 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Scalable Approach to Modeling on Accelerated Neuromorphic Hardware
Mar 21, 2022
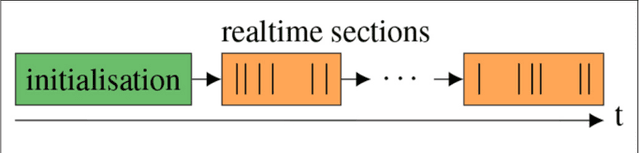
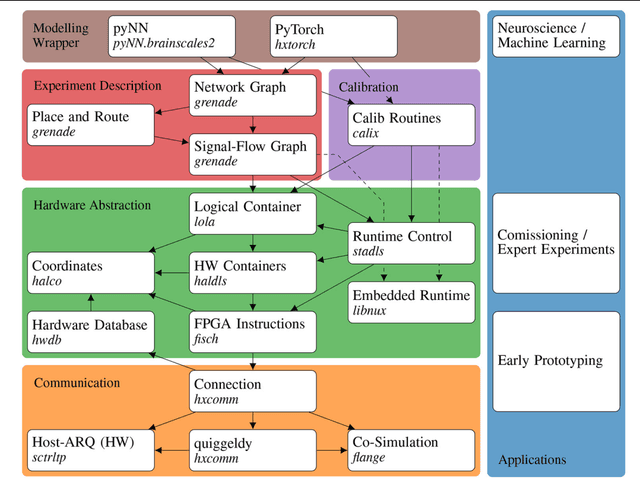
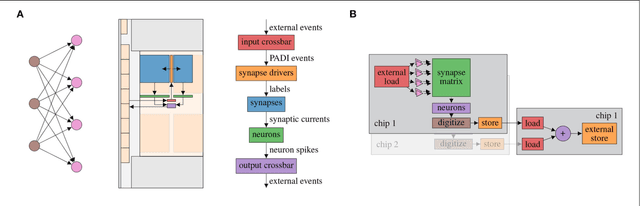
Neuromorphic systems open up opportunities to enlarge the explorative space for computational research. However, it is often challenging to unite efficiency and usability. This work presents the software aspects of this endeavor for the BrainScaleS-2 system, a hybrid accelerated neuromorphic hardware architecture based on physical modeling. We introduce key aspects of the BrainScaleS-2 Operating System: experiment workflow, API layering, software design, and platform operation. We present use cases to discuss and derive requirements for the software and showcase the implementation. The focus lies on novel system and software features such as multi-compartmental neurons, fast re-configuration for hardware-in-the-loop training, applications for the embedded processors, the non-spiking operation mode, interactive platform access, and sustainable hardware/software co-development. Finally, we discuss further developments in terms of hardware scale-up, system usability and efficiency.
The BrainScaleS-2 accelerated neuromorphic system with hybrid plasticity
Feb 03, 2022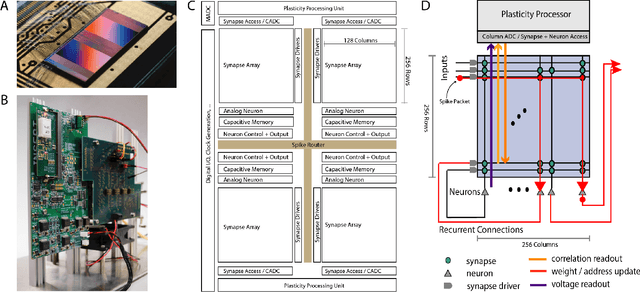
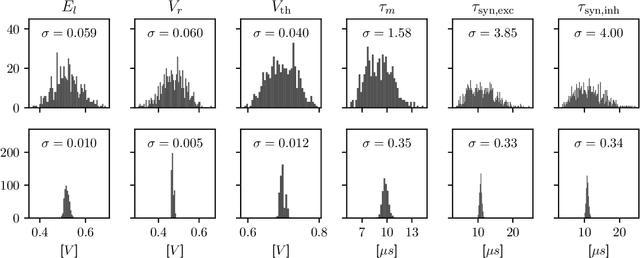
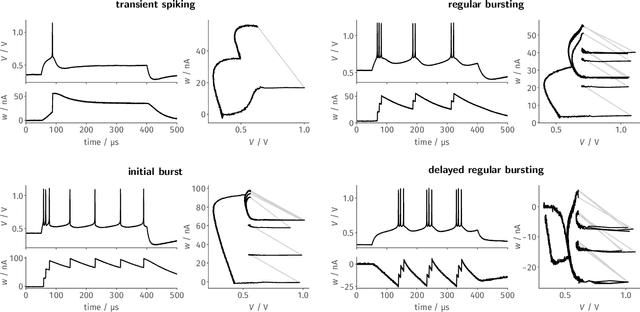
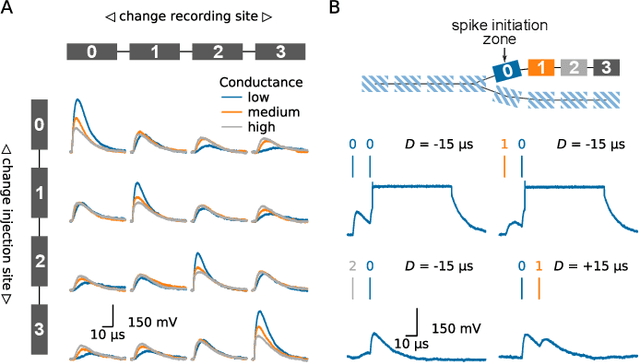
Since the beginning of information processing by electronic components, the nervous system has served as a metaphor for the organization of computational primitives. Brain-inspired computing today encompasses a class of approaches ranging from using novel nano-devices for computation to research into large-scale neuromorphic architectures, such as TrueNorth, SpiNNaker, BrainScaleS, Tianjic, and Loihi. While implementation details differ, spiking neural networks - sometimes referred to as the third generation of neural networks - are the common abstraction used to model computation with such systems. Here we describe the second generation of the BrainScaleS neuromorphic architecture, emphasizing applications enabled by this architecture. It combines a custom analog accelerator core supporting the accelerated physical emulation of bio-inspired spiking neural network primitives with a tightly coupled digital processor and a digital event-routing network.
hxtorch: PyTorch for BrainScaleS-2 -- Perceptrons on Analog Neuromorphic Hardware
Jul 01, 2020
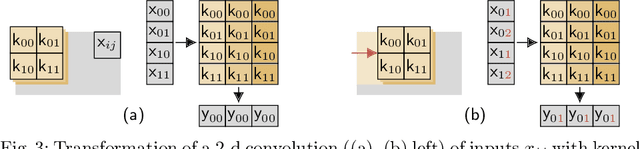
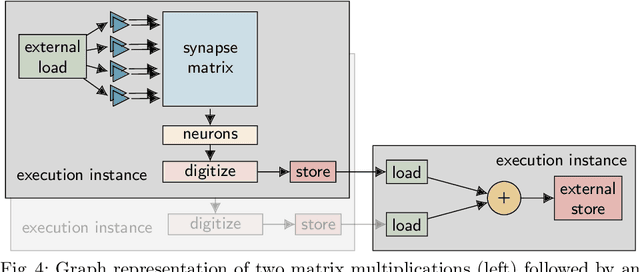

We present software facilitating the usage of the BrainScaleS-2 analog neuromorphic hardware system as an inference accelerator for artificial neural networks. The accelerator hardware is transparently integrated into the PyTorch machine learning framework using its extension interface. In particular, we provide accelerator support for vector-matrix multiplications and convolutions; corresponding software-based autograd functionality is provided for hardware-in-the-loop training. Automatic partitioning of neural networks onto one or multiple accelerator chips is supported. We analyze implementation runtime overhead during training as well as inference, provide measurements for existing setups and evaluate the results in terms of the accelerator hardware design limitations. As an application of the introduced framework, we present a model that classifies activities of daily living with smartphone sensor data.
Training spiking multi-layer networks with surrogate gradients on an analog neuromorphic substrate
Jun 12, 2020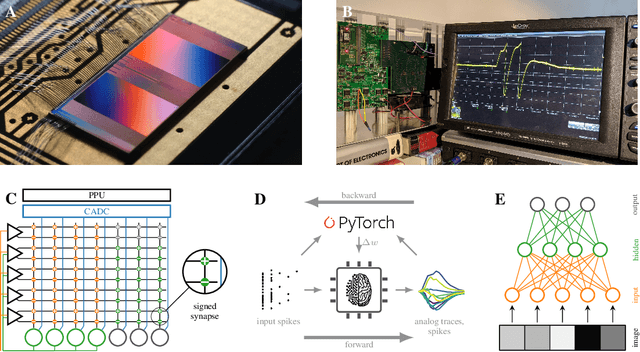

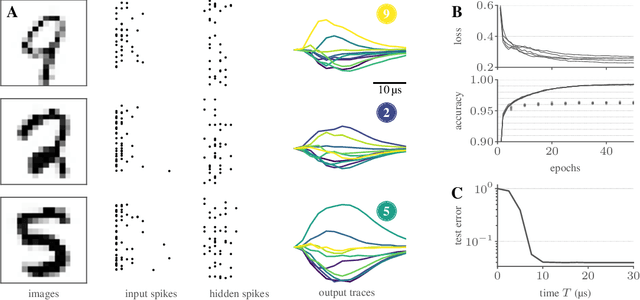
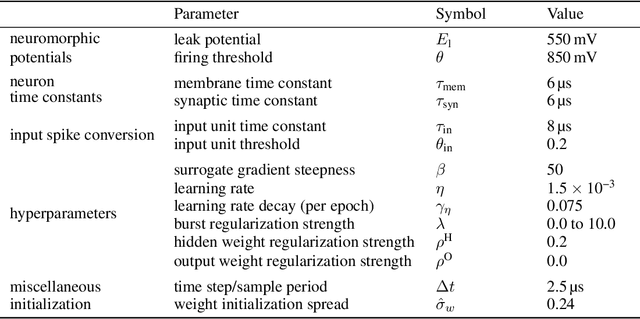
Spiking neural networks are nature's solution for parallel information processing with high temporal precision at a low metabolic energy cost. To that end, biological neurons integrate inputs as an analog sum and communicate their outputs digitally as spikes, i.e., sparse binary events in time. These architectural principles can be mirrored effectively in analog neuromorphic hardware. Nevertheless, training spiking neural networks with sparse activity on hardware devices remains a major challenge. Primarily this is due to the lack of suitable training methods that take into account device-specific imperfections and operate at the level of individual spikes instead of firing rates. To tackle this issue, we developed a hardware-in-the-loop strategy to train multi-layer spiking networks using surrogate gradients on the analog BrainScales-2 chip. Specifically, we used the hardware to compute the forward pass of the network, while the backward pass was computed in software. We evaluated our approach on downscaled 16x16 versions of the MNIST and the fashion MNIST datasets in which spike latencies encoded pixel intensities. The analog neuromorphic substrate closely matched the performance of equivalently sized networks implemented in software. It is capable of processing 70 k patterns per second with a power consumption of less than 300 mW. Added activity regularization resulted in sparse network activity with about 20 spikes per input, at little to no reduction in classification performance. Thus, overall, our work demonstrates low-energy spiking network processing on an analog neuromorphic substrate and sets several new benchmarks for hardware systems in terms of classification accuracy, processing speed, and efficiency. Importantly, our work emphasizes the value of hardware-in-the-loop training and paves the way toward energy-efficient information processing on non-von-Neumann architectures.