 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSkill or Luck? Return Decomposition via Advantage Functions
Feb 20, 2024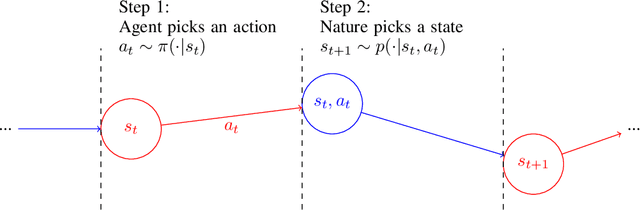
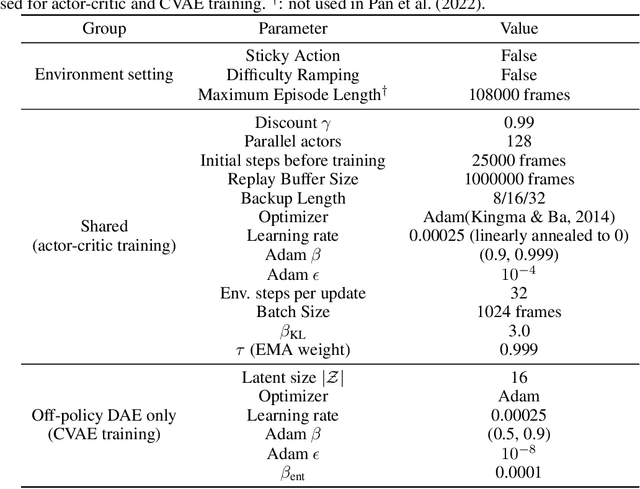
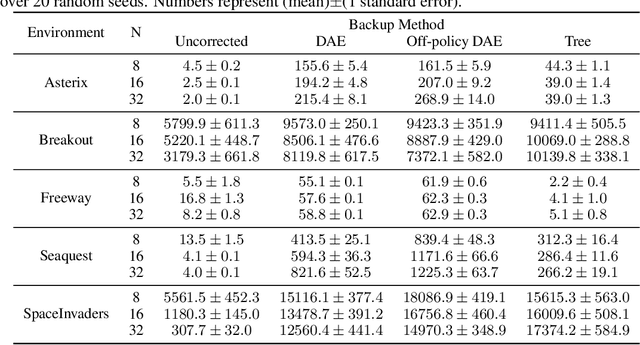
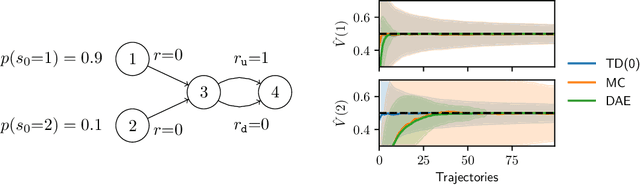
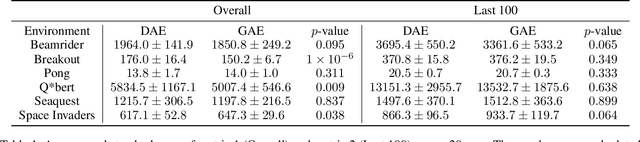
Learning from off-policy data is essential for sample-efficient reinforcement learning. In the present work, we build on the insight that the advantage function can be understood as the causal effect of an action on the return, and show that this allows us to decompose the return of a trajectory into parts caused by the agent's actions (skill) and parts outside of the agent's control (luck). Furthermore, this decomposition enables us to naturally extend Direct Advantage Estimation (DAE) to off-policy settings (Off-policy DAE). The resulting method can learn from off-policy trajectories without relying on importance sampling techniques or truncating off-policy actions. We draw connections between Off-policy DAE and previous methods to demonstrate how it can speed up learning and when the proposed off-policy corrections are important. Finally, we use the MinAtar environments to illustrate how ignoring off-policy corrections can lead to suboptimal policy optimization performance.
Homomorphism Autoencoder -- Learning Group Structured Representations from Observed Transitions
Jul 25, 2022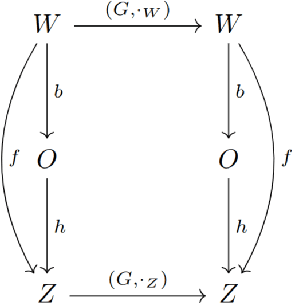

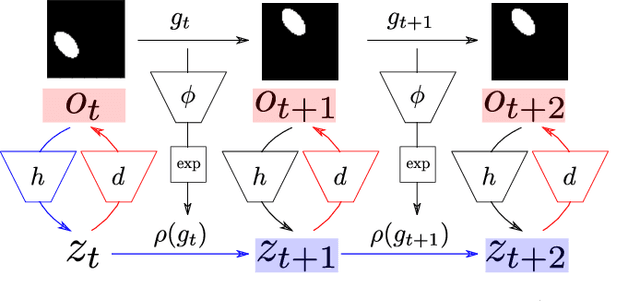

How can we acquire world models that veridically represent the outside world both in terms of what is there and in terms of how our actions affect it? Can we acquire such models by interacting with the world, and can we state mathematical desiderata for their relationship with a hypothetical reality existing outside our heads? As machine learning is moving towards representations containing not just observational but also interventional knowledge, we study these problems using tools from representation learning and group theory. Under the assumption that our actuators act upon the world, we propose methods to learn internal representations of not just sensory information but also of actions that modify our sensory representations in a way that is consistent with the actions and transitions in the world. We use an autoencoder equipped with a group representation linearly acting on its latent space, trained on 2-step reconstruction such as to enforce a suitable homomorphism property on the group representation. Compared to existing work, our approach makes fewer assumptions on the group representation and on which transformations the agent can sample from the group. We motivate our method theoretically, and demonstrate empirically that it can learn the correct representation of the groups and the topology of the environment. We also compare its performance in trajectory prediction with previous methods.
Direct Advantage Estimation
Sep 13, 2021
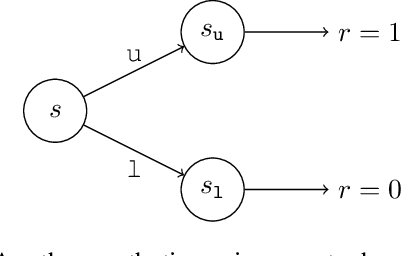

Credit assignment is one of the central problems in reinforcement learning. The predominant approach is to assign credit based on the expected return. However, we show that the expected return may depend on the policy in an undesirable way which could slow down learning. Instead, we borrow ideas from the causality literature and show that the advantage function can be interpreted as causal effects, which share similar properties with causal representations. Based on this insight, we propose the Direct Advantage Estimation (DAE), a novel method that can model the advantage function and estimate it directly from data without requiring the (action-)value function. If desired, value functions can also be seamlessly integrated into DAE and be updated in a similar way to Temporal Difference Learning. The proposed method is easy to implement and can be readily adopted by modern actor-critic methods. We test DAE empirically on the Atari domain and show that it can achieve competitive results with the state-of-the-art method for advantage estimation.