 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSmoothly Differentiable and Efficiently Vectorizable Contact Manifold Generation
Feb 23, 2026Simulating rigid-body dynamics with contact in a fast, massively vectorizable, and smoothly differentiable manner is highly desirable in robotics. An important bottleneck faced by existing differentiable simulation frameworks is contact manifold generation: representing the volume of intersection between two colliding geometries via a discrete set of properly distributed contact points. A major factor contributing to this bottleneck is that the related routines of commonly used robotics simulators were not designed with vectorization and differentiability as a primary concern, and thus rely on logic and control flow that hinder these goals. We instead propose a framework designed from the ground up with these goals in mind, by trying to strike a middle ground between: i) convex primitive based approaches used by common robotics simulators (efficient but not differentiable), and ii) mollified vertex-face and edge-edge unsigned distance-based approaches used by barrier methods (differentiable but inefficient). Concretely, we propose: i) a representative set of smooth analytical signed distance primitives to implement vertex-face collisions, and ii) a novel differentiable edge-edge collision routine that can provide signed distances and signed contact normals. The proposed framework is evaluated via a set of didactic experiments and benchmarked against the collision detection routine of the well-established Mujoco XLA framework, where we observe a significant speedup. Supplementary videos can be found at https://github.com/bekeronur/contax, where a reference implementation in JAX will also be made available at the conclusion of the review process.
A Smooth Analytical Formulation of Collision Detection and Rigid Body Dynamics With Contact
Mar 14, 2025Generating intelligent robot behavior in contact-rich settings is a research problem where zeroth-order methods currently prevail. A major contributor to the success of such methods is their robustness in the face of non-smooth and discontinuous optimization landscapes that are characteristic of contact interactions, yet zeroth-order methods remain computationally inefficient. It is therefore desirable to develop methods for perception, planning and control in contact-rich settings that can achieve further efficiency by making use of first and second order information (i.e., gradients and Hessians). To facilitate this, we present a joint formulation of collision detection and contact modelling which, compared to existing differentiable simulation approaches, provides the following benefits: i) it results in forward and inverse dynamics that are entirely analytical (i.e. do not require solving optimization or root-finding problems with iterative methods) and smooth (i.e. twice differentiable), ii) it supports arbitrary collision geometries without needing a convex decomposition, and iii) its runtime is independent of the number of contacts. Through simulation experiments, we demonstrate the validity of the proposed formulation as a "physics for inference" that can facilitate future development of efficient methods to generate intelligent contact-rich behavior.
Zero-Shot Offline Imitation Learning via Optimal Transport
Oct 11, 2024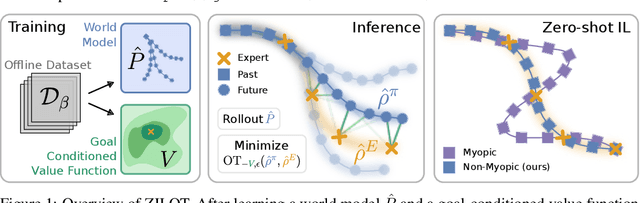
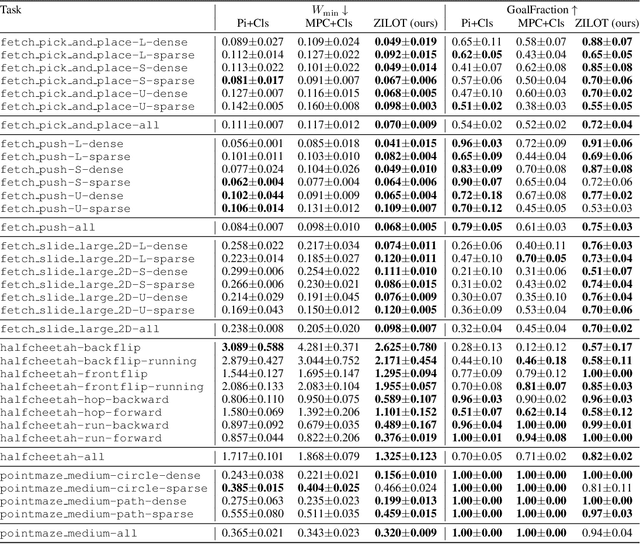
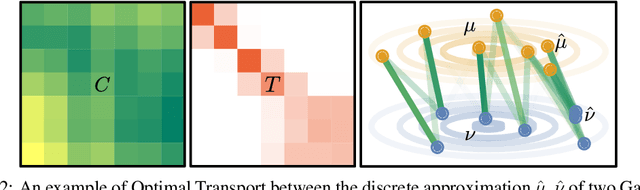
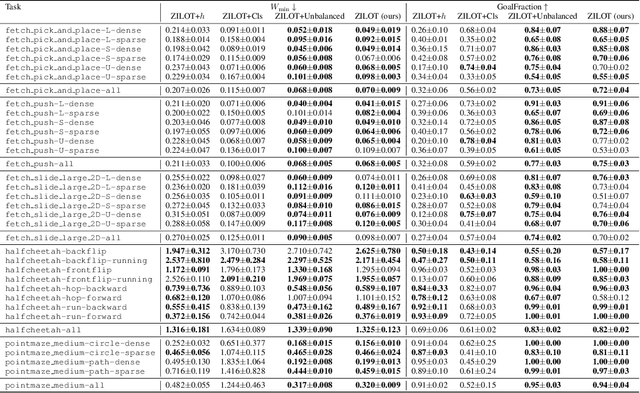
Zero-shot imitation learning algorithms hold the promise of reproducing unseen behavior from as little as a single demonstration at test time. Existing practical approaches view the expert demonstration as a sequence of goals, enabling imitation with a high-level goal selector, and a low-level goal-conditioned policy. However, this framework can suffer from myopic behavior: the agent's immediate actions towards achieving individual goals may undermine long-term objectives. We introduce a novel method that mitigates this issue by directly optimizing the occupancy matching objective that is intrinsic to imitation learning. We propose to lift a goal-conditioned value function to a distance between occupancies, which are in turn approximated via a learned world model. The resulting method can learn from offline, suboptimal data, and is capable of non-myopic, zero-shot imitation, as we demonstrate in complex, continuous benchmarks.
Real Robot Challenge 2022: Learning Dexterous Manipulation from Offline Data in the Real World
Sep 04, 2023Experimentation on real robots is demanding in terms of time and costs. For this reason, a large part of the reinforcement learning (RL) community uses simulators to develop and benchmark algorithms. However, insights gained in simulation do not necessarily translate to real robots, in particular for tasks involving complex interactions with the environment. The Real Robot Challenge 2022 therefore served as a bridge between the RL and robotics communities by allowing participants to experiment remotely with a real robot - as easily as in simulation. In the last years, offline reinforcement learning has matured into a promising paradigm for learning from pre-collected datasets, alleviating the reliance on expensive online interactions. We therefore asked the participants to learn two dexterous manipulation tasks involving pushing, grasping, and in-hand orientation from provided real-robot datasets. An extensive software documentation and an initial stage based on a simulation of the real set-up made the competition particularly accessible. By giving each team plenty of access budget to evaluate their offline-learned policies on a cluster of seven identical real TriFinger platforms, we organized an exciting competition for machine learners and roboticists alike. In this work we state the rules of the competition, present the methods used by the winning teams and compare their results with a benchmark of state-of-the-art offline RL algorithms on the challenge datasets.
Benchmarking Offline Reinforcement Learning on Real-Robot Hardware
Jul 28, 2023



Learning policies from previously recorded data is a promising direction for real-world robotics tasks, as online learning is often infeasible. Dexterous manipulation in particular remains an open problem in its general form. The combination of offline reinforcement learning with large diverse datasets, however, has the potential to lead to a breakthrough in this challenging domain analogously to the rapid progress made in supervised learning in recent years. To coordinate the efforts of the research community toward tackling this problem, we propose a benchmark including: i) a large collection of data for offline learning from a dexterous manipulation platform on two tasks, obtained with capable RL agents trained in simulation; ii) the option to execute learned policies on a real-world robotic system and a simulation for efficient debugging. We evaluate prominent open-sourced offline reinforcement learning algorithms on the datasets and provide a reproducible experimental setup for offline reinforcement learning on real systems.
Hierarchical Reinforcement Learning with Timed Subgoals
Dec 06, 2021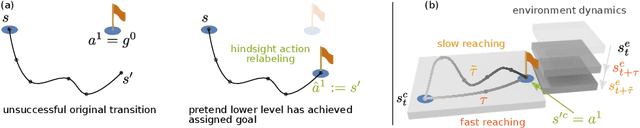
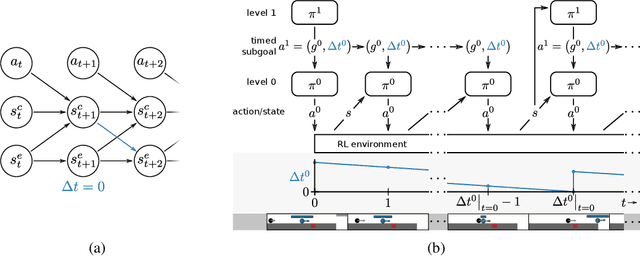
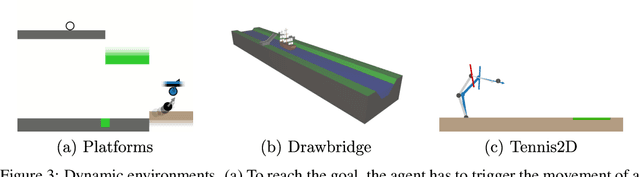
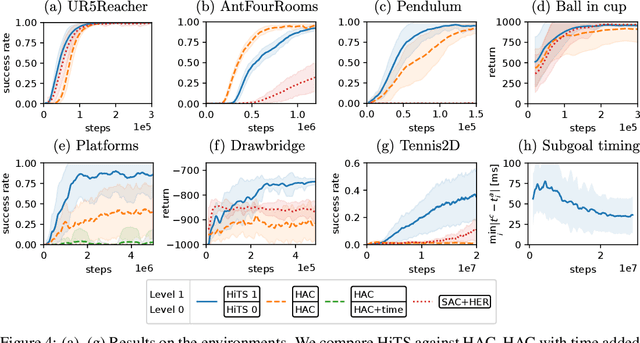
Hierarchical reinforcement learning (HRL) holds great potential for sample-efficient learning on challenging long-horizon tasks. In particular, letting a higher level assign subgoals to a lower level has been shown to enable fast learning on difficult problems. However, such subgoal-based methods have been designed with static reinforcement learning environments in mind and consequently struggle with dynamic elements beyond the immediate control of the agent even though they are ubiquitous in real-world problems. In this paper, we introduce Hierarchical reinforcement learning with Timed Subgoals (HiTS), an HRL algorithm that enables the agent to adapt its timing to a dynamic environment by not only specifying what goal state is to be reached but also when. We discuss how communicating with a lower level in terms of such timed subgoals results in a more stable learning problem for the higher level. Our experiments on a range of standard benchmarks and three new challenging dynamic reinforcement learning environments show that our method is capable of sample-efficient learning where an existing state-of-the-art subgoal-based HRL method fails to learn stable solutions.
Direct Advantage Estimation
Sep 13, 2021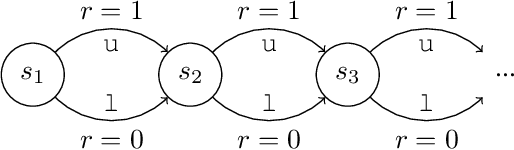
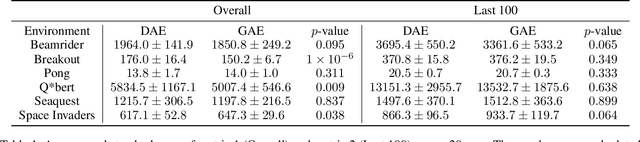
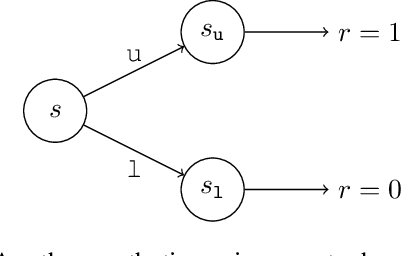

Credit assignment is one of the central problems in reinforcement learning. The predominant approach is to assign credit based on the expected return. However, we show that the expected return may depend on the policy in an undesirable way which could slow down learning. Instead, we borrow ideas from the causality literature and show that the advantage function can be interpreted as causal effects, which share similar properties with causal representations. Based on this insight, we propose the Direct Advantage Estimation (DAE), a novel method that can model the advantage function and estimate it directly from data without requiring the (action-)value function. If desired, value functions can also be seamlessly integrated into DAE and be updated in a similar way to Temporal Difference Learning. The proposed method is easy to implement and can be readily adopted by modern actor-critic methods. We test DAE empirically on the Atari domain and show that it can achieve competitive results with the state-of-the-art method for advantage estimation.
Generative models on accelerated neuromorphic hardware
Jul 11, 2018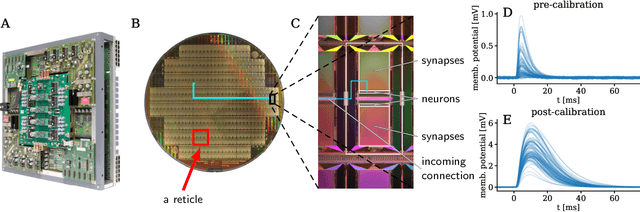
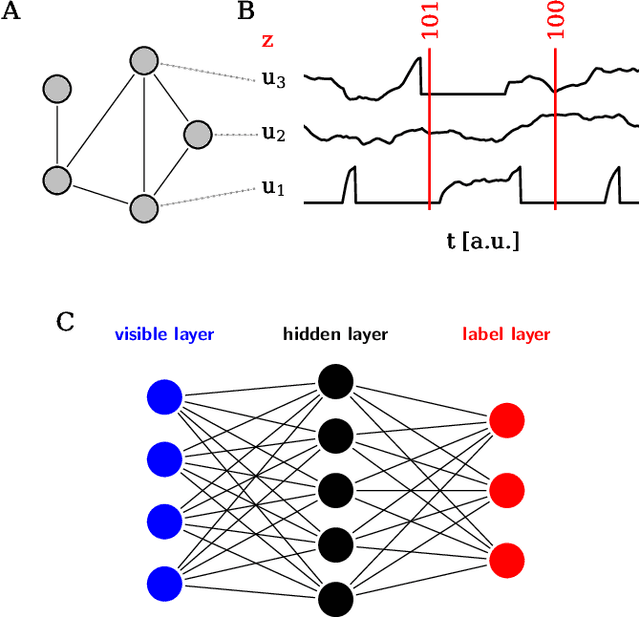
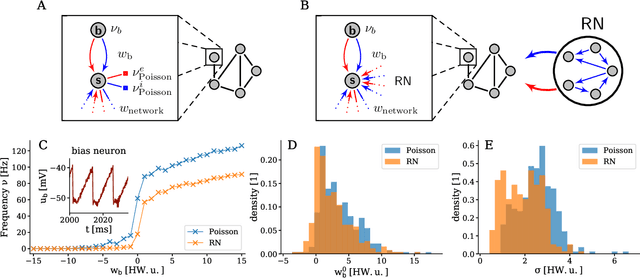
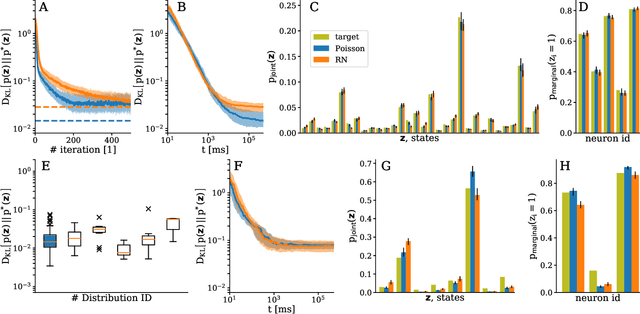
The traditional von Neumann computer architecture faces serious obstacles, both in terms of miniaturization and in terms of heat production, with increasing performance. Artificial neural (neuromorphic) substrates represent an alternative approach to tackle this challenge. A special subset of these systems follow the principle of "physical modeling" as they directly use the physical properties of the underlying substrate to realize computation with analog components. While these systems are potentially faster and/or more energy efficient than conventional computers, they require robust models that can cope with their inherent limitations in terms of controllability and range of parameters. A natural source of inspiration for robust models is neuroscience as the brain faces similar challenges. It has been recently suggested that sampling with the spiking dynamics of neurons is potentially suitable both as a generative and a discriminative model for artificial neural substrates. In this work we present the implementation of sampling with leaky integrate-and-fire neurons on the BrainScaleS physical model system. We prove the sampling property of the network and demonstrate its applicability to high-dimensional datasets. The required stochasticity is provided by a spiking random network on the same substrate. This allows the system to run in a self-contained fashion without external stochastic input from the host environment. The implementation provides a basis as a building block in large-scale biologically relevant emulations, as a fast approximate sampler or as a framework to realize on-chip learning on (future generations of) accelerated spiking neuromorphic hardware. Our work contributes to the development of robust computation on physical model systems.