 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Real-World Energy Management Dataset from a Smart Company Building for Optimization and Machine Learning
Mar 14, 2025We present a large real-world dataset obtained from monitoring a smart company facility over the course of six years, from 2018 to 2023. The dataset includes energy consumption data from various facility areas and components, energy production data from a photovoltaic system and a combined heat and power plant, operational data from heating and cooling systems, and weather data from an on-site weather station. The measurement sensors installed throughout the facility are organized in a hierarchical metering structure with multiple sub-metering levels, which is reflected in the dataset. The dataset contains measurement data from 72 energy meters, 9 heat meters and a weather station. Both raw and processed data at different processing levels, including labeled issues, is available. In this paper, we describe the data acquisition and post-processing employed to create the dataset. The dataset enables the application of a wide range of methods in the domain of energy management, including optimization, modeling, and machine learning to optimize building operations and reduce costs and carbon emissions.
Confidence Interval Estimation of Predictive Performance in the Context of AutoML
Jun 12, 2024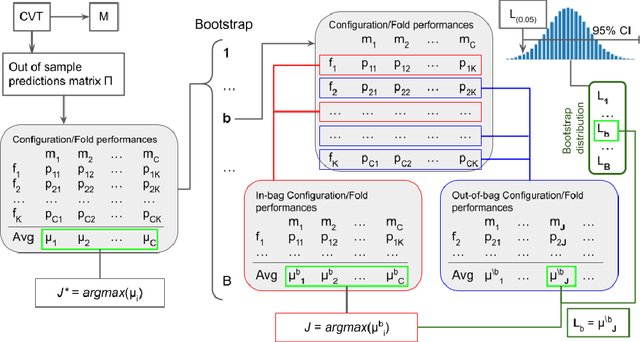
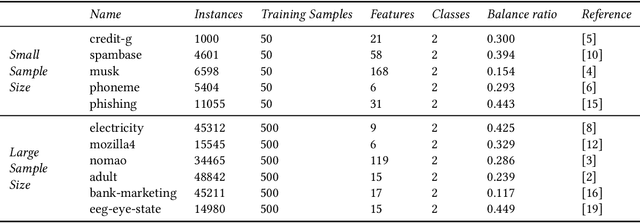
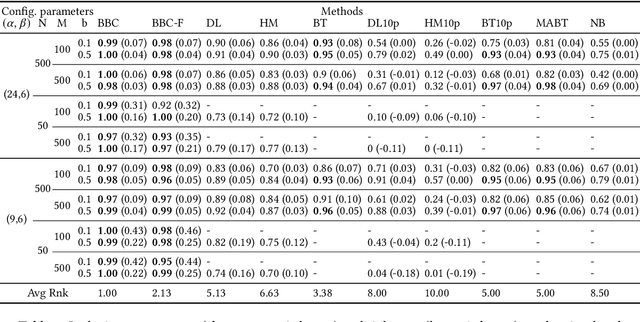
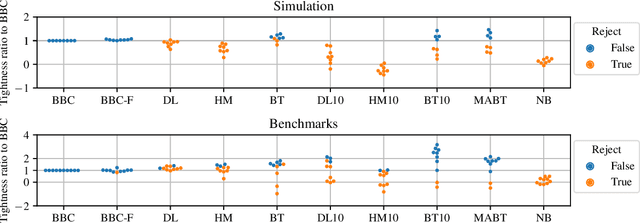
Any supervised machine learning analysis is required to provide an estimate of the out-of-sample predictive performance. However, it is imperative to also provide a quantification of the uncertainty of this performance in the form of a confidence or credible interval (CI) and not just a point estimate. In an AutoML setting, estimating the CI is challenging due to the ``winner's curse", i.e., the bias of estimation due to cross-validating several machine learning pipelines and selecting the winning one. In this work, we perform a comparative evaluation of 9 state-of-the-art methods and variants in CI estimation in an AutoML setting on a corpus of real and simulated datasets. The methods are compared in terms of inclusion percentage (does a 95\% CI include the true performance at least 95\% of the time), CI tightness (tighter CIs are preferable as being more informative), and execution time. The evaluation is the first one that covers most, if not all, such methods and extends previous work to imbalanced and small-sample tasks. In addition, we present a variant, called BBC-F, of an existing method (the Bootstrap Bias Correction, or BBC) that maintains the statistical properties of the BBC but is more computationally efficient. The results support that BBC-F and BBC dominate the other methods in all metrics measured.
Stream-based Active Learning with Verification Latency in Non-stationary Environments
Apr 14, 2022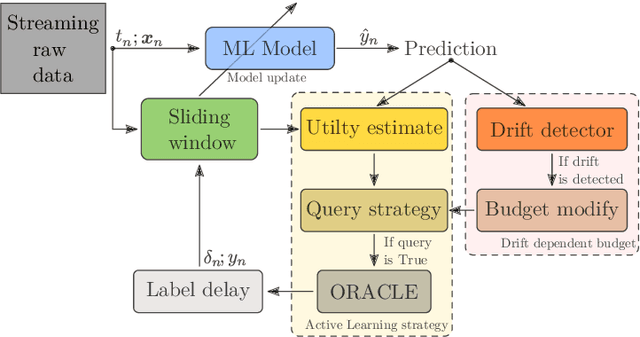
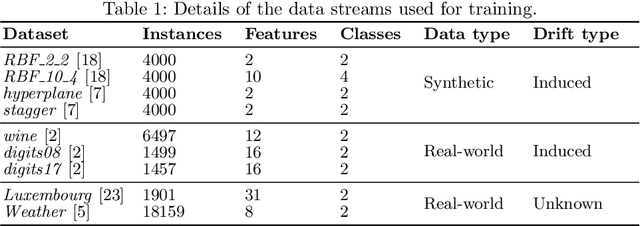
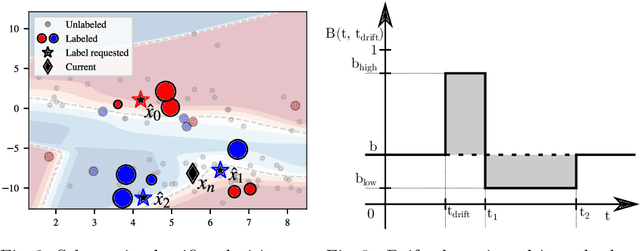
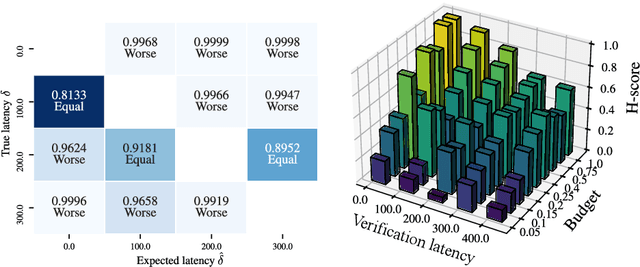
Data stream classification is an important problem in the field of machine learning. Due to the non-stationary nature of the data where the underlying distribution changes over time (concept drift), the model needs to continuously adapt to new data statistics. Stream-based Active Learning (AL) approaches address this problem by interactively querying a human expert to provide new data labels for the most recent samples, within a limited budget. Existing AL strategies assume that labels are immediately available, while in a real-world scenario the expert requires time to provide a queried label (verification latency), and by the time the requested labels arrive they may not be relevant anymore. In this article, we investigate the influence of finite, time-variable, and unknown verification delay, in the presence of concept drift on AL approaches. We propose PRopagate (PR), a latency independent utility estimator which also predicts the requested, but not yet known, labels. Furthermore, we propose a drift-dependent dynamic budget strategy, which uses a variable distribution of the labelling budget over time, after a detected drift. Thorough experimental evaluation, with both synthetic and real-world non-stationary datasets, and different settings of verification latency and budget are conducted and analyzed. We empirically show that the proposed method consistently outperforms the state-of-the-art. Additionally, we demonstrate that with variable budget allocation in time, it is possible to boost the performance of AL strategies, without increasing the overall labeling budget.
Task-Sensitive Concept Drift Detector with Constraint Embedding
Aug 24, 2021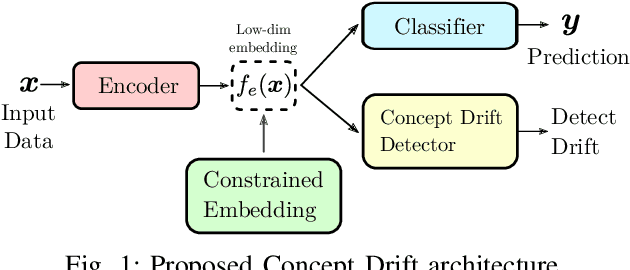
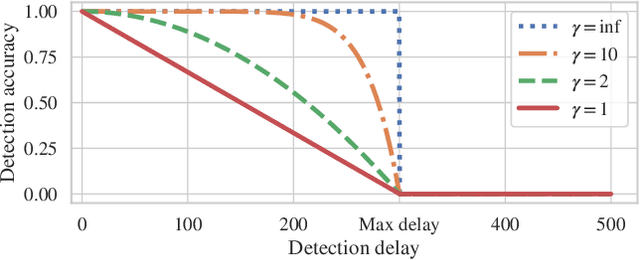
Detecting drifts in data is essential for machine learning applications, as changes in the statistics of processed data typically has a profound influence on the performance of trained models. Most of the available drift detection methods are either supervised and require access to the true labels during inference time, or they are completely unsupervised and aim for changes in distributions without taking label information into account. We propose a novel task-sensitive semi-supervised drift detection scheme, which utilizes label information while training the initial model, but takes into account that supervised label information is no longer available when using the model during inference. It utilizes a constrained low-dimensional embedding representation of the input data. This way, it is best suited for the classification task. It is able to detect real drift, where the drift affects the classification performance, while it properly ignores virtual drift, where the classification performance is not affected by the drift. In the proposed framework, the actual method to detect a change in the statistics of incoming data samples can be chosen freely. Experimental evaluation on nine benchmarks datasets, with different types of drift, demonstrates that the proposed framework can reliably detect drifts, and outperforms state-of-the-art unsupervised drift detection approaches.
Estimating the electrical power output of industrial devices with end-to-end time-series classification in the presence of label noise
May 01, 2021
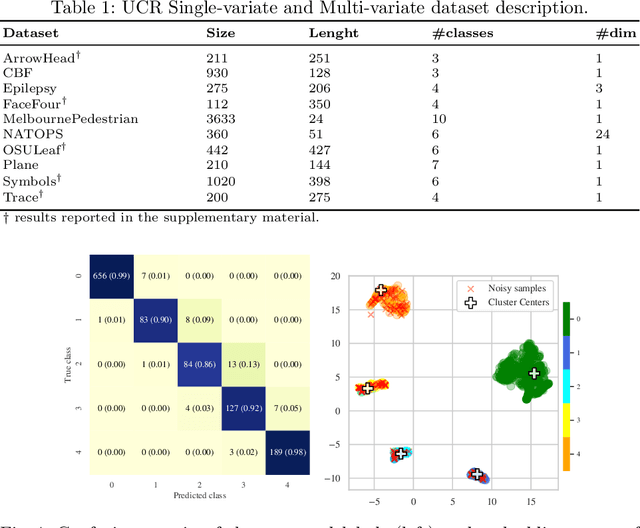
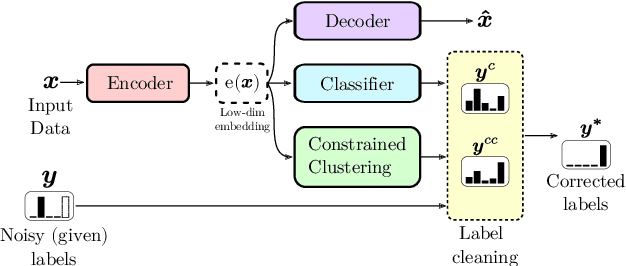
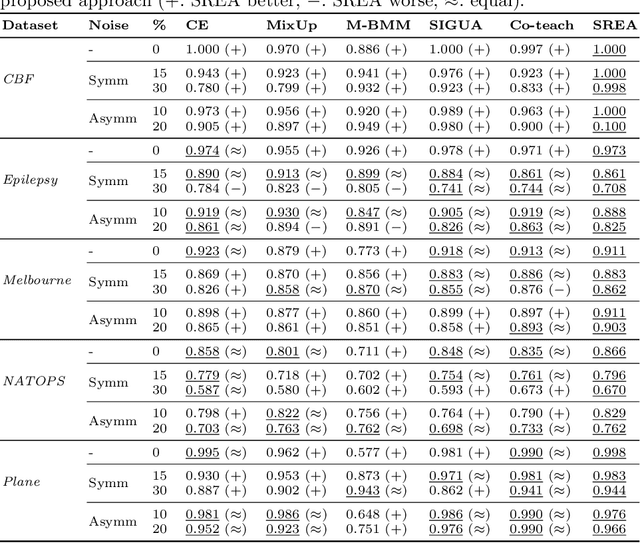
In complex industrial settings, it is common practice to monitor the operation of machines in order to detect undesired states, adjust maintenance schedules, optimize system performance or collect usage statistics of individual machines. In this work, we focus on estimating the power output of a Combined Heat and Power (CHP) machine of a medium-sized company facility by analyzing the total facility power consumption. We formulate the problem as a time-series classification problem where the class label represents the CHP power output. As the facility is fully instrumented and sensor measurements from the CHP are available, we generate the training labels in an automated fashion from the CHP sensor readings. However, sensor failures result in mislabeled training data samples which are hard to detect and remove from the dataset. Therefore, we propose a novel multi-task deep learning approach that jointly trains a classifier and an autoencoder with a shared embedding representation. The proposed approach targets to gradually correct the mislabelled data samples during training in a self-supervised fashion, without any prior assumption on the amount of label noise. We benchmark our approach on several time-series classification datasets and find it to be comparable and sometimes better than state-of-the-art methods. On the real-world use-case of predicting the CHP power output, we thoroughly evaluate the architectural design choices and show that the final architecture considerably increases the robustness of the learning process and consistently beats other recent state-of-the-art algorithms in the presence of unstructured as well as structured label noise.
Real-World Anomaly Detection by using Digital Twin Systems and Weakly-Supervised Learning
Nov 12, 2020

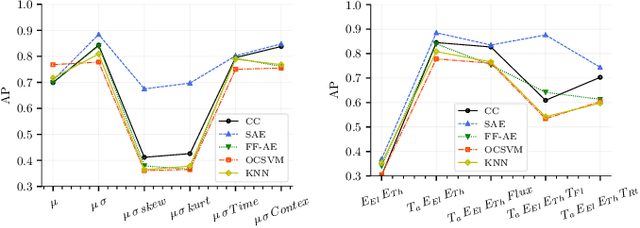

The continuously growing amount of monitored data in the Industry 4.0 context requires strong and reliable anomaly detection techniques. The advancement of Digital Twin technologies allows for realistic simulations of complex machinery, therefore, it is ideally suited to generate synthetic datasets for the use in anomaly detection approaches when compared to actual measurement data. In this paper, we present novel weakly-supervised approaches to anomaly detection for industrial settings. The approaches make use of a Digital Twin to generate a training dataset which simulates the normal operation of the machinery, along with a small set of labeled anomalous measurement from the real machinery. In particular, we introduce a clustering-based approach, called Cluster Centers (CC), and a neural architecture based on the Siamese Autoencoders (SAE), which are tailored for weakly-supervised settings with very few labeled data samples. The performance of the proposed methods is compared against various state-of-the-art anomaly detection algorithms on an application to a real-world dataset from a facility monitoring system, by using a multitude of performance measures. Also, the influence of hyper-parameters related to feature extraction and network architecture is investigated. We find that the proposed SAE based solutions outperform state-of-the-art anomaly detection approaches very robustly for many different hyper-parameter settings on all performance measures.