 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWalking the Weight Manifold: a Topological Approach to Conditioning Inspired by Neuromodulation
May 29, 2025One frequently wishes to learn a range of similar tasks as efficiently as possible, re-using knowledge across tasks. In artificial neural networks, this is typically accomplished by conditioning a network upon task context by injecting context as input. Brains have a different strategy: the parameters themselves are modulated as a function of various neuromodulators such as serotonin. Here, we take inspiration from neuromodulation and propose to learn weights which are smoothly parameterized functions of task context variables. Rather than optimize a weight vector, i.e. a single point in weight space, we optimize a smooth manifold in weight space with a predefined topology. To accomplish this, we derive a formal treatment of optimization of manifolds as the minimization of a loss functional subject to a constraint on volumetric movement, analogous to gradient descent. During inference, conditioning selects a single point on this manifold which serves as the effective weight matrix for a particular sub-task. This strategy for conditioning has two main advantages. First, the topology of the manifold (whether a line, circle, or torus) is a convenient lever for inductive biases about the relationship between tasks. Second, learning in one state smoothly affects the entire manifold, encouraging generalization across states. To verify this, we train manifolds with several topologies, including straight lines in weight space (for conditioning on e.g. noise level in input data) and ellipses (for rotated images). Despite their simplicity, these parameterizations outperform conditioning identical networks by input concatenation and better generalize to out-of-distribution samples. These results suggest that modulating weights over low-dimensional manifolds offers a principled and effective alternative to traditional conditioning.
Continual learning with the neural tangent ensemble
Aug 30, 2024A natural strategy for continual learning is to weigh a Bayesian ensemble of fixed functions. This suggests that if a (single) neural network could be interpreted as an ensemble, one could design effective algorithms that learn without forgetting. To realize this possibility, we observe that a neural network classifier with N parameters can be interpreted as a weighted ensemble of N classifiers, and that in the lazy regime limit these classifiers are fixed throughout learning. We term these classifiers the neural tangent experts and show they output valid probability distributions over the labels. We then derive the likelihood and posterior probability of each expert given past data. Surprisingly, we learn that the posterior updates for these experts are equivalent to a scaled and projected form of stochastic gradient descent (SGD) over the network weights. Away from the lazy regime, networks can be seen as ensembles of adaptive experts which improve over time. These results offer a new interpretation of neural networks as Bayesian ensembles of experts, providing a principled framework for understanding and mitigating catastrophic forgetting in continual learning settings.
jaxsnn: Event-driven Gradient Estimation for Analog Neuromorphic Hardware
Jan 30, 2024Traditional neuromorphic hardware architectures rely on event-driven computation, where the asynchronous transmission of events, such as spikes, triggers local computations within synapses and neurons. While machine learning frameworks are commonly used for gradient-based training, their emphasis on dense data structures poses challenges for processing asynchronous data such as spike trains. This problem is particularly pronounced for typical tensor data structures. In this context, we present a novel library (jaxsnn) built on top of JAX, that departs from conventional machine learning frameworks by providing flexibility in the data structures used and the handling of time, while maintaining Autograd functionality and composability. Our library facilitates the simulation of spiking neural networks and gradient estimation, with a focus on compatibility with time-continuous neuromorphic backends, such as the BrainScaleS-2 system, during the forward pass. This approach opens avenues for more efficient and flexible training of spiking neural networks, bridging the gap between traditional neuromorphic architectures and contemporary machine learning frameworks.
Emulating insect brains for neuromorphic navigation
Dec 31, 2023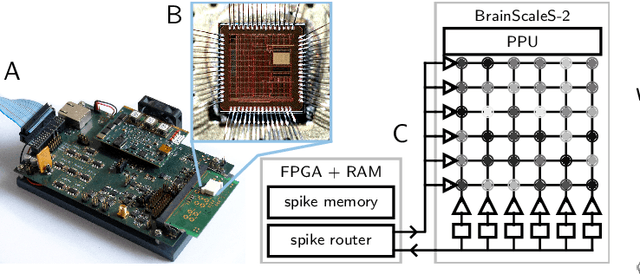
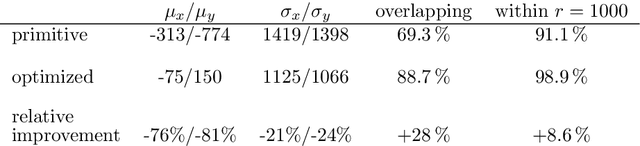
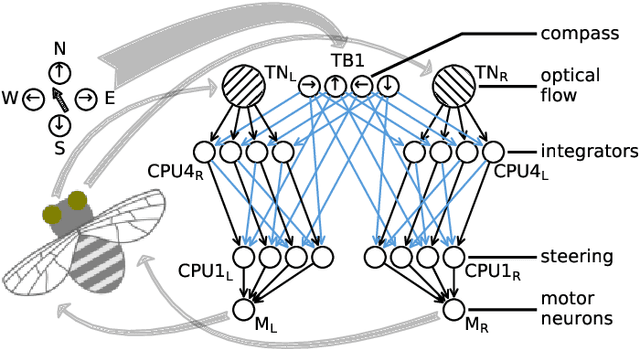
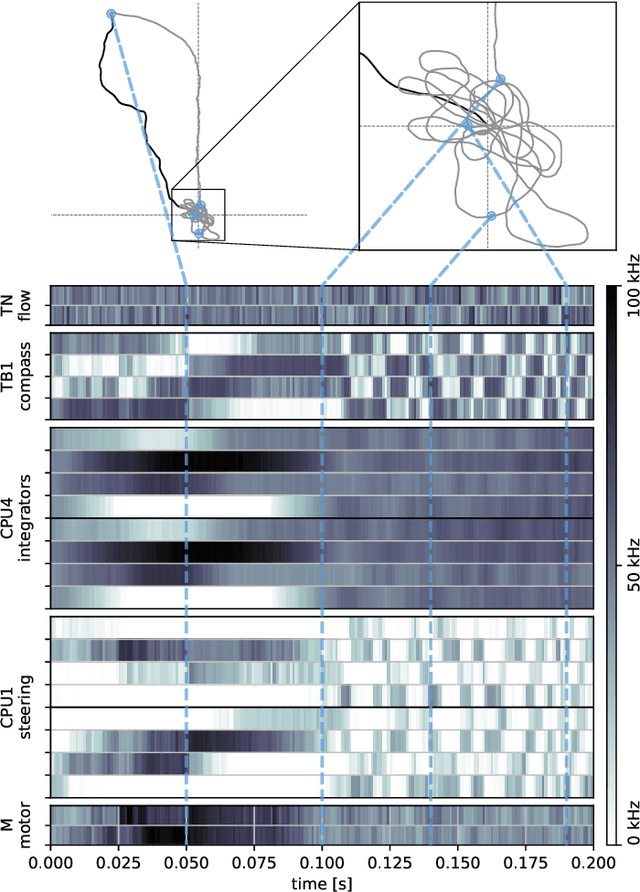
Bees display the remarkable ability to return home in a straight line after meandering excursions to their environment. Neurobiological imaging studies have revealed that this capability emerges from a path integration mechanism implemented within the insect's brain. In the present work, we emulate this neural network on the neuromorphic mixed-signal processor BrainScaleS-2 to guide bees, virtually embodied on a digital co-processor, back to their home location after randomly exploring their environment. To realize the underlying neural integrators, we introduce single-neuron spike-based short-term memory cells with axo-axonic synapses. All entities, including environment, sensory organs, brain, actuators, and the virtual body, run autonomously on a single BrainScaleS-2 microchip. The functioning network is fine-tuned for better precision and reliability through an evolution strategy. As BrainScaleS-2 emulates neural processes 1000 times faster than biology, 4800 consecutive bee journeys distributed over 320 generations occur within only half an hour on a single neuromorphic core.
NeuroBench: Advancing Neuromorphic Computing through Collaborative, Fair and Representative Benchmarking
Apr 15, 2023



The field of neuromorphic computing holds great promise in terms of advancing computing efficiency and capabilities by following brain-inspired principles. However, the rich diversity of techniques employed in neuromorphic research has resulted in a lack of clear standards for benchmarking, hindering effective evaluation of the advantages and strengths of neuromorphic methods compared to traditional deep-learning-based methods. This paper presents a collaborative effort, bringing together members from academia and the industry, to define benchmarks for neuromorphic computing: NeuroBench. The goals of NeuroBench are to be a collaborative, fair, and representative benchmark suite developed by the community, for the community. In this paper, we discuss the challenges associated with benchmarking neuromorphic solutions, and outline the key features of NeuroBench. We believe that NeuroBench will be a significant step towards defining standards that can unify the goals of neuromorphic computing and drive its technological progress. Please visit neurobench.ai for the latest updates on the benchmark tasks and metrics.
Event-based Backpropagation for Analog Neuromorphic Hardware
Feb 13, 2023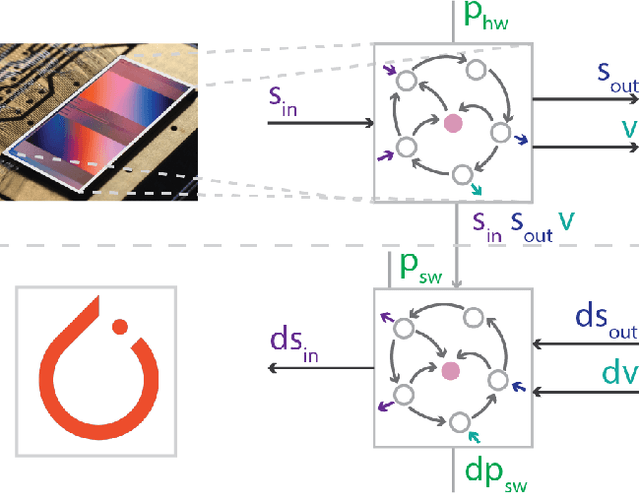

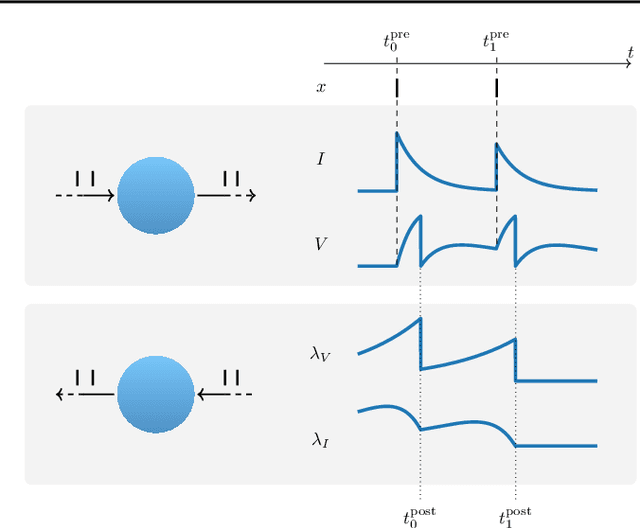

Neuromorphic computing aims to incorporate lessons from studying biological nervous systems in the design of computer architectures. While existing approaches have successfully implemented aspects of those computational principles, such as sparse spike-based computation, event-based scalable learning has remained an elusive goal in large-scale systems. However, only then the potential energy-efficiency advantages of neuromorphic systems relative to other hardware architectures can be realized during learning. We present our progress implementing the EventProp algorithm using the example of the BrainScaleS-2 analog neuromorphic hardware. Previous gradient-based approaches to learning used "surrogate gradients" and dense sampling of observables or were limited by assumptions on the underlying dynamics and loss functions. In contrast, our approach only needs spike time observations from the system while being able to incorporate other system observables, such as membrane voltage measurements, in a principled way. This leads to a one-order-of-magnitude improvement in the information efficiency of the gradient estimate, which would directly translate to corresponding energy efficiency improvements in an optimized hardware implementation. We present the theoretical framework for estimating gradients and results verifying the correctness of the estimation, as well as results on a low-dimensional classification task using the BrainScaleS-2 system. Building on this work has the potential to enable scalable gradient estimation in large-scale neuromorphic hardware as a continuous measurement of the system state would be prohibitive and energy-inefficient in such instances. It also suggests the feasibility of a full on-device implementation of the algorithm that would enable scalable, energy-efficient, event-based learning in large-scale analog neuromorphic hardware.
hxtorch.snn: Machine-learning-inspired Spiking Neural Network Modeling on BrainScaleS-2
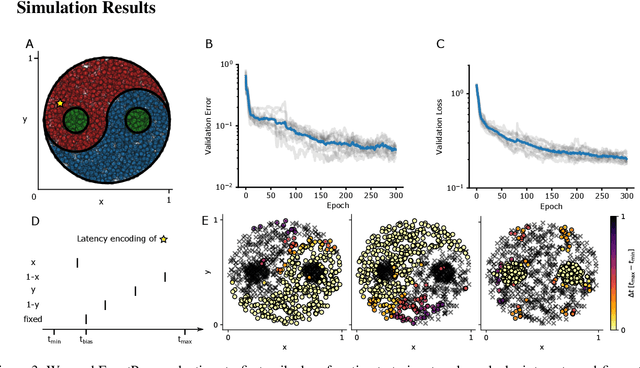
Dec 23, 2022Neuromorphic systems require user-friendly software to support the design and optimization of experiments. In this work, we address this need by presenting our development of a machine learning-based modeling framework for the BrainScaleS-2 neuromorphic system. This work represents an improvement over previous efforts, which either focused on the matrix-multiplication mode of BrainScaleS-2 or lacked full automation. Our framework, called hxtorch.snn, enables the hardware-in-the-loop training of spiking neural networks within PyTorch, including support for auto differentiation in a fully-automated hardware experiment workflow. In addition, hxtorch.snn facilitates seamless transitions between emulating on hardware and simulating in software. We demonstrate the capabilities of hxtorch.snn on a classification task using the Yin-Yang dataset employing a gradient-based approach with surrogate gradients and densely sampled membrane observations from the BrainScaleS-2 hardware system.
A Scalable Approach to Modeling on Accelerated Neuromorphic Hardware
Mar 21, 2022
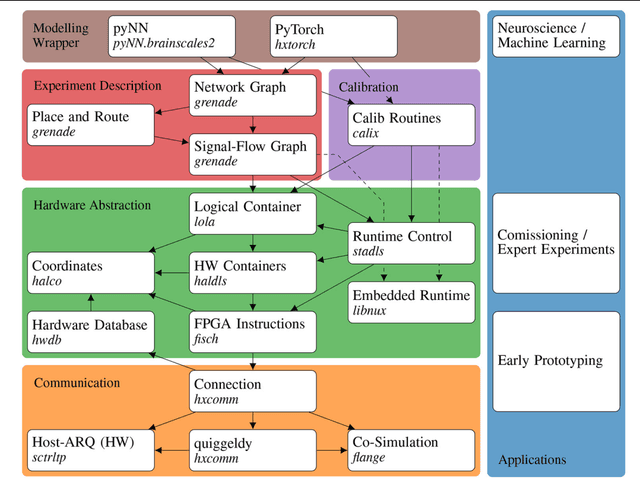
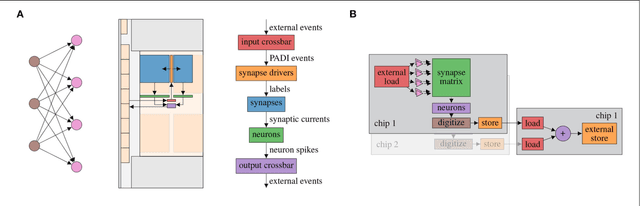
Neuromorphic systems open up opportunities to enlarge the explorative space for computational research. However, it is often challenging to unite efficiency and usability. This work presents the software aspects of this endeavor for the BrainScaleS-2 system, a hybrid accelerated neuromorphic hardware architecture based on physical modeling. We introduce key aspects of the BrainScaleS-2 Operating System: experiment workflow, API layering, software design, and platform operation. We present use cases to discuss and derive requirements for the software and showcase the implementation. The focus lies on novel system and software features such as multi-compartmental neurons, fast re-configuration for hardware-in-the-loop training, applications for the embedded processors, the non-spiking operation mode, interactive platform access, and sustainable hardware/software co-development. Finally, we discuss further developments in terms of hardware scale-up, system usability and efficiency.
The BrainScaleS-2 accelerated neuromorphic system with hybrid plasticity
Feb 03, 2022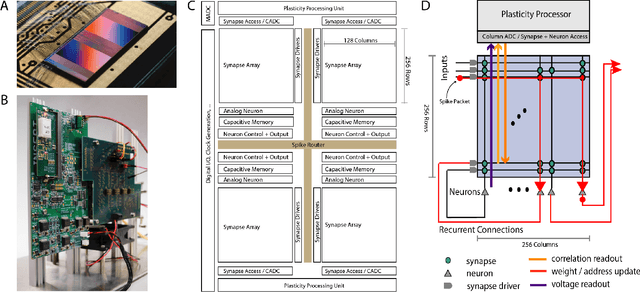
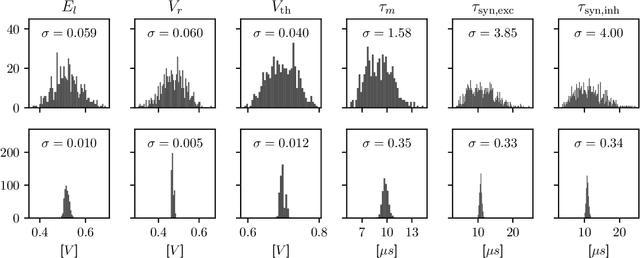
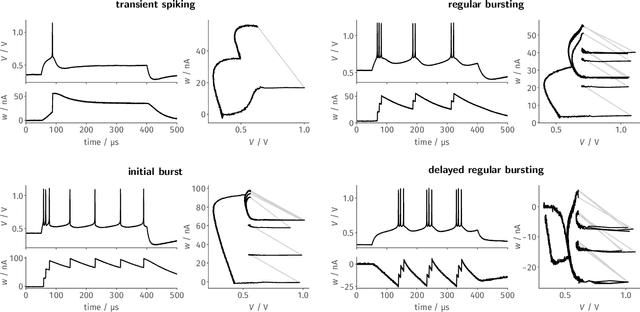
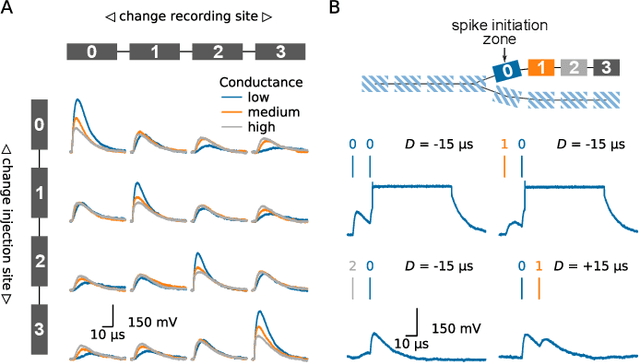
Since the beginning of information processing by electronic components, the nervous system has served as a metaphor for the organization of computational primitives. Brain-inspired computing today encompasses a class of approaches ranging from using novel nano-devices for computation to research into large-scale neuromorphic architectures, such as TrueNorth, SpiNNaker, BrainScaleS, Tianjic, and Loihi. While implementation details differ, spiking neural networks - sometimes referred to as the third generation of neural networks - are the common abstraction used to model computation with such systems. Here we describe the second generation of the BrainScaleS neuromorphic architecture, emphasizing applications enabled by this architecture. It combines a custom analog accelerator core supporting the accelerated physical emulation of bio-inspired spiking neural network primitives with a tightly coupled digital processor and a digital event-routing network.
EventProp: Backpropagation for Exact Gradients in Spiking Neural Networks
Sep 21, 2020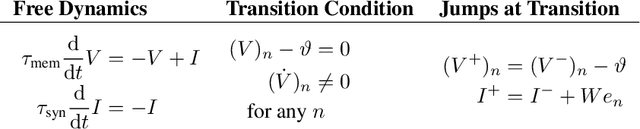
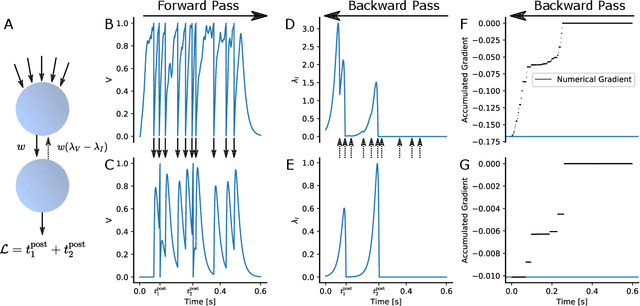
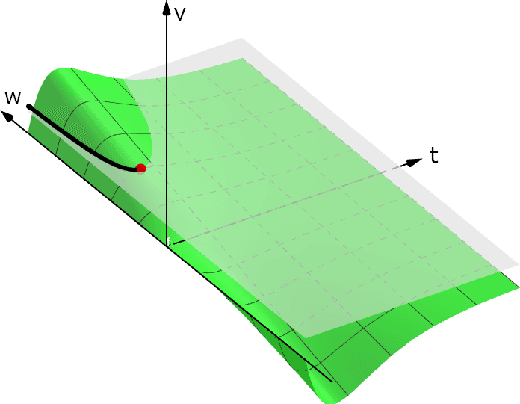
We derive the backpropagation algorithm for spiking neural networks composed of leaky integrate-and-fire neurons operating in continuous time. This algorithm, EventProp, computes the exact gradient of an arbitrary loss function of spike times and membrane potentials by backpropagating errors in time. For the first time, by leveraging methods from optimal control theory, we are able to backpropagate errors through spike discontinuities without approximations or smoothing operations. As errors are backpropagated in an event-based manner (at spike times), EventProp requires storing state variables only at these times, providing favorable memory requirements. EventProp can be applied to spiking networks with arbitrary connectivity, including recurrent, convolutional and deep feed-forward architectures. While we consider the leaky integrate-and-fire neuron model in this work, our methodology to derive the gradient can be applied to other spiking neuron models. We demonstrate learning using gradients computed via EventProp in a deep spiking network using an event-based simulator and a non-linearly separable dataset encoded using spike time latencies. Our work supports the rigorous study of gradient-based methods to train spiking neural networks while providing insights toward the development of learning algorithms in neuromorphic hardware.