reticle IOs on the embedded wafer as well as a board level routing. The panels with the embedded wafers were subsequently stressed with up to 1000 thermal cycles between 0C and 100C and have shown no severe failure formation over the cycle time.
Spiking neurons with short-term synaptic plasticity form superior generative networks
Oct 10, 2017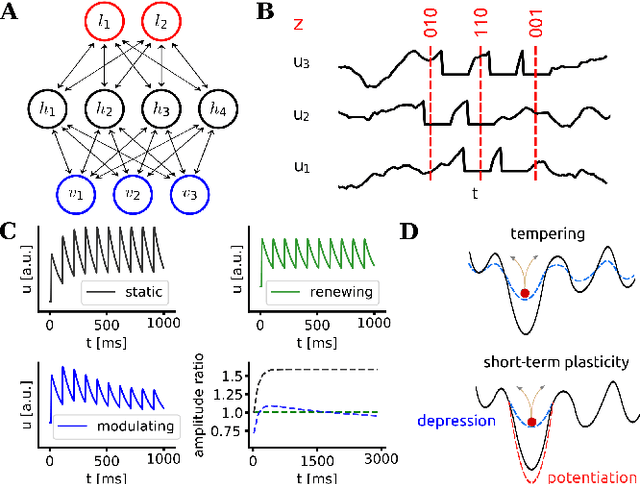

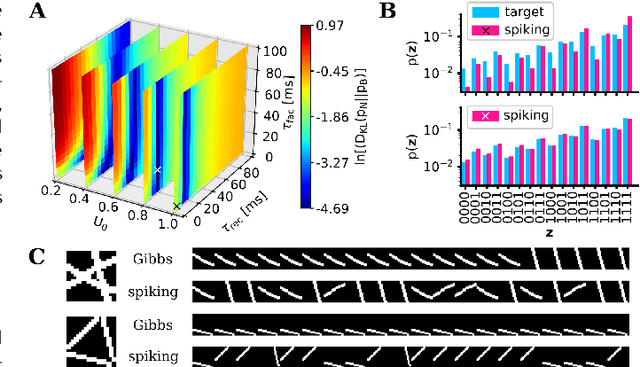
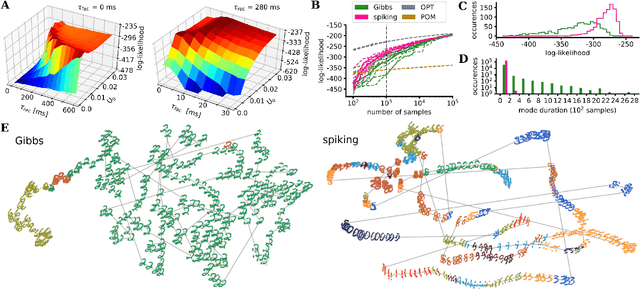
Spiking networks that perform probabilistic inference have been proposed both as models of cortical computation and as candidates for solving problems in machine learning. However, the evidence for spike-based computation being in any way superior to non-spiking alternatives remains scarce. We propose that short-term plasticity can provide spiking networks with distinct computational advantages compared to their classical counterparts. In this work, we use networks of leaky integrate-and-fire neurons that are trained to perform both discriminative and generative tasks in their forward and backward information processing paths, respectively. During training, the energy landscape associated with their dynamics becomes highly diverse, with deep attractor basins separated by high barriers. Classical algorithms solve this problem by employing various tempering techniques, which are both computationally demanding and require global state updates. We demonstrate how similar results can be achieved in spiking networks endowed with local short-term synaptic plasticity. Additionally, we discuss how these networks can even outperform tempering-based approaches when the training data is imbalanced. We thereby show how biologically inspired, local, spike-triggered synaptic dynamics based simply on a limited pool of synaptic resources can allow spiking networks to outperform their non-spiking relatives.