 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShort-reach Optical Communications: A Real-world Task for Neuromorphic Hardware
Dec 04, 2024Spiking neural networks (SNNs) emulated on dedicated neuromorphic accelerators promise to offer energy-efficient signal processing. However, the neuromorphic advantage over traditional algorithms still remains to be demonstrated in real-world applications. Here, we describe an intensity-modulation, direct-detection (IM/DD) task that is relevant to high-speed optical communication systems used in data centers. Compared to other machine learning-inspired benchmarks, the task offers several advantages. First, the dataset is inherently time-dependent, i.e., there is a time dimension that can be natively mapped to the dynamic evolution of SNNs. Second, small-scale SNNs can achieve the target accuracy required by technical communication standards. Third, due to the small scale and the defined target accuracy, the task facilitates the optimization for real-world aspects, such as energy efficiency, resource requirements, and system complexity.
jaxsnn: Event-driven Gradient Estimation for Analog Neuromorphic Hardware
Jan 30, 2024Traditional neuromorphic hardware architectures rely on event-driven computation, where the asynchronous transmission of events, such as spikes, triggers local computations within synapses and neurons. While machine learning frameworks are commonly used for gradient-based training, their emphasis on dense data structures poses challenges for processing asynchronous data such as spike trains. This problem is particularly pronounced for typical tensor data structures. In this context, we present a novel library (jaxsnn) built on top of JAX, that departs from conventional machine learning frameworks by providing flexibility in the data structures used and the handling of time, while maintaining Autograd functionality and composability. Our library facilitates the simulation of spiking neural networks and gradient estimation, with a focus on compatibility with time-continuous neuromorphic backends, such as the BrainScaleS-2 system, during the forward pass. This approach opens avenues for more efficient and flexible training of spiking neural networks, bridging the gap between traditional neuromorphic architectures and contemporary machine learning frameworks.
Towards Large-scale Network Emulation on Analog Neuromorphic Hardware
Jan 30, 2024We present a novel software feature for the BrainScaleS-2 accelerated neuromorphic platform that facilitates the emulation of partitioned large-scale spiking neural networks. This approach is well suited for many deep spiking neural networks, where the constraint of the largest recurrent subnetwork fitting on the substrate or the limited fan-in of neurons is often not a limitation in practice. We demonstrate the training of two deep spiking neural network models, using the MNIST and EuroSAT datasets, that exceed the physical size constraints of a single-chip BrainScaleS-2 system. The ability to emulate and train networks larger than the substrate provides a pathway for accurate performance evaluation in planned or scaled systems, ultimately advancing the development and understanding of large-scale models and neuromorphic computing architectures.
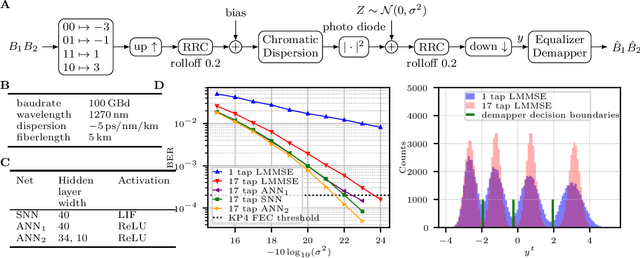
Spiking Neural Network Nonlinear Demapping on Neuromorphic Hardware for IM/DD Optical Communication
Feb 28, 2023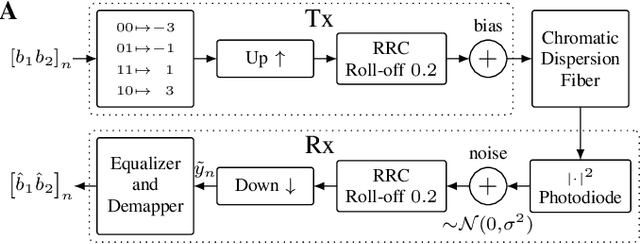
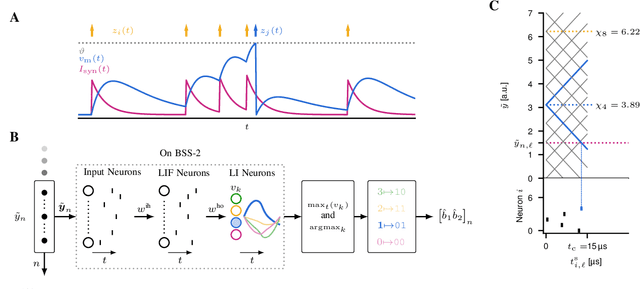
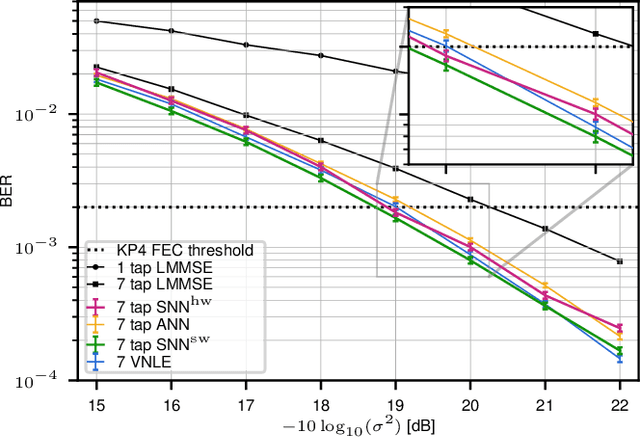
Neuromorphic computing implementing spiking neural networks (SNN) is a promising technology for reducing the footprint of optical transceivers, as required by the fast-paced growth of data center traffic. In this work, an SNN nonlinear demapper is designed and evaluated on a simulated intensity-modulation direct-detection link with chromatic dispersion. The SNN demapper is implemented in software and on the analog neuromorphic hardware system BrainScaleS-2 (BSS-2). For comparison, linear equalization (LE), Volterra nonlinear equalization (VNLE), and nonlinear demapping by an artificial neural network (ANN) implemented in software are considered. At a pre-forward error correction bit error rate of 2e-3, the software SNN outperforms LE by 1.5 dB, VNLE by 0.3 dB and the ANN by 0.5 dB. The hardware penalty of the SNN on BSS-2 is only 0.2 dB, i.e., also on hardware, the SNN performs better than all software implementations of the reference approaches. Hence, this work demonstrates that SNN demappers implemented on electrical analog hardware can realize powerful and accurate signal processing fulfilling the strict requirements of optical communications.
Event-based Backpropagation for Analog Neuromorphic Hardware
Feb 13, 2023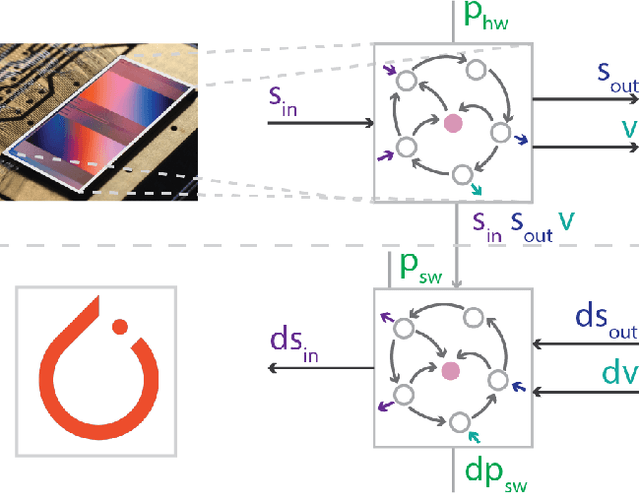

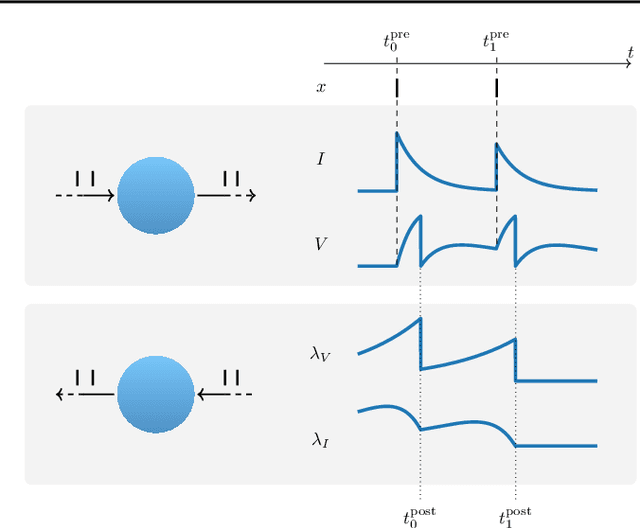

Neuromorphic computing aims to incorporate lessons from studying biological nervous systems in the design of computer architectures. While existing approaches have successfully implemented aspects of those computational principles, such as sparse spike-based computation, event-based scalable learning has remained an elusive goal in large-scale systems. However, only then the potential energy-efficiency advantages of neuromorphic systems relative to other hardware architectures can be realized during learning. We present our progress implementing the EventProp algorithm using the example of the BrainScaleS-2 analog neuromorphic hardware. Previous gradient-based approaches to learning used "surrogate gradients" and dense sampling of observables or were limited by assumptions on the underlying dynamics and loss functions. In contrast, our approach only needs spike time observations from the system while being able to incorporate other system observables, such as membrane voltage measurements, in a principled way. This leads to a one-order-of-magnitude improvement in the information efficiency of the gradient estimate, which would directly translate to corresponding energy efficiency improvements in an optimized hardware implementation. We present the theoretical framework for estimating gradients and results verifying the correctness of the estimation, as well as results on a low-dimensional classification task using the BrainScaleS-2 system. Building on this work has the potential to enable scalable gradient estimation in large-scale neuromorphic hardware as a continuous measurement of the system state would be prohibitive and energy-inefficient in such instances. It also suggests the feasibility of a full on-device implementation of the algorithm that would enable scalable, energy-efficient, event-based learning in large-scale analog neuromorphic hardware.
hxtorch.snn: Machine-learning-inspired Spiking Neural Network Modeling on BrainScaleS-2
Dec 23, 2022Neuromorphic systems require user-friendly software to support the design and optimization of experiments. In this work, we address this need by presenting our development of a machine learning-based modeling framework for the BrainScaleS-2 neuromorphic system. This work represents an improvement over previous efforts, which either focused on the matrix-multiplication mode of BrainScaleS-2 or lacked full automation. Our framework, called hxtorch.snn, enables the hardware-in-the-loop training of spiking neural networks within PyTorch, including support for auto differentiation in a fully-automated hardware experiment workflow. In addition, hxtorch.snn facilitates seamless transitions between emulating on hardware and simulating in software. We demonstrate the capabilities of hxtorch.snn on a classification task using the Yin-Yang dataset employing a gradient-based approach with surrogate gradients and densely sampled membrane observations from the BrainScaleS-2 hardware system.
Spiking Neural Network Equalization on Neuromorphic Hardware for IM/DD Optical Communication
Jun 01, 2022
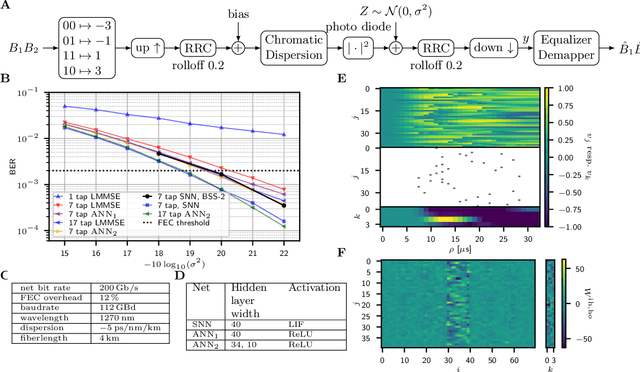
A spiking neural network (SNN) non-linear equalizer model is implemented on the mixed-signal neuromorphic hardware system BrainScaleS-2 and evaluated for an IM/DD link. The BER 2e-3 is achieved with a hardware penalty less than 1 dB, outperforming numeric linear equalization.
Spiking Neural Network Equalization for IM/DD Optical Communication
May 09, 2022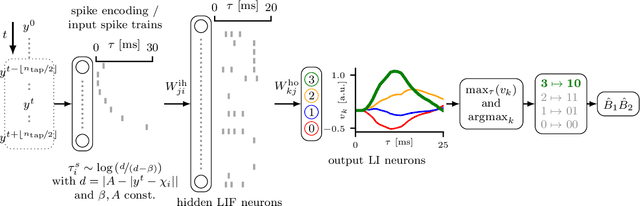
A spiking neural network (SNN) equalizer model suitable for electronic neuromorphic hardware is designed for an IM/DD link. The SNN achieves the same bit-error-rate as an artificial neural network, outperforming linear equalization.
A Scalable Approach to Modeling on Accelerated Neuromorphic Hardware
Mar 21, 2022
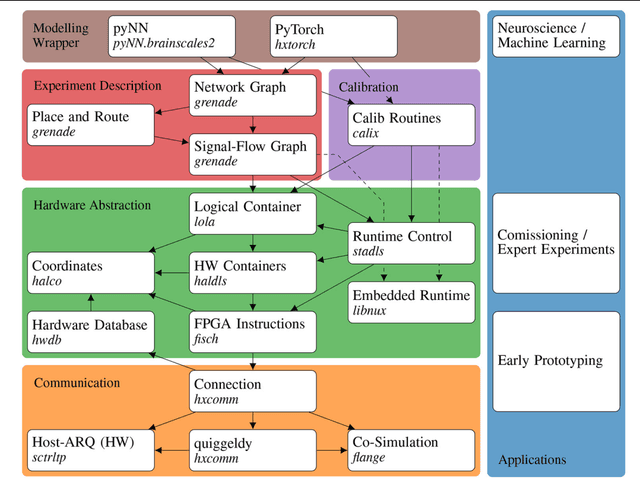
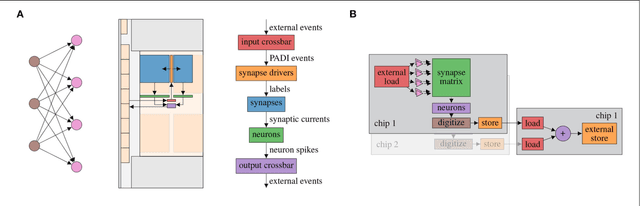
Neuromorphic systems open up opportunities to enlarge the explorative space for computational research. However, it is often challenging to unite efficiency and usability. This work presents the software aspects of this endeavor for the BrainScaleS-2 system, a hybrid accelerated neuromorphic hardware architecture based on physical modeling. We introduce key aspects of the BrainScaleS-2 Operating System: experiment workflow, API layering, software design, and platform operation. We present use cases to discuss and derive requirements for the software and showcase the implementation. The focus lies on novel system and software features such as multi-compartmental neurons, fast re-configuration for hardware-in-the-loop training, applications for the embedded processors, the non-spiking operation mode, interactive platform access, and sustainable hardware/software co-development. Finally, we discuss further developments in terms of hardware scale-up, system usability and efficiency.