 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Scalable Approach to Modeling on Accelerated Neuromorphic Hardware
Mar 21, 2022
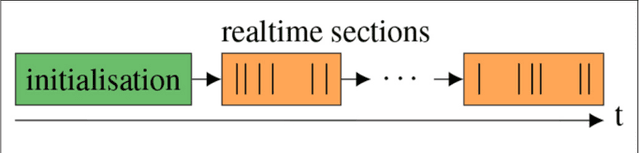
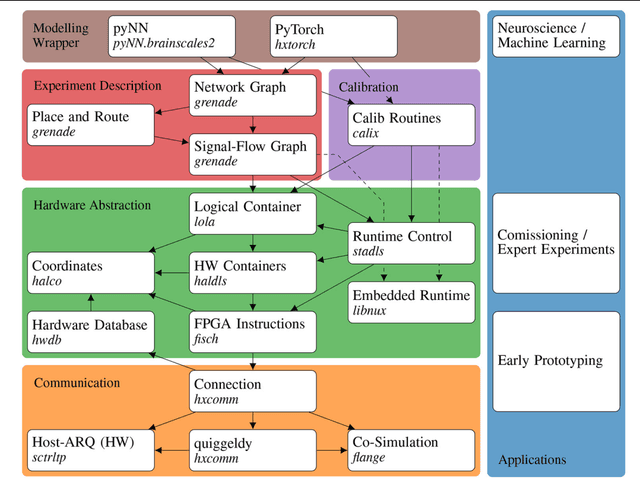
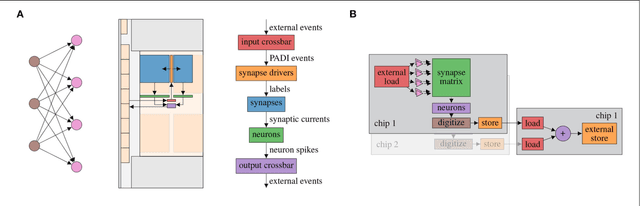
Neuromorphic systems open up opportunities to enlarge the explorative space for computational research. However, it is often challenging to unite efficiency and usability. This work presents the software aspects of this endeavor for the BrainScaleS-2 system, a hybrid accelerated neuromorphic hardware architecture based on physical modeling. We introduce key aspects of the BrainScaleS-2 Operating System: experiment workflow, API layering, software design, and platform operation. We present use cases to discuss and derive requirements for the software and showcase the implementation. The focus lies on novel system and software features such as multi-compartmental neurons, fast re-configuration for hardware-in-the-loop training, applications for the embedded processors, the non-spiking operation mode, interactive platform access, and sustainable hardware/software co-development. Finally, we discuss further developments in terms of hardware scale-up, system usability and efficiency.
Demonstrating BrainScaleS-2 Inter-Chip Pulse-Communication using EXTOLL
Mar 03, 2022
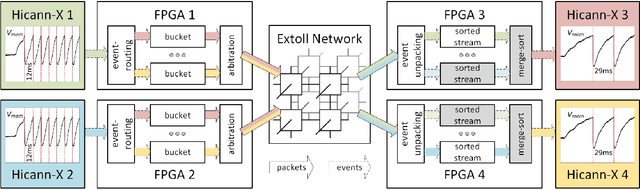
The BrainScaleS-2 (BSS-2) Neuromorphic Computing System currently consists of multiple single-chip setups, which are connected to a compute cluster via Gigabit-Ethernet network technology. This is convenient for small experiments, where the neural networks fit into a single chip. When modeling networks of larger size, neurons have to be connected across chip boundaries. We implement these connections for BSS-2 using the EXTOLL networking technology. This provides high bandwidths and low latencies, as well as high message rates. Here, we describe the targeted pulse-routing implementation and required extensions to the BSS-2 software stack. We as well demonstrate feed-forward pulse-routing on BSS-2 using a scaled-down version without temporal merging.
Inference with Artificial Neural Networks on Analog Neuromorphic Hardware
Jul 01, 2020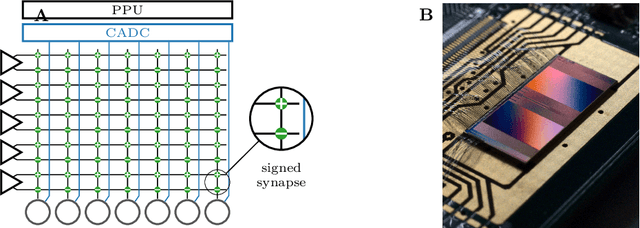

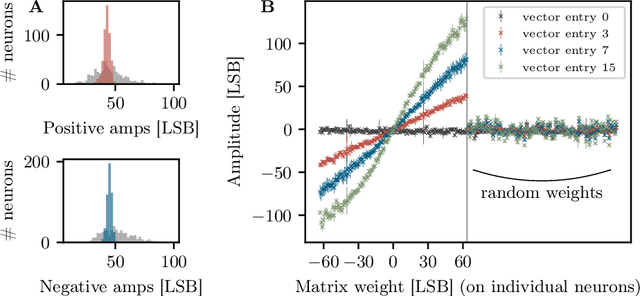
The neuromorphic BrainScaleS-2 ASIC comprises mixed-signal neurons and synapse circuits as well as two versatile digital microprocessors. Primarily designed to emulate spiking neural networks, the system can also operate in a vector-matrix multiplication and accumulation mode for artificial neural networks. Analog multiplication is carried out in the synapse circuits, while the results are accumulated on the neurons' membrane capacitors. Designed as an analog, in-memory computing device, it promises high energy efficiency. Fixed-pattern noise and trial-to-trial variations, however, require the implemented networks to cope with a certain level of perturbations. Further limitations are imposed by the digital resolution of the input values (5 bit), matrix weights (6 bit) and resulting neuron activations (8 bit). In this paper, we discuss BrainScaleS-2 as an analog inference accelerator and present calibration as well as optimization strategies, highlighting the advantages of training with hardware in the loop. Among other benchmarks, we classify the MNIST handwritten digits dataset using a two-dimensional convolution and two dense layers. We reach 98.0% test accuracy, closely matching the performance of the same network evaluated in software.
Training spiking multi-layer networks with surrogate gradients on an analog neuromorphic substrate
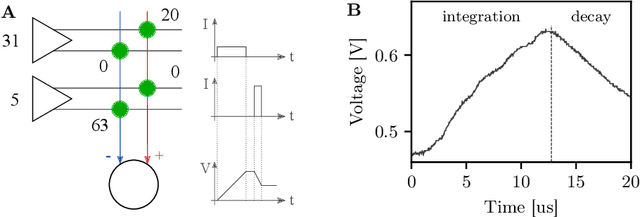
Jun 12, 2020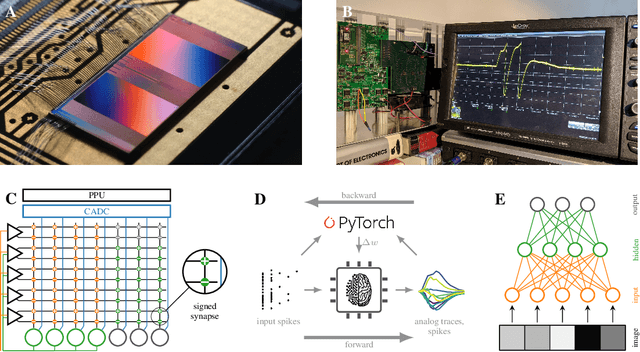

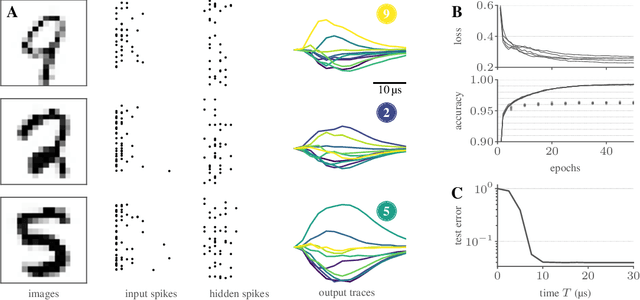
Spiking neural networks are nature's solution for parallel information processing with high temporal precision at a low metabolic energy cost. To that end, biological neurons integrate inputs as an analog sum and communicate their outputs digitally as spikes, i.e., sparse binary events in time. These architectural principles can be mirrored effectively in analog neuromorphic hardware. Nevertheless, training spiking neural networks with sparse activity on hardware devices remains a major challenge. Primarily this is due to the lack of suitable training methods that take into account device-specific imperfections and operate at the level of individual spikes instead of firing rates. To tackle this issue, we developed a hardware-in-the-loop strategy to train multi-layer spiking networks using surrogate gradients on the analog BrainScales-2 chip. Specifically, we used the hardware to compute the forward pass of the network, while the backward pass was computed in software. We evaluated our approach on downscaled 16x16 versions of the MNIST and the fashion MNIST datasets in which spike latencies encoded pixel intensities. The analog neuromorphic substrate closely matched the performance of equivalently sized networks implemented in software. It is capable of processing 70 k patterns per second with a power consumption of less than 300 mW. Added activity regularization resulted in sparse network activity with about 20 spikes per input, at little to no reduction in classification performance. Thus, overall, our work demonstrates low-energy spiking network processing on an analog neuromorphic substrate and sets several new benchmarks for hardware systems in terms of classification accuracy, processing speed, and efficiency. Importantly, our work emphasizes the value of hardware-in-the-loop training and paves the way toward energy-efficient information processing on non-von-Neumann architectures.
Verification and Design Methods for the BrainScaleS Neuromorphic Hardware System
Mar 25, 2020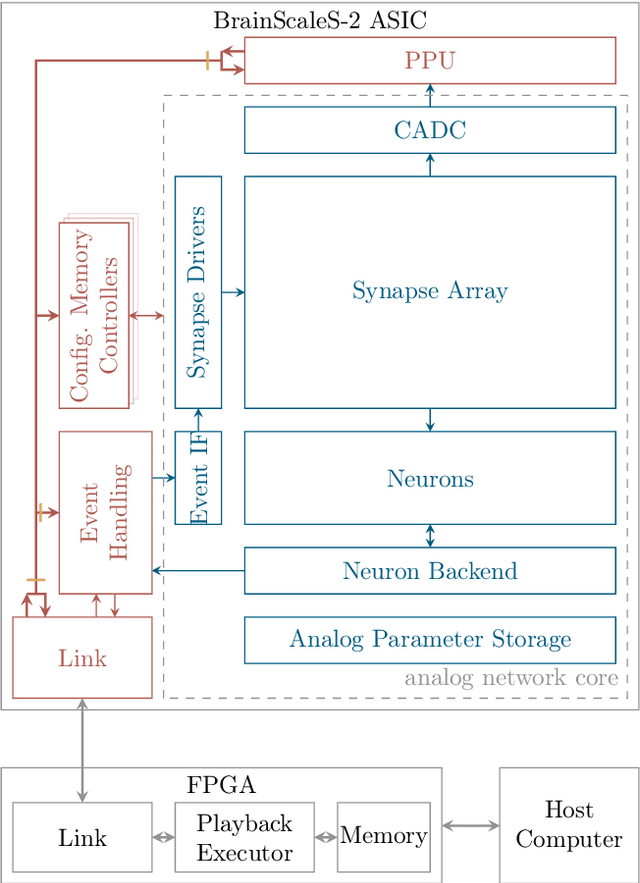

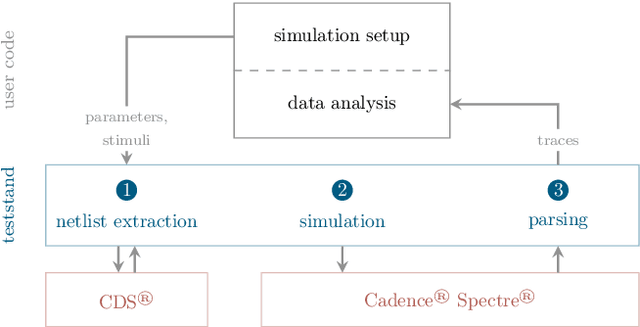
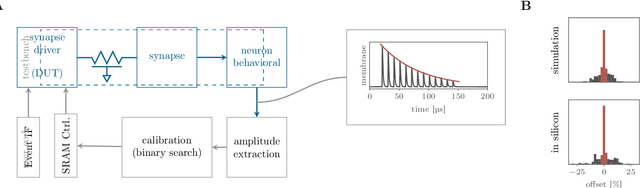
This paper presents verification and implementation methods that have been developed for the design of the BrainScaleS-2 65nm ASICs. The 2nd generation BrainScaleS chips are mixed-signal devices with tight coupling between full-custom analog neuromorphic circuits and two general purpose microprocessors (PPU) with SIMD extension for on-chip learning and plasticity. Simulation methods for automated analysis and pre-tapeout calibration of the highly parameterizable analog neuron and synapse circuits and for hardware-software co-development of the digital logic and software stack are presented. Accelerated operation of neuromorphic circuits and highly-parallel digital data buses between the full-custom neuromorphic part and the PPU require custom methodologies to close the digital signal timing at the interfaces. Novel extensions to the standard digital physical implementation design flow are highlighted. We present early results from the first full-size BrainScaleS-2 ASIC containing 512 neurons and 130K synapses, demonstrating the successful application of these methods. An application example illustrates the full functionality of the BrainScaleS-2 hybrid plasticity architecture.
Versatile emulation of spiking neural networks on an accelerated neuromorphic substrate
Dec 30, 2019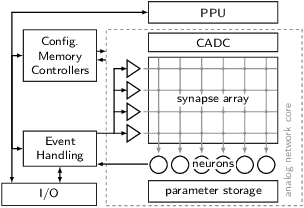
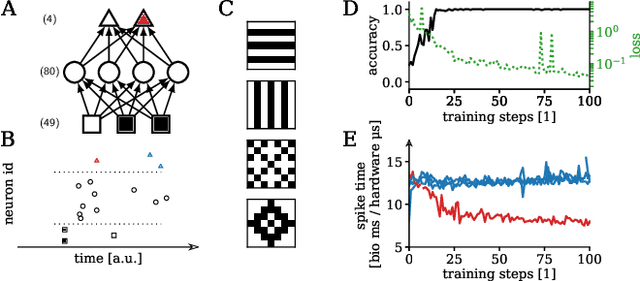
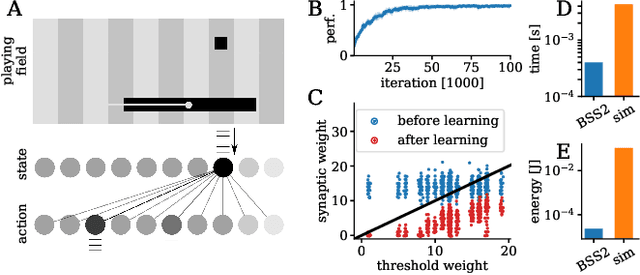
We present first experimental results on the novel BrainScaleS-2 neuromorphic architecture based on an analog neuro-synaptic core and augmented by embedded microprocessors for complex plasticity and experiment control. The high acceleration factor of 1000 compared to biological dynamics enables the execution of computationally expensive tasks, by allowing the fast emulation of long-duration experiments or rapid iteration over many consecutive trials. The flexibility of our architecture is demonstrated in a suite of five distinct experiments, which emphasize different aspects of the BrainScaleS-2 system.
Generative models on accelerated neuromorphic hardware
Jul 11, 2018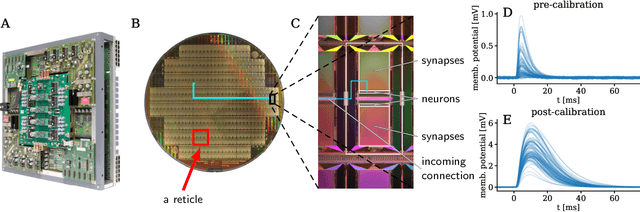
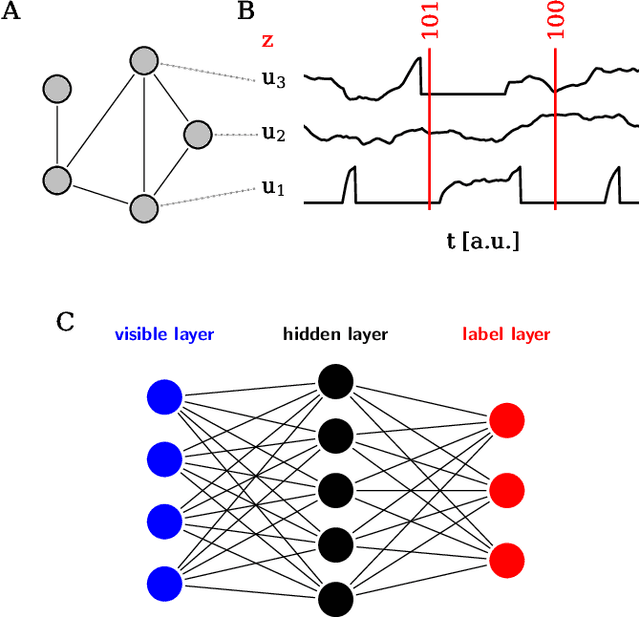
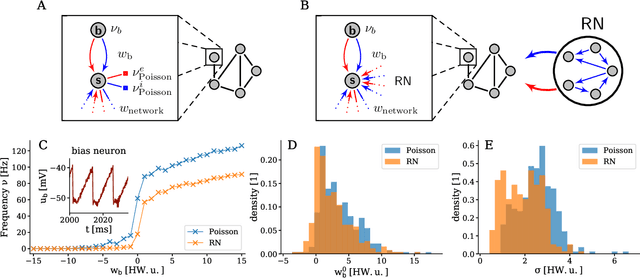
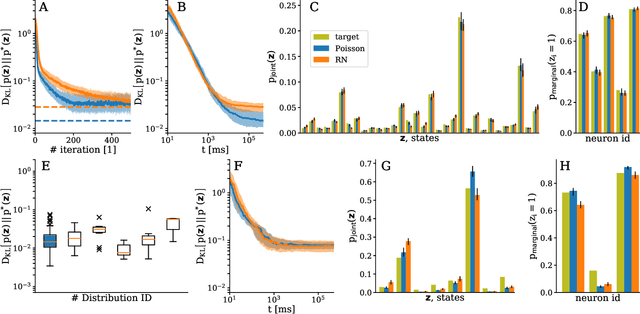
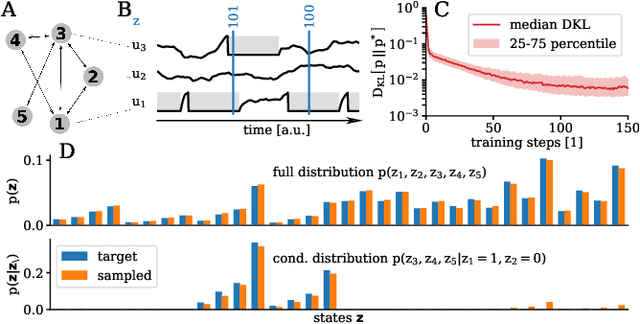
The traditional von Neumann computer architecture faces serious obstacles, both in terms of miniaturization and in terms of heat production, with increasing performance. Artificial neural (neuromorphic) substrates represent an alternative approach to tackle this challenge. A special subset of these systems follow the principle of "physical modeling" as they directly use the physical properties of the underlying substrate to realize computation with analog components. While these systems are potentially faster and/or more energy efficient than conventional computers, they require robust models that can cope with their inherent limitations in terms of controllability and range of parameters. A natural source of inspiration for robust models is neuroscience as the brain faces similar challenges. It has been recently suggested that sampling with the spiking dynamics of neurons is potentially suitable both as a generative and a discriminative model for artificial neural substrates. In this work we present the implementation of sampling with leaky integrate-and-fire neurons on the BrainScaleS physical model system. We prove the sampling property of the network and demonstrate its applicability to high-dimensional datasets. The required stochasticity is provided by a spiking random network on the same substrate. This allows the system to run in a self-contained fashion without external stochastic input from the host environment. The implementation provides a basis as a building block in large-scale biologically relevant emulations, as a fast approximate sampler or as a framework to realize on-chip learning on (future generations of) accelerated spiking neuromorphic hardware. Our work contributes to the development of robust computation on physical model systems.
Pattern representation and recognition with accelerated analog neuromorphic systems
Jul 03, 2017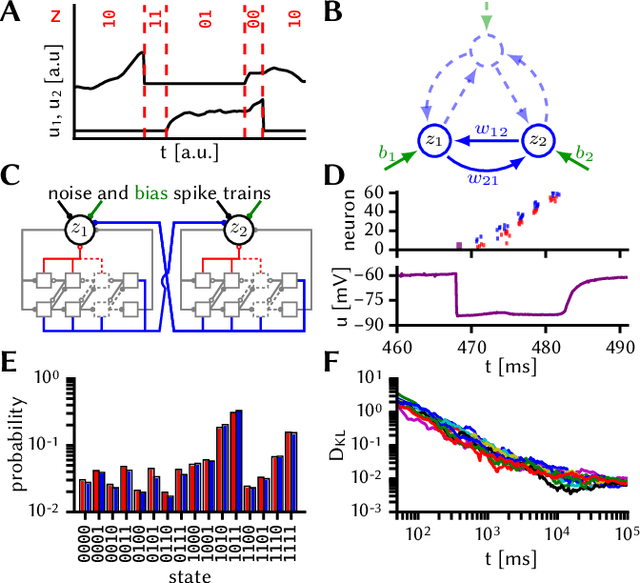

Despite being originally inspired by the central nervous system, artificial neural networks have diverged from their biological archetypes as they have been remodeled to fit particular tasks. In this paper, we review several possibilites to reverse map these architectures to biologically more realistic spiking networks with the aim of emulating them on fast, low-power neuromorphic hardware. Since many of these devices employ analog components, which cannot be perfectly controlled, finding ways to compensate for the resulting effects represents a key challenge. Here, we discuss three different strategies to address this problem: the addition of auxiliary network components for stabilizing activity, the utilization of inherently robust architectures and a training method for hardware-emulated networks that functions without perfect knowledge of the system's dynamics and parameters. For all three scenarios, we corroborate our theoretical considerations with experimental results on accelerated analog neuromorphic platforms.
* accepted at ISCAS 2017
Neuromorphic Hardware In The Loop: Training a Deep Spiking Network on the BrainScaleS Wafer-Scale System
Mar 06, 2017
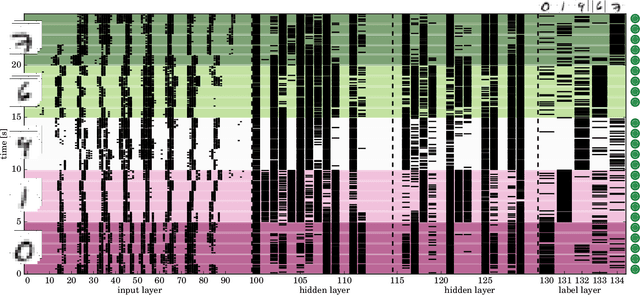
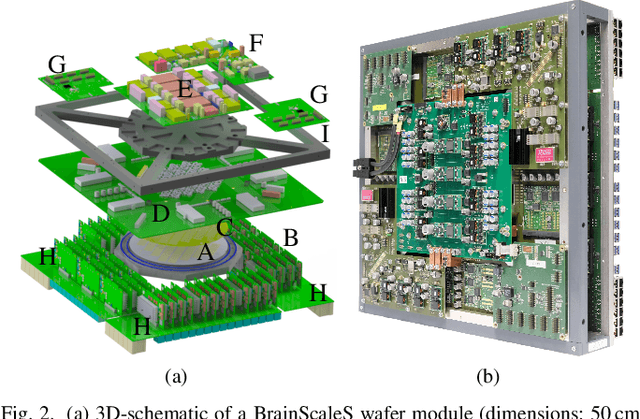
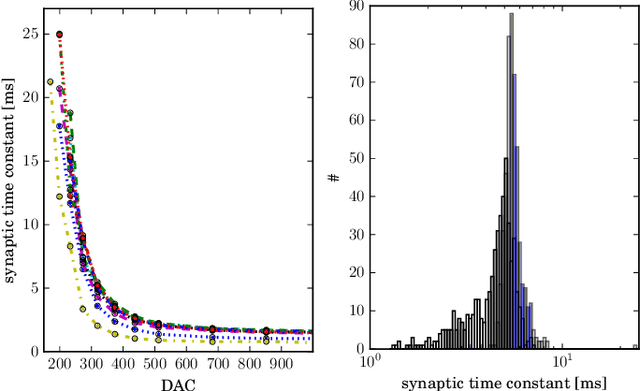
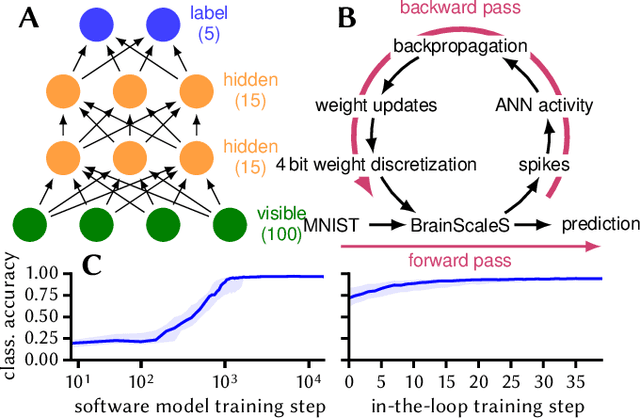
Emulating spiking neural networks on analog neuromorphic hardware offers several advantages over simulating them on conventional computers, particularly in terms of speed and energy consumption. However, this usually comes at the cost of reduced control over the dynamics of the emulated networks. In this paper, we demonstrate how iterative training of a hardware-emulated network can compensate for anomalies induced by the analog substrate. We first convert a deep neural network trained in software to a spiking network on the BrainScaleS wafer-scale neuromorphic system, thereby enabling an acceleration factor of 10 000 compared to the biological time domain. This mapping is followed by the in-the-loop training, where in each training step, the network activity is first recorded in hardware and then used to compute the parameter updates in software via backpropagation. An essential finding is that the parameter updates do not have to be precise, but only need to approximately follow the correct gradient, which simplifies the computation of updates. Using this approach, after only several tens of iterations, the spiking network shows an accuracy close to the ideal software-emulated prototype. The presented techniques show that deep spiking networks emulated on analog neuromorphic devices can attain good computational performance despite the inherent variations of the analog substrate.