 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAlien Science: Sampling Coherent but Cognitively Unavailable Research Directions from Idea Atoms
Mar 01, 2026Large language models are adept at synthesizing and recombining familiar material, yet they often fail at a specific kind of creativity that matters most in research: producing ideas that are both coherent and non-obvious to the current community. We formalize this gap through cognitive availability, the likelihood that a research direction would be naturally proposed by a typical researcher given what they have worked on. We introduce a pipeline that (i) decomposes papers into granular conceptual units, (ii) clusters recurring units into a shared vocabulary of idea atoms, and (iii) learns two complementary models: a coherence model that scores whether a set of atoms constitutes a viable direction, and an availability model that scores how likely that direction is to be generated by researchers drawn from the community. We then sample "alien" directions that score high on coherence but low on availability. On a corpus of $\sim$7,500 recent LLM papers from NeurIPS, ICLR and ICML, we validate that (a) conceptual units preserve paper content under reconstruction, (b) idea atoms generalize across papers rather than memorizing paper-specific phrasing, and (c) the Alien sampler produces research directions that are more diverse than LLM baselines while maintaining coherence.
Alien Recombination: Exploring Concept Blends Beyond Human Cognitive Availability in Visual Art
Nov 18, 2024
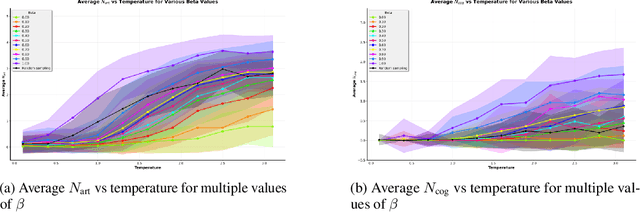
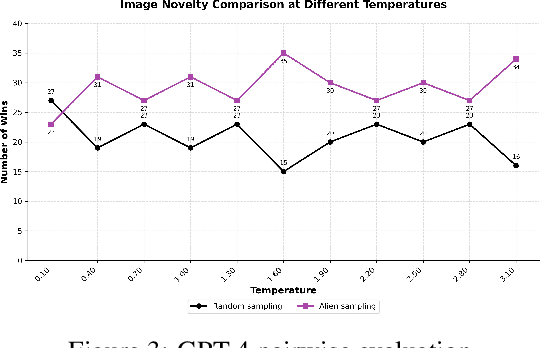
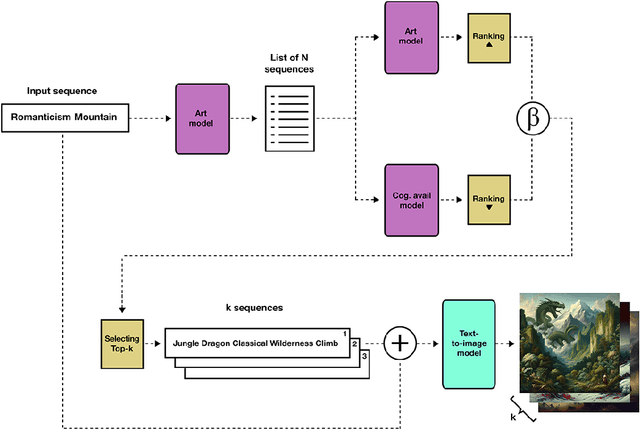
While AI models have demonstrated remarkable capabilities in constrained domains like game strategy, their potential for genuine creativity in open-ended domains like art remains debated. We explore this question by examining how AI can transcend human cognitive limitations in visual art creation. Our research hypothesizes that visual art contains a vast unexplored space of conceptual combinations, constrained not by inherent incompatibility, but by cognitive limitations imposed by artists' cultural, temporal, geographical and social contexts. To test this hypothesis, we present the Alien Recombination method, a novel approach utilizing fine-tuned large language models to identify and generate concept combinations that lie beyond human cognitive availability. The system models and deliberately counteracts human availability bias, the tendency to rely on immediately accessible examples, to discover novel artistic combinations. This system not only produces combinations that have never been attempted before within our dataset but also identifies and generates combinations that are cognitively unavailable to all artists in the domain. Furthermore, we translate these combinations into visual representations, enabling the exploration of subjective perceptions of novelty. Our findings suggest that cognitive unavailability is a promising metric for optimizing artistic novelty, outperforming merely temperature scaling without additional evaluation criteria. This approach uses generative models to connect previously unconnected ideas, providing new insight into the potential of framing AI-driven creativity as a combinatorial problem.
Language Models Can Reduce Asymmetry in Information Markets
Mar 21, 2024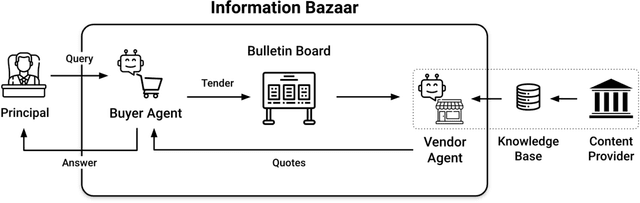

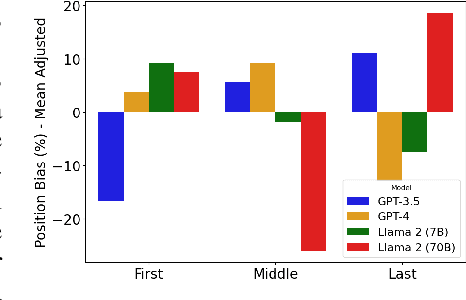
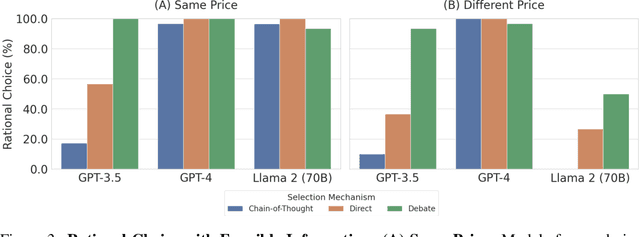
This work addresses the buyer's inspection paradox for information markets. The paradox is that buyers need to access information to determine its value, while sellers need to limit access to prevent theft. To study this, we introduce an open-source simulated digital marketplace where intelligent agents, powered by language models, buy and sell information on behalf of external participants. The central mechanism enabling this marketplace is the agents' dual capabilities: they not only have the capacity to assess the quality of privileged information but also come equipped with the ability to forget. This ability to induce amnesia allows vendors to grant temporary access to proprietary information, significantly reducing the risk of unauthorized retention while enabling agents to accurately gauge the information's relevance to specific queries or tasks. To perform well, agents must make rational decisions, strategically explore the marketplace through generated sub-queries, and synthesize answers from purchased information. Concretely, our experiments (a) uncover biases in language models leading to irrational behavior and evaluate techniques to mitigate these biases, (b) investigate how price affects demand in the context of informational goods, and (c) show that inspection and higher budgets both lead to higher quality outcomes.
The ELM Neuron: an Efficient and Expressive Cortical Neuron Model Can Solve Long-Horizon Tasks
Jun 14, 2023Traditional large-scale neuroscience models and machine learning utilize simplified models of individual neurons, relying on collective activity and properly adjusted connections to perform complex computations. However, each biological cortical neuron is inherently a sophisticated computational device, as corroborated in a recent study where it took a deep artificial neural network with millions of parameters to replicate the input-output relationship of a detailed biophysical model of a cortical pyramidal neuron. We question the necessity for these many parameters and introduce the Expressive Leaky Memory (ELM) neuron, a biologically inspired, computationally expressive, yet efficient model of a cortical neuron. Remarkably, our ELM neuron requires only 8K trainable parameters to match the aforementioned input-output relationship accurately. We find that an accurate model necessitates multiple memory-like hidden states and intricate nonlinear synaptic integration. To assess the computational ramifications of this design, we evaluate the ELM neuron on various tasks with demanding temporal structures, including a sequential version of the CIFAR-10 classification task, the challenging Pathfinder-X task, and a new dataset based on the Spiking Heidelberg Digits dataset. Our ELM neuron outperforms most transformer-based models on the Pathfinder-X task with 77% accuracy, demonstrates competitive performance on Sequential CIFAR-10, and superior performance compared to classic LSTM models on the variant of the Spiking Heidelberg Digits dataset. These findings indicate a potential for biologically motivated, computationally efficient neuronal models to enhance performance in challenging machine learning tasks.
A General Purpose Neural Architecture for Geospatial Systems
Nov 04, 2022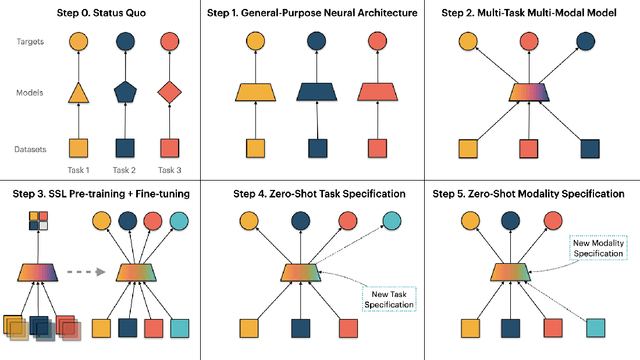
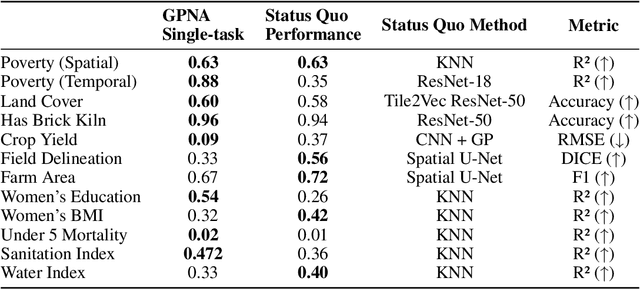
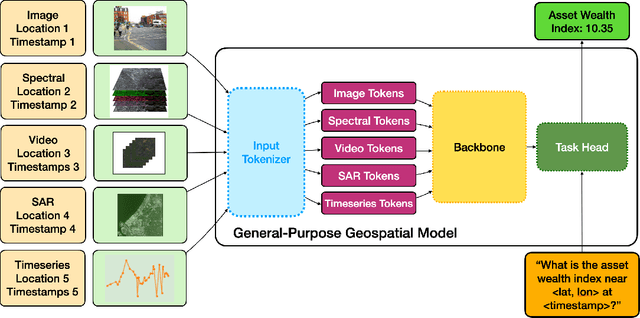
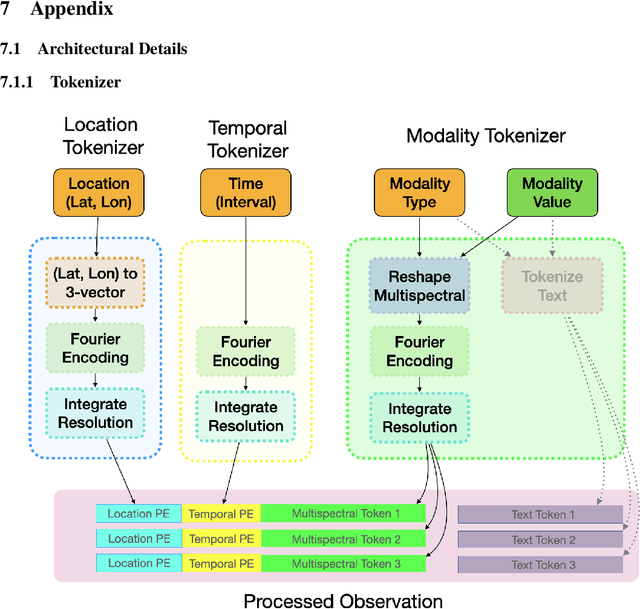
Geospatial Information Systems are used by researchers and Humanitarian Assistance and Disaster Response (HADR) practitioners to support a wide variety of important applications. However, collaboration between these actors is difficult due to the heterogeneous nature of geospatial data modalities (e.g., multi-spectral images of various resolutions, timeseries, weather data) and diversity of tasks (e.g., regression of human activity indicators or detecting forest fires). In this work, we present a roadmap towards the construction of a general-purpose neural architecture (GPNA) with a geospatial inductive bias, pre-trained on large amounts of unlabelled earth observation data in a self-supervised manner. We envision how such a model may facilitate cooperation between members of the community. We show preliminary results on the first step of the roadmap, where we instantiate an architecture that can process a wide variety of geospatial data modalities and demonstrate that it can achieve competitive performance with domain-specific architectures on tasks relating to the U.N.'s Sustainable Development Goals.
Neural Attentive Circuits
Oct 19, 2022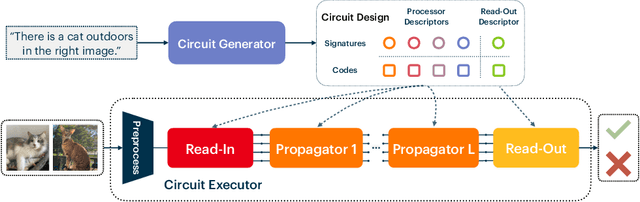
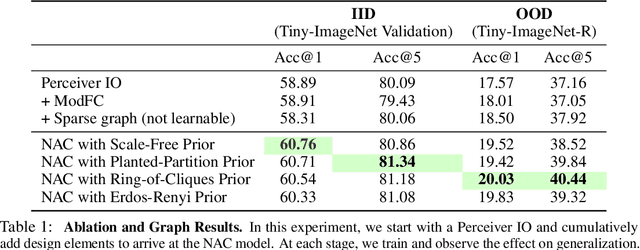
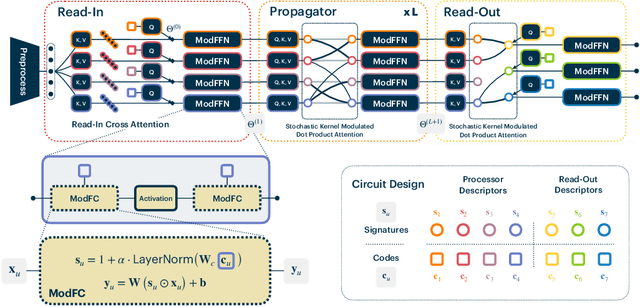

Recent work has seen the development of general purpose neural architectures that can be trained to perform tasks across diverse data modalities. General purpose models typically make few assumptions about the underlying data-structure and are known to perform well in the large-data regime. At the same time, there has been growing interest in modular neural architectures that represent the data using sparsely interacting modules. These models can be more robust out-of-distribution, computationally efficient, and capable of sample-efficient adaptation to new data. However, they tend to make domain-specific assumptions about the data, and present challenges in how module behavior (i.e., parameterization) and connectivity (i.e., their layout) can be jointly learned. In this work, we introduce a general purpose, yet modular neural architecture called Neural Attentive Circuits (NACs) that jointly learns the parameterization and a sparse connectivity of neural modules without using domain knowledge. NACs are best understood as the combination of two systems that are jointly trained end-to-end: one that determines the module configuration and the other that executes it on an input. We demonstrate qualitatively that NACs learn diverse and meaningful module configurations on the NLVR2 dataset without additional supervision. Quantitatively, we show that by incorporating modularity in this way, NACs improve upon a strong non-modular baseline in terms of low-shot adaptation on CIFAR and CUBs dataset by about 10%, and OOD robustness on Tiny ImageNet-R by about 2.5%. Further, we find that NACs can achieve an 8x speedup at inference time while losing less than 3% performance. Finally, we find NACs to yield competitive results on diverse data modalities spanning point-cloud classification, symbolic processing and text-classification from ASCII bytes, thereby confirming its general purpose nature.
Discrete Key-Value Bottleneck
Jul 22, 2022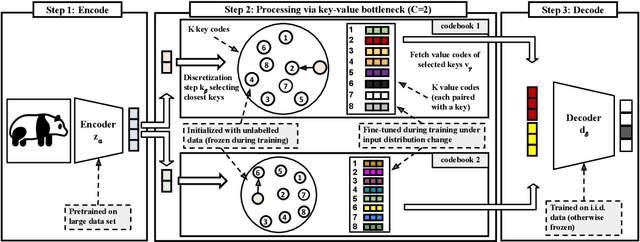
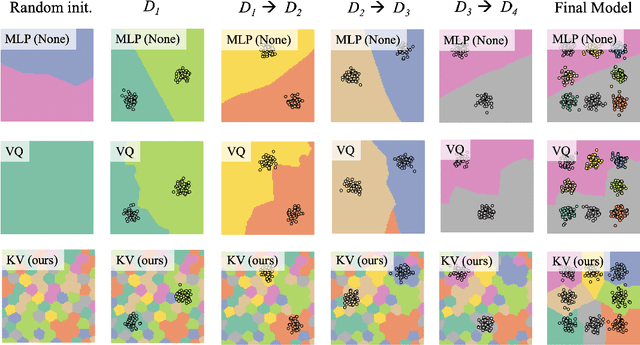

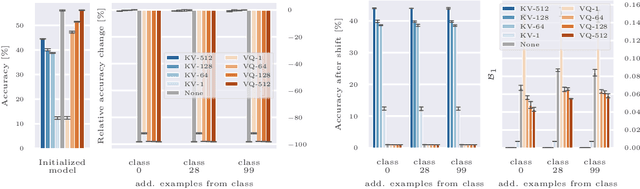
Deep neural networks perform well on prediction and classification tasks in the canonical setting where data streams are i.i.d., labeled data is abundant, and class labels are balanced. Challenges emerge with distribution shifts, including non-stationary or imbalanced data streams. One powerful approach that has addressed this challenge involves self-supervised pretraining of large encoders on volumes of unlabeled data, followed by task-specific tuning. Given a new task, updating the weights of these encoders is challenging as a large number of weights needs to be fine-tuned, and as a result, they forget information about the previous tasks. In the present work, we propose a model architecture to address this issue, building upon a discrete bottleneck containing pairs of separate and learnable (key, value) codes. In this setup, we follow the encode; process the representation via a discrete bottleneck; and decode paradigm, where the input is fed to the pretrained encoder, the output of the encoder is used to select the nearest keys, and the corresponding values are fed to the decoder to solve the current task. The model can only fetch and re-use a limited number of these (key, value) pairs during inference, enabling localized and context-dependent model updates. We theoretically investigate the ability of the proposed model to minimize the effect of the distribution shifts and show that such a discrete bottleneck with (key, value) pairs reduces the complexity of the hypothesis class. We empirically verified the proposed methods' benefits under challenging distribution shift scenarios across various benchmark datasets and show that the proposed model reduces the common vulnerability to non-i.i.d. and non-stationary training distributions compared to various other baselines.
Dynamic Inference with Neural Interpreters
Oct 12, 2021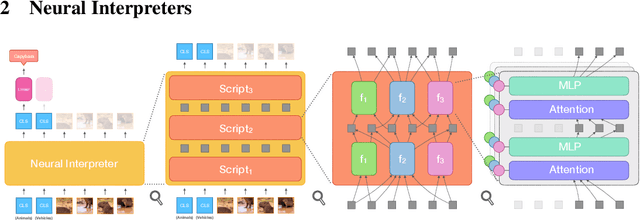
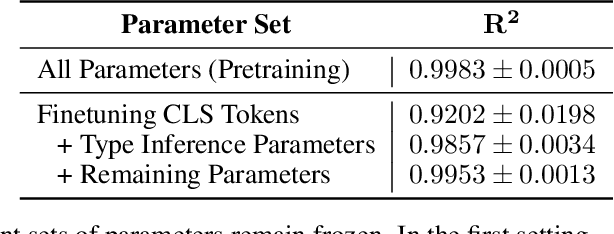
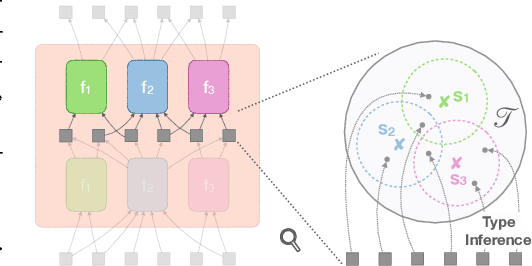
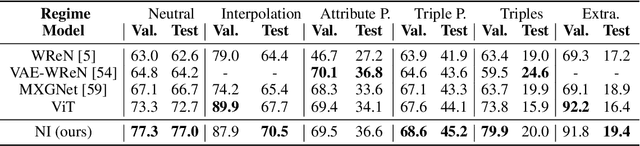
Modern neural network architectures can leverage large amounts of data to generalize well within the training distribution. However, they are less capable of systematic generalization to data drawn from unseen but related distributions, a feat that is hypothesized to require compositional reasoning and reuse of knowledge. In this work, we present Neural Interpreters, an architecture that factorizes inference in a self-attention network as a system of modules, which we call \emph{functions}. Inputs to the model are routed through a sequence of functions in a way that is end-to-end learned. The proposed architecture can flexibly compose computation along width and depth, and lends itself well to capacity extension after training. To demonstrate the versatility of Neural Interpreters, we evaluate it in two distinct settings: image classification and visual abstract reasoning on Raven Progressive Matrices. In the former, we show that Neural Interpreters perform on par with the vision transformer using fewer parameters, while being transferrable to a new task in a sample efficient manner. In the latter, we find that Neural Interpreters are competitive with respect to the state-of-the-art in terms of systematic generalization
Coordination Among Neural Modules Through a Shared Global Workspace
Mar 01, 2021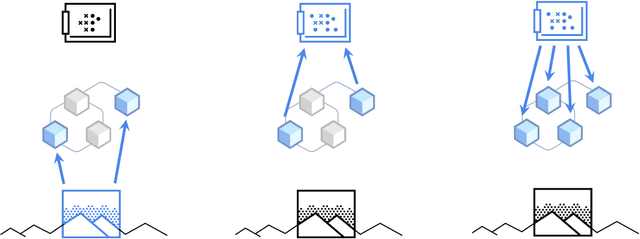
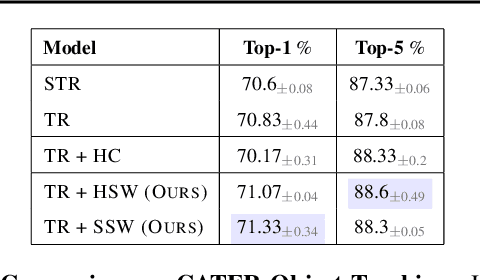
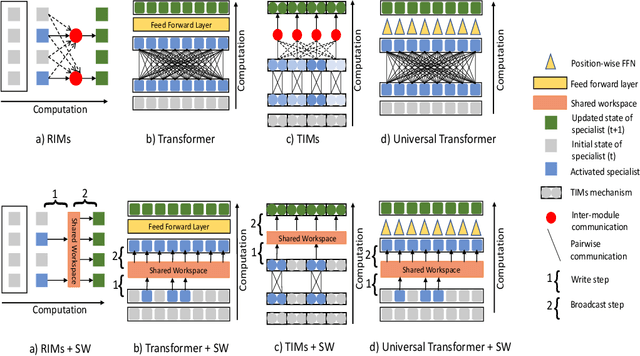
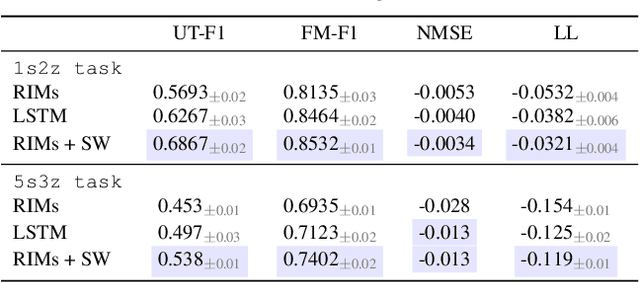
Deep learning has seen a movement away from representing examples with a monolithic hidden state towards a richly structured state. For example, Transformers segment by position, and object-centric architectures decompose images into entities. In all these architectures, interactions between different elements are modeled via pairwise interactions: Transformers make use of self-attention to incorporate information from other positions; object-centric architectures make use of graph neural networks to model interactions among entities. However, pairwise interactions may not achieve global coordination or a coherent, integrated representation that can be used for downstream tasks. In cognitive science, a global workspace architecture has been proposed in which functionally specialized components share information through a common, bandwidth-limited communication channel. We explore the use of such a communication channel in the context of deep learning for modeling the structure of complex environments. The proposed method includes a shared workspace through which communication among different specialist modules takes place but due to limits on the communication bandwidth, specialist modules must compete for access. We show that capacity limitations have a rational basis in that (1) they encourage specialization and compositionality and (2) they facilitate the synchronization of otherwise independent specialists.
COVI-AgentSim: an Agent-based Model for Evaluating Methods of Digital Contact Tracing
Oct 30, 2020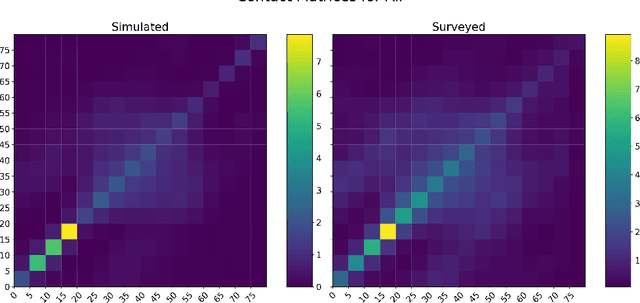
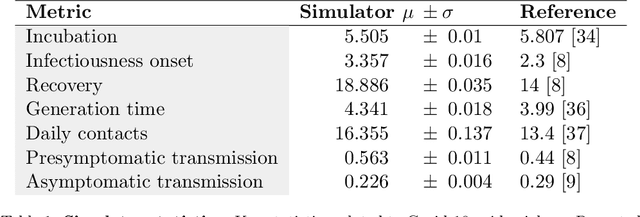
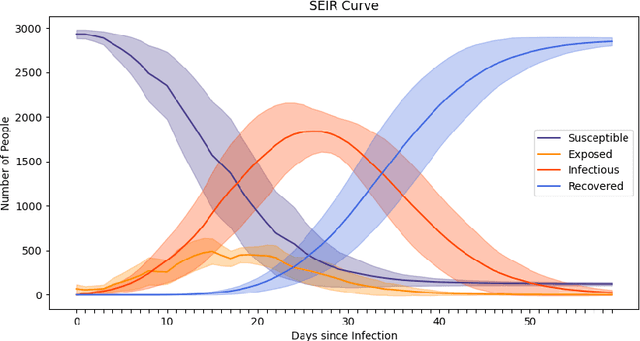
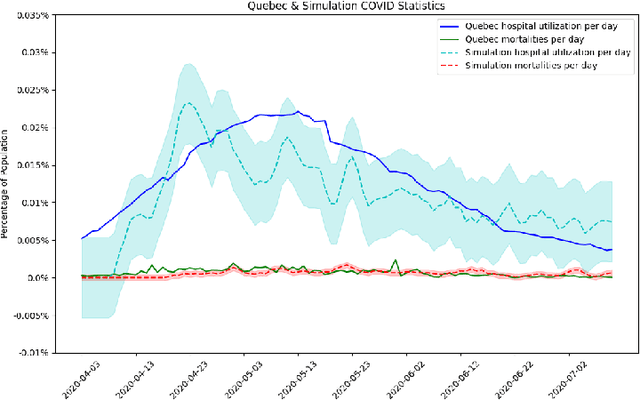
The rapid global spread of COVID-19 has led to an unprecedented demand for effective methods to mitigate the spread of the disease, and various digital contact tracing (DCT) methods have emerged as a component of the solution. In order to make informed public health choices, there is a need for tools which allow evaluation and comparison of DCT methods. We introduce an agent-based compartmental simulator we call COVI-AgentSim, integrating detailed consideration of virology, disease progression, social contact networks, and mobility patterns, based on parameters derived from empirical research. We verify by comparing to real data that COVI-AgentSim is able to reproduce realistic COVID-19 spread dynamics, and perform a sensitivity analysis to verify that the relative performance of contact tracing methods are consistent across a range of settings. We use COVI-AgentSim to perform cost-benefit analyses comparing no DCT to: 1) standard binary contact tracing (BCT) that assigns binary recommendations based on binary test results; and 2) a rule-based method for feature-based contact tracing (FCT) that assigns a graded level of recommendation based on diverse individual features. We find all DCT methods consistently reduce the spread of the disease, and that the advantage of FCT over BCT is maintained over a wide range of adoption rates. Feature-based methods of contact tracing avert more disability-adjusted life years (DALYs) per socioeconomic cost (measured by productive hours lost). Our results suggest any DCT method can help save lives, support re-opening of economies, and prevent second-wave outbreaks, and that FCT methods are a promising direction for enriching BCT using self-reported symptoms, yielding earlier warning signals and a significantly reduced spread of the virus per socioeconomic cost.