 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural timescales from a computational perspective
Sep 04, 2024



Timescales of neural activity are diverse across and within brain areas, and experimental observations suggest that neural timescales reflect information in dynamic environments. However, these observations do not specify how neural timescales are shaped, nor whether particular timescales are necessary for neural computations and brain function. Here, we take a complementary perspective and synthesize three directions where computational methods can distill the broad set of empirical observations into quantitative and testable theories: We review (i) how data analysis methods allow us to capture different timescales of neural dynamics across different recording modalities, (ii) how computational models provide a mechanistic explanation for the emergence of diverse timescales, and (iii) how task-optimized models in machine learning uncover the functional relevance of neural timescales. This integrative computational approach, combined with empirical findings, would provide a more holistic understanding of how neural timescales capture the relationship between brain structure, dynamics, and behavior.
Modular Growth of Hierarchical Networks: Efficient, General, and Robust Curriculum Learning
Jun 10, 2024Structural modularity is a pervasive feature of biological neural networks, which have been linked to several functional and computational advantages. Yet, the use of modular architectures in artificial neural networks has been relatively limited despite early successes. Here, we explore the performance and functional dynamics of a modular network trained on a memory task via an iterative growth curriculum. We find that for a given classical, non-modular recurrent neural network (RNN), an equivalent modular network will perform better across multiple metrics, including training time, generalizability, and robustness to some perturbations. We further examine how different aspects of a modular network's connectivity contribute to its computational capability. We then demonstrate that the inductive bias introduced by the modular topology is strong enough for the network to perform well even when the connectivity within modules is fixed and only the connections between modules are trained. Our findings suggest that gradual modular growth of RNNs could provide advantages for learning increasingly complex tasks on evolutionary timescales, and help build more scalable and compressible artificial networks.
Learning with 3D rotations, a hitchhiker's guide to SO
Apr 17, 2024



Many settings in machine learning require the selection of a rotation representation. However, choosing a suitable representation from the many available options is challenging. This paper acts as a survey and guide through rotation representations. We walk through their properties that harm or benefit deep learning with gradient-based optimization. By consolidating insights from rotation-based learning, we provide a comprehensive overview of learning functions with rotation representations. We provide guidance on selecting representations based on whether rotations are in the model's input or output and whether the data primarily comprises small angles.
Network bottlenecks and task structure control the evolution of interpretable learning rules in a foraging agent
Mar 20, 2024



Developing reliable mechanisms for continuous local learning is a central challenge faced by biological and artificial systems. Yet, how the environmental factors and structural constraints on the learning network influence the optimal plasticity mechanisms remains obscure even for simple settings. To elucidate these dependencies, we study meta-learning via evolutionary optimization of simple reward-modulated plasticity rules in embodied agents solving a foraging task. We show that unconstrained meta-learning leads to the emergence of diverse plasticity rules. However, regularization and bottlenecks to the model help reduce this variability, resulting in interpretable rules. Our findings indicate that the meta-learning of plasticity rules is very sensitive to various parameters, with this sensitivity possibly reflected in the learning rules found in biological networks. When included in models, these dependencies can be used to discover potential objective functions and details of biological learning via comparisons with experimental observations.
Emergent mechanisms for long timescales depend on training curriculum and affect performance in memory tasks
Sep 22, 2023



Recurrent neural networks (RNNs) in the brain and in silico excel at solving tasks with intricate temporal dependencies. Long timescales required for solving such tasks can arise from properties of individual neurons (single-neuron timescale, $\tau$, e.g., membrane time constant in biological neurons) or recurrent interactions among them (network-mediated timescale). However, the contribution of each mechanism for optimally solving memory-dependent tasks remains poorly understood. Here, we train RNNs to solve $N$-parity and $N$-delayed match-to-sample tasks with increasing memory requirements controlled by $N$ by simultaneously optimizing recurrent weights and $\tau$s. We find that for both tasks RNNs develop longer timescales with increasing $N$, but depending on the learning objective, they use different mechanisms. Two distinct curricula define learning objectives: sequential learning of a single-$N$ (single-head) or simultaneous learning of multiple $N$s (multi-head). Single-head networks increase their $\tau$ with $N$ and are able to solve tasks for large $N$, but they suffer from catastrophic forgetting. However, multi-head networks, which are explicitly required to hold multiple concurrent memories, keep $\tau$ constant and develop longer timescales through recurrent connectivity. Moreover, we show that the multi-head curriculum increases training speed and network stability to ablations and perturbations, and allows RNNs to generalize better to tasks beyond their training regime. This curriculum also significantly improves training GRUs and LSTMs for large-$N$ tasks. Our results suggest that adapting timescales to task requirements via recurrent interactions allows learning more complex objectives and improves the RNN's performance.
The ELM Neuron: an Efficient and Expressive Cortical Neuron Model Can Solve Long-Horizon Tasks
Jun 14, 2023Traditional large-scale neuroscience models and machine learning utilize simplified models of individual neurons, relying on collective activity and properly adjusted connections to perform complex computations. However, each biological cortical neuron is inherently a sophisticated computational device, as corroborated in a recent study where it took a deep artificial neural network with millions of parameters to replicate the input-output relationship of a detailed biophysical model of a cortical pyramidal neuron. We question the necessity for these many parameters and introduce the Expressive Leaky Memory (ELM) neuron, a biologically inspired, computationally expressive, yet efficient model of a cortical neuron. Remarkably, our ELM neuron requires only 8K trainable parameters to match the aforementioned input-output relationship accurately. We find that an accurate model necessitates multiple memory-like hidden states and intricate nonlinear synaptic integration. To assess the computational ramifications of this design, we evaluate the ELM neuron on various tasks with demanding temporal structures, including a sequential version of the CIFAR-10 classification task, the challenging Pathfinder-X task, and a new dataset based on the Spiking Heidelberg Digits dataset. Our ELM neuron outperforms most transformer-based models on the Pathfinder-X task with 77% accuracy, demonstrates competitive performance on Sequential CIFAR-10, and superior performance compared to classic LSTM models on the variant of the Spiking Heidelberg Digits dataset. These findings indicate a potential for biologically motivated, computationally efficient neuronal models to enhance performance in challenging machine learning tasks.
Locally adaptive cellular automata for goal-oriented self-organization
Jun 12, 2023The essential ingredient for studying the phenomena of emergence is the ability to generate and manipulate emergent systems that span large scales. Cellular automata are the model class particularly known for their effective scalability but are also typically constrained by fixed local rules. In this paper, we propose a new model class of adaptive cellular automata that allows for the generation of scalable and expressive models. We show how to implement computation-effective adaptation by coupling the update rule of the cellular automaton with itself and the system state in a localized way. To demonstrate the applications of this approach, we implement two different emergent models: a self-organizing Ising model and two types of plastic neural networks, a rate and spiking model. With the Ising model, we show how coupling local/global temperatures to local/global measurements can tune the model to stay in the vicinity of the critical temperature. With the neural models, we reproduce a classical balanced state in large recurrent neuronal networks with excitatory and inhibitory neurons and various plasticity mechanisms. Our study opens multiple directions for studying collective behavior and emergence.
When to be critical? Performance and evolvability in different regimes of neural Ising agents
Apr 13, 2023It has long been hypothesized that operating close to the critical state is beneficial for natural, artificial and their evolutionary systems. We put this hypothesis to test in a system of evolving foraging agents controlled by neural networks that can adapt agents' dynamical regime throughout evolution. Surprisingly, we find that all populations that discover solutions, evolve to be subcritical. By a resilience analysis, we find that there are still benefits of starting the evolution in the critical regime. Namely, initially critical agents maintain their fitness level under environmental changes (for example, in the lifespan) and degrade gracefully when their genome is perturbed. At the same time, initially subcritical agents, even when evolved to the same fitness, are often inadequate to withstand the changes in the lifespan and degrade catastrophically with genetic perturbations. Furthermore, we find the optimal distance to criticality depends on the task complexity. To test it we introduce a hard and simple task: for the hard task, agents evolve closer to criticality whereas more subcritical solutions are found for the simple task. We verify that our results are independent of the selected evolutionary mechanisms by testing them on two principally different approaches: a genetic algorithm and an evolutionary strategy. In summary, our study suggests that although optimal behaviour in the simple task is obtained in a subcritical regime, initializing near criticality is important to be efficient at finding optimal solutions for new tasks of unknown complexity.
* arXiv admin note: substantial text overlap with arXiv:2103.12184
Assessing aesthetics of generated abstract images using correlation structure
May 18, 2021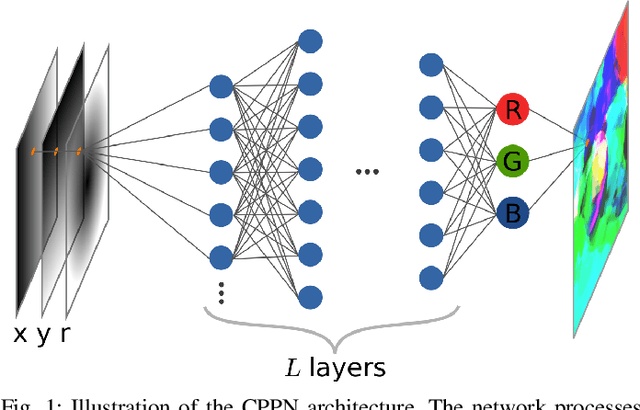

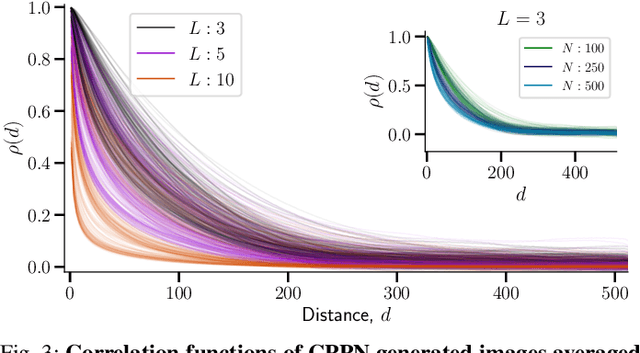
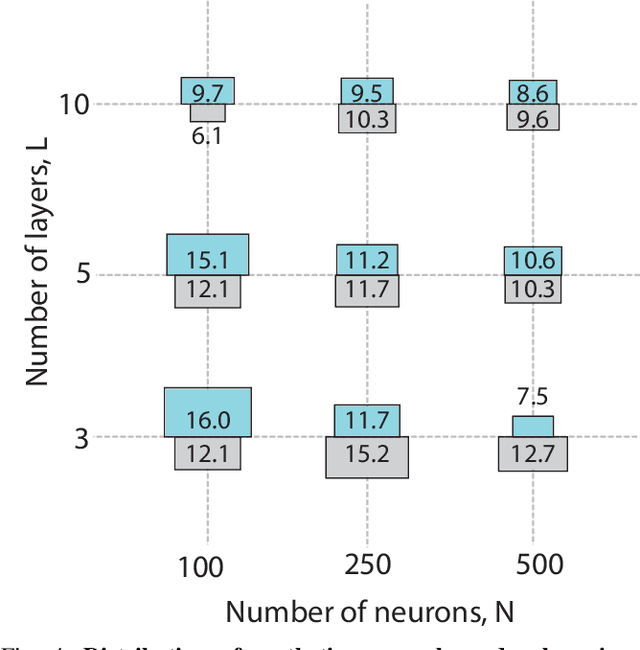
Can we generate abstract aesthetic images without bias from natural or human selected image corpi? Are aesthetic images singled out in their correlation functions? In this paper we give answers to these and more questions. We generate images using compositional pattern-producing networks with random weights and varying architecture. We demonstrate that even with the randomly selected weights the correlation functions remain largely determined by the network architecture. In a controlled experiment, human subjects picked aesthetic images out of a large dataset of all generated images. Statistical analysis reveals that the correlation function is indeed different for aesthetic images.
The dynamical regime and its importance for evolvability, task performance and generalization
Mar 22, 2021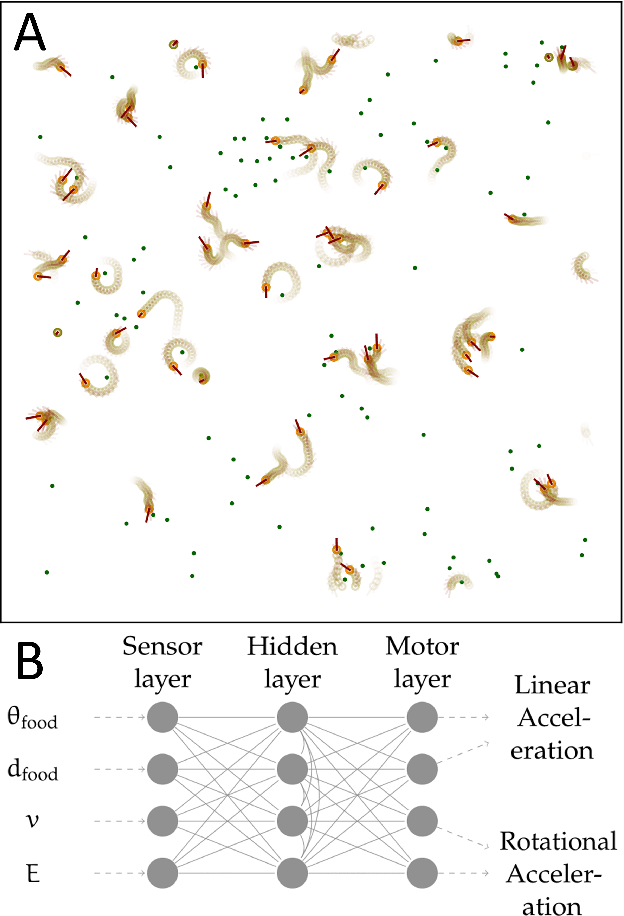
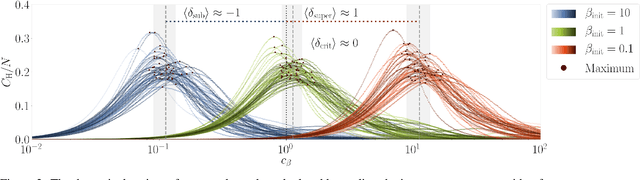
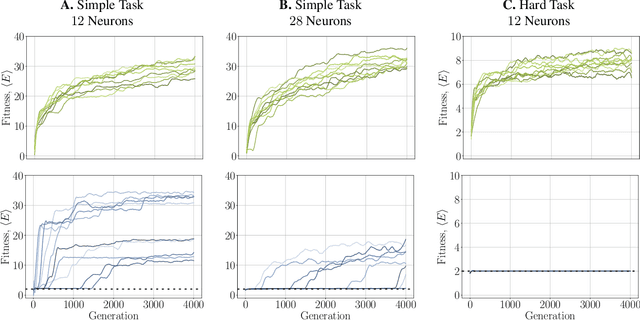
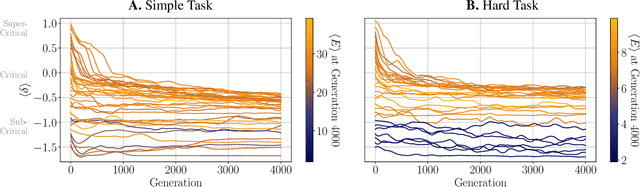
It has long been hypothesized that operating close to the critical state is beneficial for natural and artificial systems. We test this hypothesis by evolving foraging agents controlled by neural networks that can change the system's dynamical regime throughout evolution. Surprisingly, we find that all populations, regardless of their initial regime, evolve to be subcritical in simple tasks and even strongly subcritical populations can reach comparable performance. We hypothesize that the moderately subcritical regime combines the benefits of generalizability and adaptability brought by closeness to criticality with the stability of the dynamics characteristic for subcritical systems. By a resilience analysis, we find that initially critical agents maintain their fitness level even under environmental changes and degrade slowly with increasing perturbation strength. On the other hand, subcritical agents originally evolved to the same fitness, were often rendered utterly inadequate and degraded faster. We conclude that although the subcritical regime is preferable for a simple task, the optimal deviation from criticality depends on the task difficulty: for harder tasks, agents evolve closer to criticality. Furthermore, subcritical populations cannot find the path to decrease their distance to criticality. In summary, our study suggests that initializing models near criticality is important to find an optimal and flexible solution.