 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTask-Sensitive Concept Drift Detector with Constraint Embedding
Paper and Code
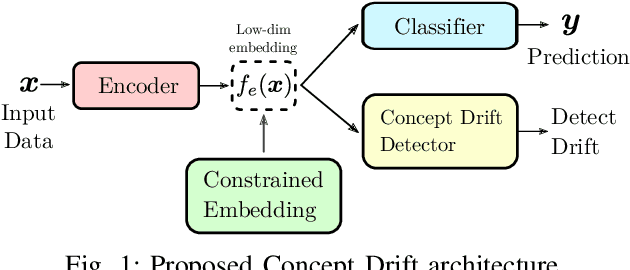
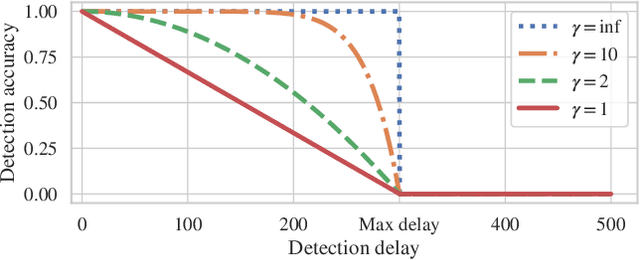
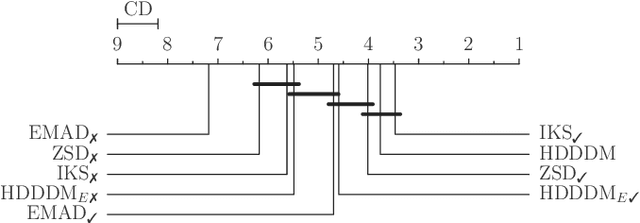
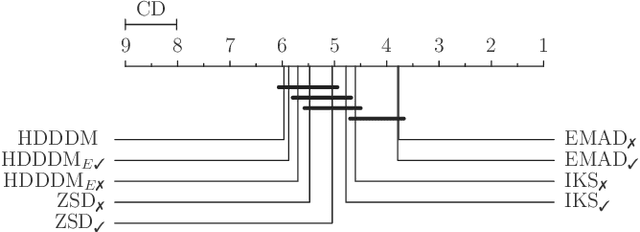
Detecting drifts in data is essential for machine learning applications, as changes in the statistics of processed data typically has a profound influence on the performance of trained models. Most of the available drift detection methods are either supervised and require access to the true labels during inference time, or they are completely unsupervised and aim for changes in distributions without taking label information into account. We propose a novel task-sensitive semi-supervised drift detection scheme, which utilizes label information while training the initial model, but takes into account that supervised label information is no longer available when using the model during inference. It utilizes a constrained low-dimensional embedding representation of the input data. This way, it is best suited for the classification task. It is able to detect real drift, where the drift affects the classification performance, while it properly ignores virtual drift, where the classification performance is not affected by the drift. In the proposed framework, the actual method to detect a change in the statistics of incoming data samples can be chosen freely. Experimental evaluation on nine benchmarks datasets, with different types of drift, demonstrates that the proposed framework can reliably detect drifts, and outperforms state-of-the-art unsupervised drift detection approaches.