 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConfidence Interval Estimation of Predictive Performance in the Context of AutoML
Jun 12, 2024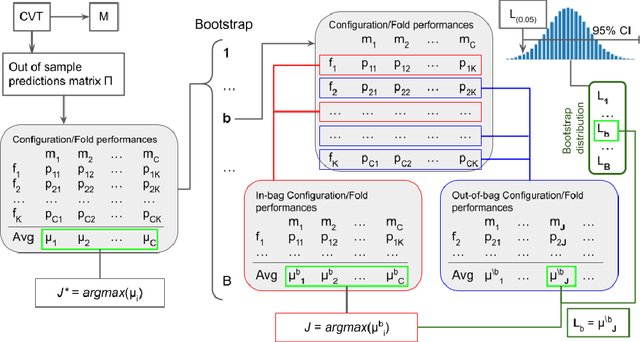
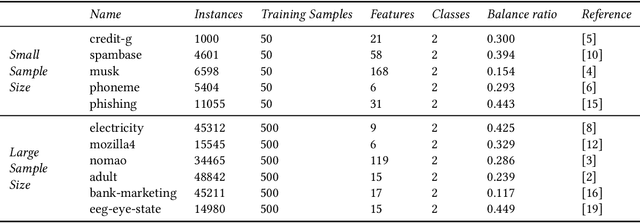
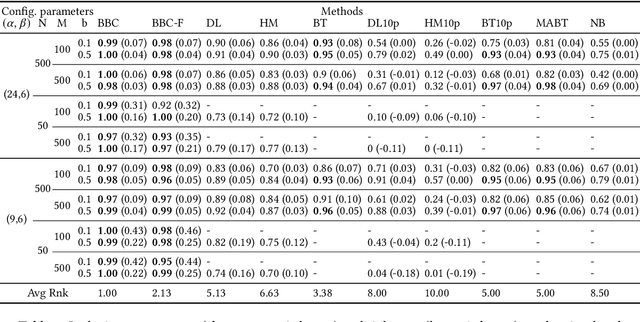
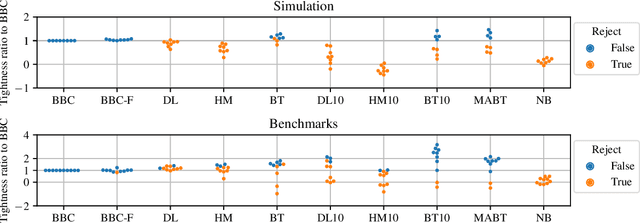
Any supervised machine learning analysis is required to provide an estimate of the out-of-sample predictive performance. However, it is imperative to also provide a quantification of the uncertainty of this performance in the form of a confidence or credible interval (CI) and not just a point estimate. In an AutoML setting, estimating the CI is challenging due to the ``winner's curse", i.e., the bias of estimation due to cross-validating several machine learning pipelines and selecting the winning one. In this work, we perform a comparative evaluation of 9 state-of-the-art methods and variants in CI estimation in an AutoML setting on a corpus of real and simulated datasets. The methods are compared in terms of inclusion percentage (does a 95\% CI include the true performance at least 95\% of the time), CI tightness (tighter CIs are preferable as being more informative), and execution time. The evaluation is the first one that covers most, if not all, such methods and extends previous work to imbalanced and small-sample tasks. In addition, we present a variant, called BBC-F, of an existing method (the Bootstrap Bias Correction, or BBC) that maintains the statistical properties of the BBC but is more computationally efficient. The results support that BBC-F and BBC dominate the other methods in all metrics measured.
A Meta-Level Learning Algorithm for Sequential Hyper-Parameter Space Reduction in AutoML
Dec 11, 2023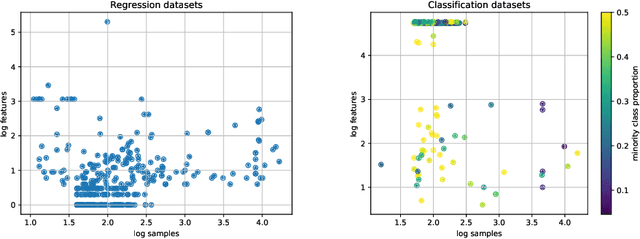
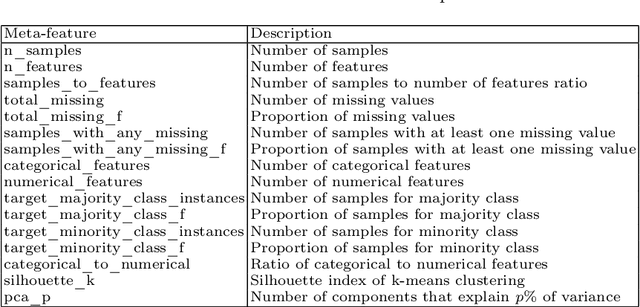
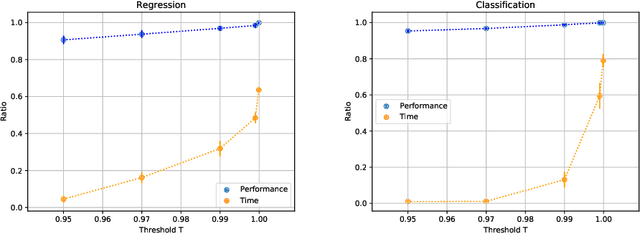
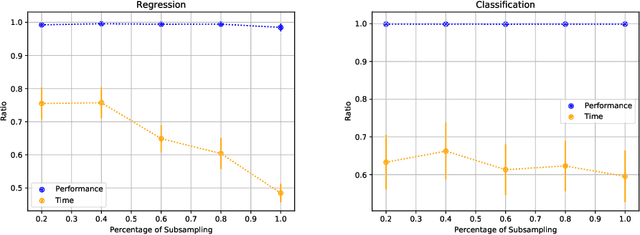
AutoML platforms have numerous options for the algorithms to try for each step of the analysis, i.e., different possible algorithms for imputation, transformations, feature selection, and modelling. Finding the optimal combination of algorithms and hyper-parameter values is computationally expensive, as the number of combinations to explore leads to an exponential explosion of the space. In this paper, we present the Sequential Hyper-parameter Space Reduction (SHSR) algorithm that reduces the space for an AutoML tool with negligible drop in its predictive performance. SHSR is a meta-level learning algorithm that analyzes past runs of an AutoML tool on several datasets and learns which hyper-parameter values to filter out from consideration on a new dataset to analyze. SHSR is evaluated on 284 classification and 375 regression problems, showing an approximate 30% reduction in execution time with a performance drop of less than 0.1%.