 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Real-World Energy Management Dataset from a Smart Company Building for Optimization and Machine Learning
Mar 14, 2025We present a large real-world dataset obtained from monitoring a smart company facility over the course of six years, from 2018 to 2023. The dataset includes energy consumption data from various facility areas and components, energy production data from a photovoltaic system and a combined heat and power plant, operational data from heating and cooling systems, and weather data from an on-site weather station. The measurement sensors installed throughout the facility are organized in a hierarchical metering structure with multiple sub-metering levels, which is reflected in the dataset. The dataset contains measurement data from 72 energy meters, 9 heat meters and a weather station. Both raw and processed data at different processing levels, including labeled issues, is available. In this paper, we describe the data acquisition and post-processing employed to create the dataset. The dataset enables the application of a wide range of methods in the domain of energy management, including optimization, modeling, and machine learning to optimize building operations and reduce costs and carbon emissions.
Demonstrating the Advantages of Analog Wafer-Scale Neuromorphic Hardware
Dec 03, 2024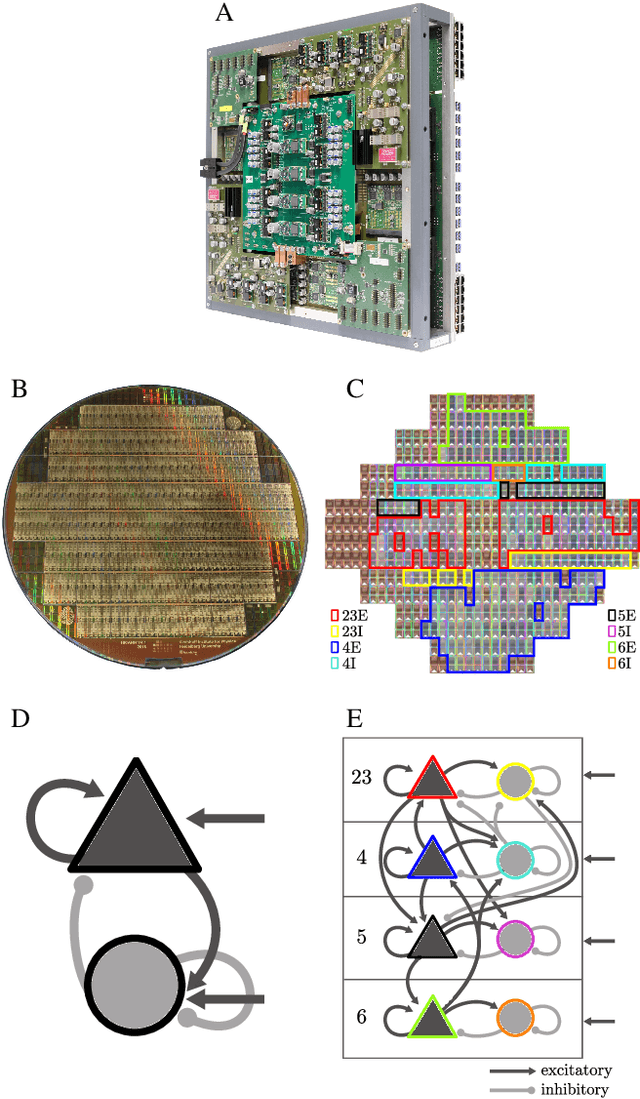
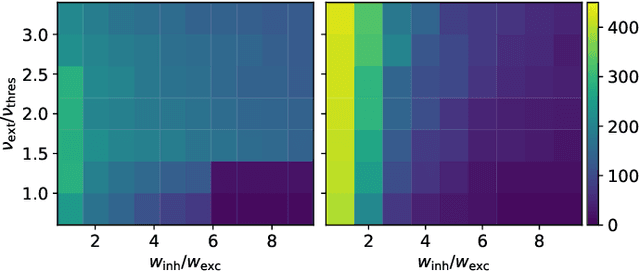
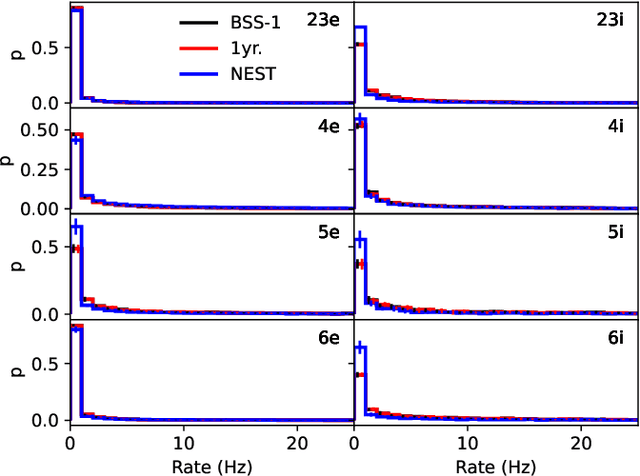
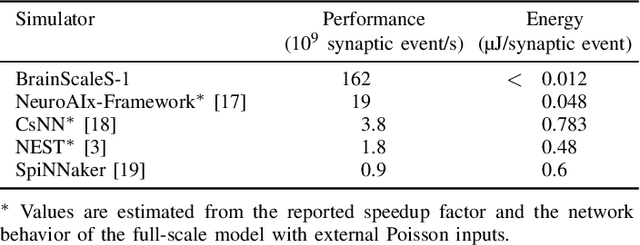
As numerical simulations grow in size and complexity, they become increasingly resource-intensive in terms of time and energy. While specialized hardware accelerators often provide order-of-magnitude gains and are state of the art in other scientific fields, their availability and applicability in computational neuroscience is still limited. In this field, neuromorphic accelerators, particularly mixed-signal architectures like the BrainScaleS systems, offer the most significant performance benefits. These systems maintain a constant, accelerated emulation speed independent of network model and size. This is especially beneficial when traditional simulators reach their limits, such as when modeling complex neuron dynamics, incorporating plasticity mechanisms, or running long or repetitive experiments. However, the analog nature of these systems introduces new challenges. In this paper we demonstrate the capabilities and advantages of the BrainScaleS-1 system and how it can be used in combination with conventional software simulations. We report the emulation time and energy consumption for two biologically inspired networks adapted to the neuromorphic hardware substrate: a balanced random network based on Brunel and the cortical microcircuit from Potjans and Diesmann.
Plastic Arbor: a modern simulation framework for synaptic plasticity $\unicode{x2013}$ from single synapses to networks of morphological neurons
Nov 25, 2024



Arbor is a software library designed for efficient simulation of large-scale networks of biological neurons with detailed morphological structures. It combines customizable neuronal and synaptic mechanisms with high-performance computing, supporting multi-core CPU and GPU systems. In humans and other animals, synaptic plasticity processes play a vital role in cognitive functions, including learning and memory. Recent studies have shown that intracellular molecular processes in dendrites significantly influence single-neuron dynamics. However, for understanding how the complex interplay between dendrites and synaptic processes influences network dynamics, computational modeling is required. To enable the modeling of large-scale networks of morphologically detailed neurons with diverse plasticity processes, we have extended the Arbor library to the Plastic Arbor framework, supporting simulations of a large variety of spike-driven plasticity paradigms. To showcase the features of the new framework, we present examples of computational models, beginning with single-synapse dynamics, progressing to multi-synapse rules, and finally scaling up to large recurrent networks. While cross-validating our implementations by comparison with other simulators, we show that Arbor allows simulating plastic networks of multi-compartment neurons at nearly no additional cost in runtime compared to point-neuron simulations. Using the new framework, we have already been able to investigate the impact of dendritic structures on network dynamics across a timescale of several hours, showing a relation between the length of dendritic trees and the ability of the network to efficiently store information. By our extension of Arbor, we aim to provide a valuable tool that will support future studies on the impact of synaptic plasticity, especially, in conjunction with neuronal morphology, in large networks.
A supervised hybrid quantum machine learning solution to the emergency escape routing problem
Jul 28, 2023



Managing the response to natural disasters effectively can considerably mitigate their devastating impact. This work explores the potential of using supervised hybrid quantum machine learning to optimize emergency evacuation plans for cars during natural disasters. The study focuses on earthquake emergencies and models the problem as a dynamic computational graph where an earthquake damages an area of a city. The residents seek to evacuate the city by reaching the exit points where traffic congestion occurs. The situation is modeled as a shortest-path problem on an uncertain and dynamically evolving map. We propose a novel hybrid supervised learning approach and test it on hypothetical situations on a concrete city graph. This approach uses a novel quantum feature-wise linear modulation (FiLM) neural network parallel to a classical FiLM network to imitate Dijkstra's node-wise shortest path algorithm on a deterministic dynamic graph. Adding the quantum neural network in parallel increases the overall model's expressivity by splitting the dataset's harmonic and non-harmonic features between the quantum and classical components. The hybrid supervised learning agent is trained on a dataset of Dijkstra's shortest paths and can successfully learn the navigation task. The hybrid quantum network improves over the purely classical supervised learning approach by 7% in accuracy. We show that the quantum part has a significant contribution of 45.(3)% to the prediction and that the network could be executed on an ion-based quantum computer. The results demonstrate the potential of supervised hybrid quantum machine learning in improving emergency evacuation planning during natural disasters.
Identification of Energy Management Configuration Concepts from a Set of Pareto-optimal Solutions
Jun 14, 2023



Optimizing building configurations for an efficient use of energy is increasingly receiving attention by current research and several methods have been developed to address this task. Selecting a suitable configuration based on multiple conflicting objectives, such as initial investment cost, recurring cost, robustness with respect to uncertainty of grid operation is, however, a difficult multi-criteria decision making problem. Concept identification can facilitate a decision maker by sorting configuration options into semantically meaningful groups (concepts), further introducing constraints to meet trade-off expectations for a selection of objectives. In this study, for a set of 20000 Pareto-optimal building energy management configurations, resulting from a many-objective evolutionary optimization, multiple concept identification iterations are conducted to provide a basis for making an informed investment decision. In a series of subsequent analysis steps, it is shown how the choice of description spaces, i.e., the partitioning of the features into sets for which consistent and non-overlapping concepts are required, impacts the type of information that can be extracted and that different setups of description spaces illuminate several different aspects of the configuration data - an important aspect that has not been addressed in previous work.
Simulation-based Inference for Model Parameterization on Analog Neuromorphic Hardware
Mar 28, 2023The BrainScaleS-2 (BSS-2) system implements physical models of neurons as well as synapses and aims for an energy-efficient and fast emulation of biological neurons. When replicating neuroscientific experiment results, a major challenge is finding suitable model parameters. This study investigates the suitability of the sequential neural posterior estimation (SNPE) algorithm for parameterizing a multi-compartmental neuron model emulated on the BSS-2 analog neuromorphic hardware system. In contrast to other optimization methods such as genetic algorithms or stochastic searches, the SNPE algorithms belongs to the class of approximate Bayesian computing (ABC) methods and estimates the posterior distribution of the model parameters; access to the posterior allows classifying the confidence in parameter estimations and unveiling correlation between model parameters. In previous applications, the SNPE algorithm showed a higher computational efficiency than traditional ABC methods. For our multi-compartmental model, we show that the approximated posterior is in agreement with experimental observations and that the identified correlation between parameters is in agreement with theoretical expectations. Furthermore, we show that the algorithm can deal with high-dimensional observations and parameter spaces. These results suggest that the SNPE algorithm is a promising approach for automating the parameterization of complex models, especially when dealing with characteristic properties of analog neuromorphic substrates, such as trial-to-trial variations or limited parameter ranges.
From Clean Room to Machine Room: Commissioning of the First-Generation BrainScaleS Wafer-Scale Neuromorphic System
Mar 22, 2023The first-generation of BrainScaleS, also referred to as BrainScaleS-1, is a neuromorphic system for emulating large-scale networks of spiking neurons. Following a "physical modeling" principle, its VLSI circuits are designed to emulate the dynamics of biological examples: analog circuits implement neurons and synapses with time constants that arise from their electronic components' intrinsic properties. It operates in continuous time, with dynamics typically matching an acceleration factor of 10000 compared to the biological regime. A fault-tolerant design allows it to achieve wafer-scale integration despite unavoidable analog variability and component failures. In this paper, we present the commissioning process of a BrainScaleS-1 wafer module, providing a short description of the system's physical components, illustrating the steps taken during its assembly and the measures taken to operate it. Furthermore, we reflect on the system's development process and the lessons learned to conclude with a demonstration of its functionality by emulating a wafer-scale synchronous firing chain, the largest spiking network emulation ran with analog components and individual synapses to date.
Understanding Concept Identification as Consistent Data Clustering Across Multiple Feature Spaces
Jan 13, 2023Identifying meaningful concepts in large data sets can provide valuable insights into engineering design problems. Concept identification aims at identifying non-overlapping groups of design instances that are similar in a joint space of all features, but which are also similar when considering only subsets of features. These subsets usually comprise features that characterize a design with respect to one specific context, for example, constructive design parameters, performance values, or operation modes. It is desirable to evaluate the quality of design concepts by considering several of these feature subsets in isolation. In particular, meaningful concepts should not only identify dense, well separated groups of data instances, but also provide non-overlapping groups of data that persist when considering pre-defined feature subsets separately. In this work, we propose to view concept identification as a special form of clustering algorithm with a broad range of potential applications beyond engineering design. To illustrate the differences between concept identification and classical clustering algorithms, we apply a recently proposed concept identification algorithm to two synthetic data sets and show the differences in identified solutions. In addition, we introduce the mutual information measure as a metric to evaluate whether solutions return consistent clusters across relevant subsets. To support the novel understanding of concept identification, we consider a simulated data set from a decision-making problem in the energy management domain and show that the identified clusters are more interpretable with respect to relevant feature subsets than clusters found by common clustering algorithms and are thus more suitable to support a decision maker.
Alleviating Search Bias in Bayesian Evolutionary Optimization with Many Heterogeneous Objectives
Aug 25, 2022



Multi-objective optimization problems whose objectives have different evaluation costs are commonly seen in the real world. Such problems are now known as multi-objective optimization problems with heterogeneous objectives (HE-MOPs). So far, however, only a few studies have been reported to address HE-MOPs, and most of them focus on bi-objective problems with one fast objective and one slow objective. In this work, we aim to deal with HE-MOPs having more than two black-box and heterogeneous objectives. To this end, we develop a multi-objective Bayesian evolutionary optimization approach to HE-MOPs by exploiting the different data sets on the cheap and expensive objectives in HE-MOPs to alleviate the search bias caused by the heterogeneous evaluation costs for evaluating different objectives. To make the best use of two different training data sets, one with solutions evaluated on all objectives and the other with those only evaluated on the fast objectives, two separate Gaussian process models are constructed. In addition, a new acquisition function that mitigates search bias towards the fast objectives is suggested, thereby achieving a balance between convergence and diversity. We demonstrate the effectiveness of the proposed algorithm by testing it on widely used multi-/many-objective benchmark problems whose objectives are assumed to be heterogeneously expensive.
Concept Identification for Complex Engineering Datasets
Jun 09, 2022
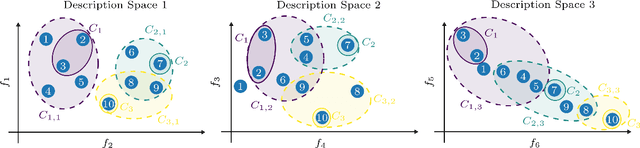
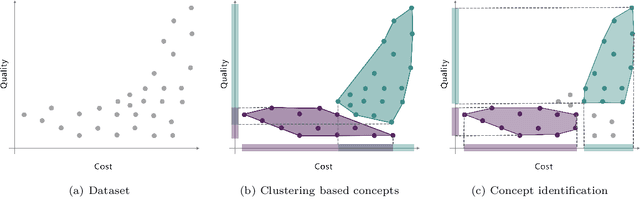
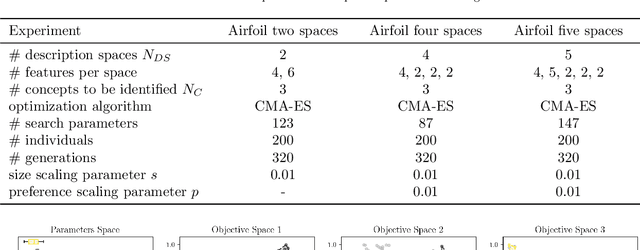
Finding meaningful concepts in engineering application datasets which allow for a sensible grouping of designs is very helpful in many contexts. It allows for determining different groups of designs with similar properties and provides useful knowledge in the engineering decision making process. Also, it opens the route for further refinements of specific design candidates which exhibit certain characteristic features. In this work, an approach to define meaningful and consistent concepts in an existing engineering dataset is presented. The designs in the dataset are characterized by a multitude of features such as design parameters, geometrical properties or performance values of the design for various boundary conditions. In the proposed approach the complete feature set is partitioned into several subsets called description spaces. The definition of the concepts respects this partitioning which leads to several desired properties of the identified concepts, which cannot be achieved with state-of-the-art clustering or concept identification approaches. A novel concept quality measure is proposed, which provides an objective value for a given definition of concepts in a dataset. The usefulness of the measure is demonstrated by considering a realistic engineering dataset consisting of about 2500 airfoil profiles where the performance values (lift and drag) for three different operating conditions were obtained by a computational fluid dynamics simulation. A numerical optimization procedure is employed which maximizes the concept quality measure, and finds meaningful concepts for different setups of the description spaces while also incorporating user preference. It is demonstrated how these concepts can be used to select archetypal representatives of the dataset which exhibit characteristic features of each concept.