 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeFM: Learning Foundation Representations from Depth for Robotics
Jan 26, 2026Depth sensors are widely deployed across robotic platforms, and advances in fast, high-fidelity depth simulation have enabled robotic policies trained on depth observations to achieve robust sim-to-real transfer for a wide range of tasks. Despite this, representation learning for depth modality remains underexplored compared to RGB, where large-scale foundation models now define the state of the art. To address this gap, we present DeFM, a self-supervised foundation model trained entirely on depth images for robotic applications. Using a DINO-style self-distillation objective on a curated dataset of 60M depth images, DeFM learns geometric and semantic representations that generalize to diverse environments, tasks, and sensors. To retain metric awareness across multiple scales, we introduce a novel input normalization strategy. We further distill DeFM into compact models suitable for resource-constrained robotic systems. When evaluated on depth-based classification, segmentation, navigation, locomotion, and manipulation benchmarks, DeFM achieves state-of-the-art performance and demonstrates strong generalization from simulation to real-world environments. We release all our pretrained models, which can be adopted off-the-shelf for depth-based robotic learning without task-specific fine-tuning. Webpage: https://de-fm.github.io/
Less Is More: Scalable Visual Navigation from Limited Data
Jan 25, 2026Imitation learning provides a powerful framework for goal-conditioned visual navigation in mobile robots, enabling obstacle avoidance while respecting human preferences and social norms. However, its effectiveness depends critically on the quality and diversity of training data. In this work, we show how classical geometric planners can be leveraged to generate synthetic trajectories that complement costly human demonstrations. We train Less is More (LiMo), a transformer-based visual navigation policy that predicts goal-conditioned SE(2) trajectories from a single RGB observation, and find that augmenting limited expert demonstrations with planner-generated supervision yields substantial performance gains. Through ablations and complementary qualitative and quantitative analyses, we characterize how dataset scale and diversity affect planning performance. We demonstrate real-robot deployment and argue that robust visual navigation is enabled not by simply collecting more demonstrations, but by strategically curating diverse, high-quality datasets. Our results suggest that scalable, embodiment-specific geometric supervision is a practical path toward data-efficient visual navigation.
VLD: Visual Language Goal Distance for Reinforcement Learning Navigation
Dec 08, 2025Training end-to-end policies from image data to directly predict navigation actions for robotic systems has proven inherently difficult. Existing approaches often suffer from either the sim-to-real gap during policy transfer or a limited amount of training data with action labels. To address this problem, we introduce Vision-Language Distance (VLD) learning, a scalable framework for goal-conditioned navigation that decouples perception learning from policy learning. Instead of relying on raw sensory inputs during policy training, we first train a self-supervised distance-to-goal predictor on internet-scale video data. This predictor generalizes across both image- and text-based goals, providing a distance signal that can be minimized by a reinforcement learning (RL) policy. The RL policy can be trained entirely in simulation using privileged geometric distance signals, with injected noise to mimic the uncertainty of the trained distance predictor. At deployment, the policy consumes VLD predictions, inheriting semantic goal information-"where to go"-from large-scale visual training while retaining the robust low-level navigation behaviors learned in simulation. We propose using ordinal consistency to assess distance functions directly and demonstrate that VLD outperforms prior temporal distance approaches, such as ViNT and VIP. Experiments show that our decoupled design achieves competitive navigation performance in simulation while supporting flexible goal modalities, providing an alternative and, most importantly, scalable path toward reliable, multimodal navigation policies.
NaviTrace: Evaluating Embodied Navigation of Vision-Language Models
Oct 30, 2025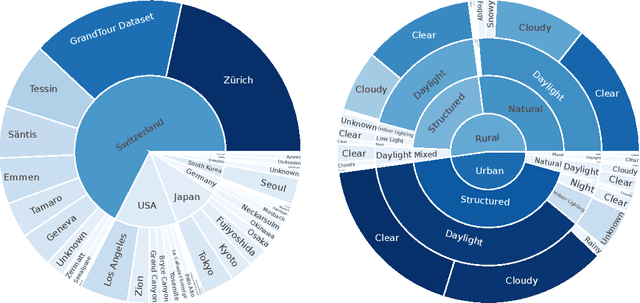
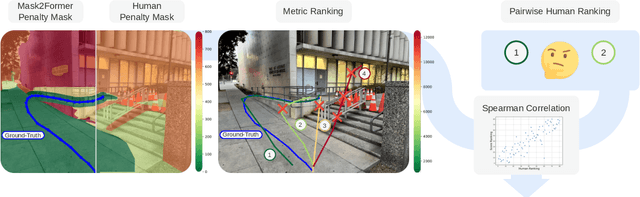
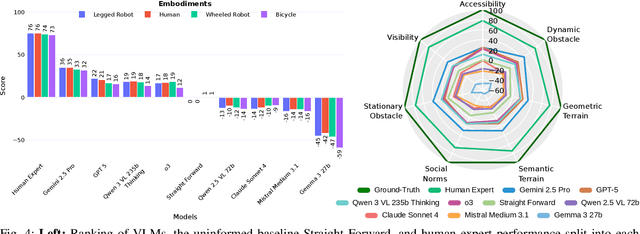
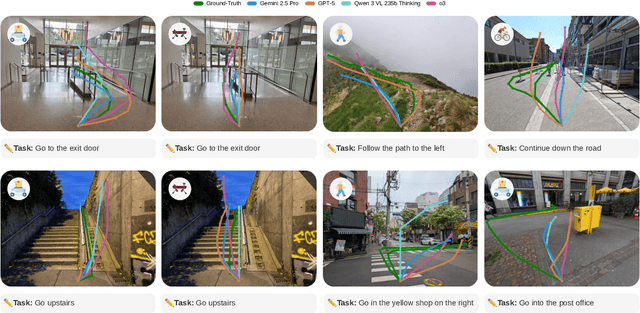
Vision-language models demonstrate unprecedented performance and generalization across a wide range of tasks and scenarios. Integrating these foundation models into robotic navigation systems opens pathways toward building general-purpose robots. Yet, evaluating these models' navigation capabilities remains constrained by costly real-world trials, overly simplified simulations, and limited benchmarks. We introduce NaviTrace, a high-quality Visual Question Answering benchmark where a model receives an instruction and embodiment type (human, legged robot, wheeled robot, bicycle) and must output a 2D navigation trace in image space. Across 1000 scenarios and more than 3000 expert traces, we systematically evaluate eight state-of-the-art VLMs using a newly introduced semantic-aware trace score. This metric combines Dynamic Time Warping distance, goal endpoint error, and embodiment-conditioned penalties derived from per-pixel semantics and correlates with human preferences. Our evaluation reveals consistent gap to human performance caused by poor spatial grounding and goal localization. NaviTrace establishes a scalable and reproducible benchmark for real-world robotic navigation. The benchmark and leaderboard can be found at https://leggedrobotics.github.io/navitrace_webpage/.
DAPPER: Discriminability-Aware Policy-to-Policy Preference-Based Reinforcement Learning for Query-Efficient Robot Skill Acquisition
May 09, 2025
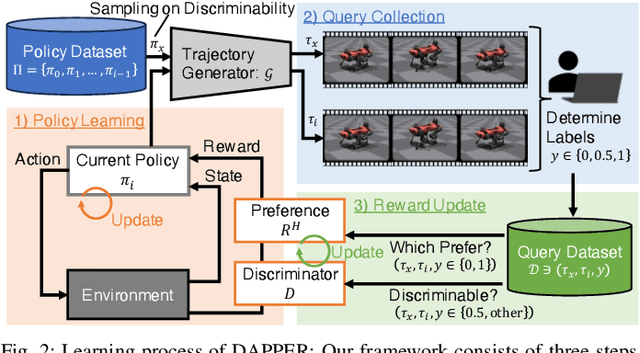

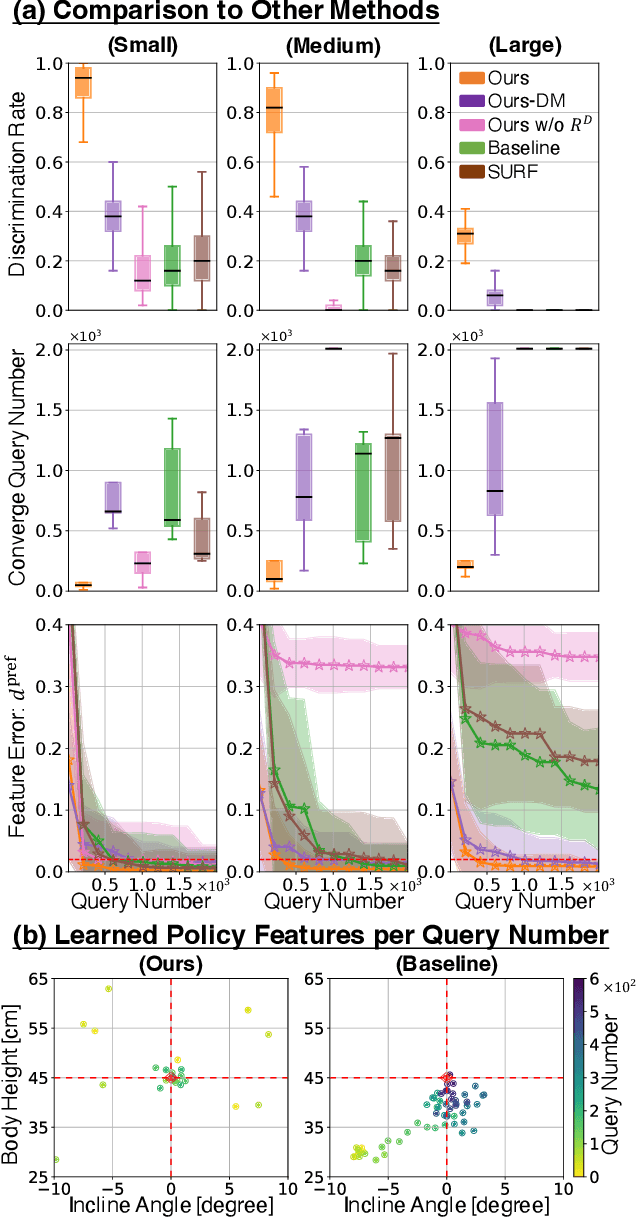
Preference-based Reinforcement Learning (PbRL) enables policy learning through simple queries comparing trajectories from a single policy. While human responses to these queries make it possible to learn policies aligned with human preferences, PbRL suffers from low query efficiency, as policy bias limits trajectory diversity and reduces the number of discriminable queries available for learning preferences. This paper identifies preference discriminability, which quantifies how easily a human can judge which trajectory is closer to their ideal behavior, as a key metric for improving query efficiency. To address this, we move beyond comparisons within a single policy and instead generate queries by comparing trajectories from multiple policies, as training them from scratch promotes diversity without policy bias. We propose Discriminability-Aware Policy-to-Policy Preference-Based Efficient Reinforcement Learning (DAPPER), which integrates preference discriminability with trajectory diversification achieved by multiple policies. DAPPER trains new policies from scratch after each reward update and employs a discriminator that learns to estimate preference discriminability, enabling the prioritized sampling of more discriminable queries. During training, it jointly maximizes the preference reward and preference discriminability score, encouraging the discovery of highly rewarding and easily distinguishable policies. Experiments in simulated and real-world legged robot environments demonstrate that DAPPER outperforms previous methods in query efficiency, particularly under challenging preference discriminability conditions.
Learned Perceptive Forward Dynamics Model for Safe and Platform-aware Robotic Navigation
Apr 29, 2025
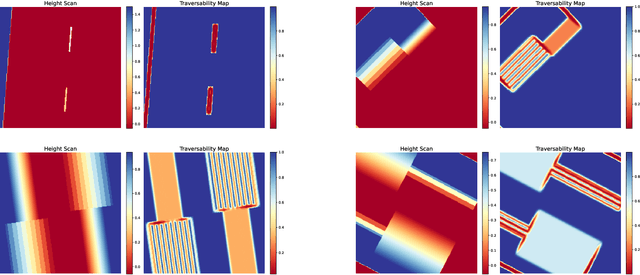
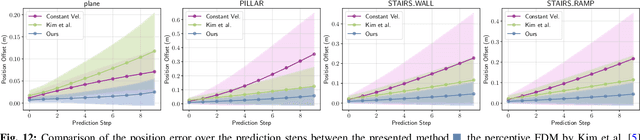
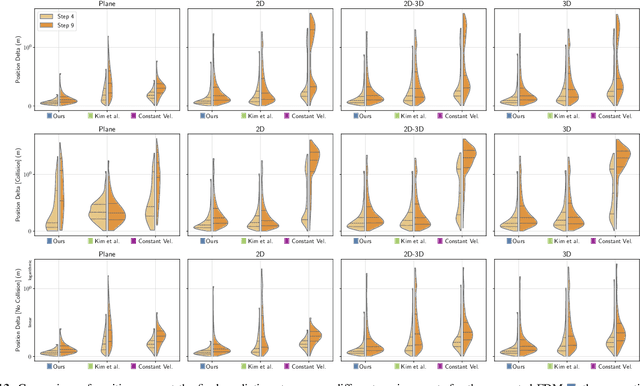
Ensuring safe navigation in complex environments requires accurate real-time traversability assessment and understanding of environmental interactions relative to the robot`s capabilities. Traditional methods, which assume simplified dynamics, often require designing and tuning cost functions to safely guide paths or actions toward the goal. This process is tedious, environment-dependent, and not generalizable. To overcome these issues, we propose a novel learned perceptive Forward Dynamics Model (FDM) that predicts the robot`s future state conditioned on the surrounding geometry and history of proprioceptive measurements, proposing a more scalable, safer, and heuristic-free solution. The FDM is trained on multiple years of simulated navigation experience, including high-risk maneuvers, and real-world interactions to incorporate the full system dynamics beyond rigid body simulation. We integrate our perceptive FDM into a zero-shot Model Predictive Path Integral (MPPI) planning framework, leveraging the learned mapping between actions, future states, and failure probability. This allows for optimizing a simplified cost function, eliminating the need for extensive cost-tuning to ensure safety. On the legged robot ANYmal, the proposed perceptive FDM improves the position estimation by on average 41% over competitive baselines, which translates into a 27% higher navigation success rate in rough simulation environments. Moreover, we demonstrate effective sim-to-real transfer and showcase the benefit of training on synthetic and real data. Code and models are made publicly available under https://github.com/leggedrobotics/fdm.
Boxi: Design Decisions in the Context of Algorithmic Performance for Robotics
Apr 25, 2025Achieving robust autonomy in mobile robots operating in complex and unstructured environments requires a multimodal sensor suite capable of capturing diverse and complementary information. However, designing such a sensor suite involves multiple critical design decisions, such as sensor selection, component placement, thermal and power limitations, compute requirements, networking, synchronization, and calibration. While the importance of these key aspects is widely recognized, they are often overlooked in academia or retained as proprietary knowledge within large corporations. To improve this situation, we present Boxi, a tightly integrated sensor payload that enables robust autonomy of robots in the wild. This paper discusses the impact of payload design decisions made to optimize algorithmic performance for downstream tasks, specifically focusing on state estimation and mapping. Boxi is equipped with a variety of sensors: two LiDARs, 10 RGB cameras including high-dynamic range, global shutter, and rolling shutter models, an RGB-D camera, 7 inertial measurement units (IMUs) of varying precision, and a dual antenna RTK GNSS system. Our analysis shows that time synchronization, calibration, and sensor modality have a crucial impact on the state estimation performance. We frame this analysis in the context of cost considerations and environment-specific challenges. We also present a mobile sensor suite `cookbook` to serve as a comprehensive guideline, highlighting generalizable key design considerations and lessons learned during the development of Boxi. Finally, we demonstrate the versatility of Boxi being used in a variety of applications in real-world scenarios, contributing to robust autonomy. More details and code: https://github.com/leggedrobotics/grand_tour_box
Diffusion Based Robust LiDAR Place Recognition
Apr 16, 2025Mobile robots on construction sites require accurate pose estimation to perform autonomous surveying and inspection missions. Localization in construction sites is a particularly challenging problem due to the presence of repetitive features such as flat plastered walls and perceptual aliasing due to apartments with similar layouts inter and intra floors. In this paper, we focus on the global re-positioning of a robot with respect to an accurate scanned mesh of the building solely using LiDAR data. In our approach, a neural network is trained on synthetic LiDAR point clouds generated by simulating a LiDAR in an accurate real-life large-scale mesh. We train a diffusion model with a PointNet++ backbone, which allows us to model multiple position candidates from a single LiDAR point cloud. The resulting model can successfully predict the global position of LiDAR in confined and complex sites despite the adverse effects of perceptual aliasing. The learned distribution of potential global positions can provide multi-modal position distribution. We evaluate our approach across five real-world datasets and show the place recognition accuracy of 77% +/-2m on average while outperforming baselines at a factor of 2 in mean error.
Holistic Fusion: Task- and Setup-Agnostic Robot Localization and State Estimation with Factor Graphs
Apr 08, 2025Seamless operation of mobile robots in challenging environments requires low-latency local motion estimation (e.g., dynamic maneuvers) and accurate global localization (e.g., wayfinding). While most existing sensor-fusion approaches are designed for specific scenarios, this work introduces a flexible open-source solution for task- and setup-agnostic multimodal sensor fusion that is distinguished by its generality and usability. Holistic Fusion formulates sensor fusion as a combined estimation problem of i) the local and global robot state and ii) a (theoretically unlimited) number of dynamic context variables, including automatic alignment of reference frames; this formulation fits countless real-world applications without any conceptual modifications. The proposed factor-graph solution enables the direct fusion of an arbitrary number of absolute, local, and landmark measurements expressed with respect to different reference frames by explicitly including them as states in the optimization and modeling their evolution as random walks. Moreover, local smoothness and consistency receive particular attention to prevent jumps in the robot state belief. HF enables low-latency and smooth online state estimation on typical robot hardware while simultaneously providing low-drift global localization at the IMU measurement rate. The efficacy of this released framework is demonstrated in five real-world scenarios on three robotic platforms, each with distinct task requirements.
Zero-Shot Offline Imitation Learning via Optimal Transport
Oct 11, 2024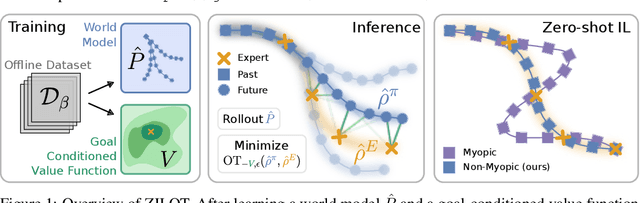
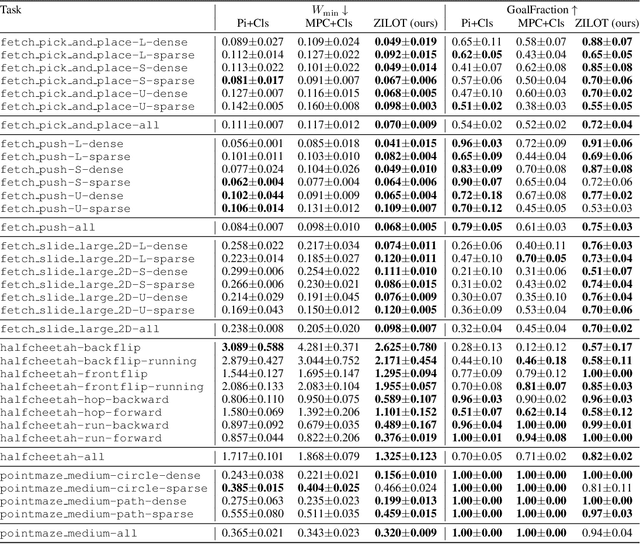
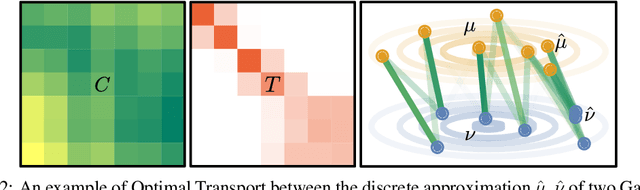
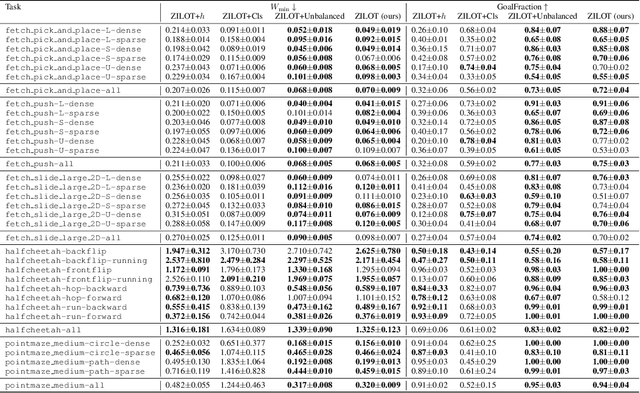
Zero-shot imitation learning algorithms hold the promise of reproducing unseen behavior from as little as a single demonstration at test time. Existing practical approaches view the expert demonstration as a sequence of goals, enabling imitation with a high-level goal selector, and a low-level goal-conditioned policy. However, this framework can suffer from myopic behavior: the agent's immediate actions towards achieving individual goals may undermine long-term objectives. We introduce a novel method that mitigates this issue by directly optimizing the occupancy matching objective that is intrinsic to imitation learning. We propose to lift a goal-conditioned value function to a distance between occupancies, which are in turn approximated via a learned world model. The resulting method can learn from offline, suboptimal data, and is capable of non-myopic, zero-shot imitation, as we demonstrate in complex, continuous benchmarks.