 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoordination Among Neural Modules Through a Shared Global Workspace
Mar 01, 2021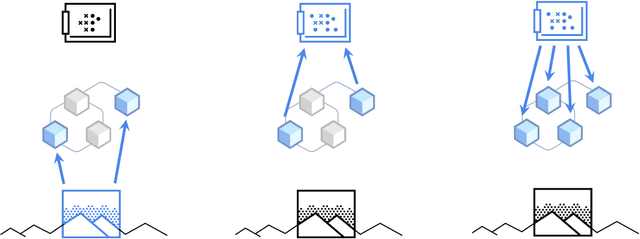
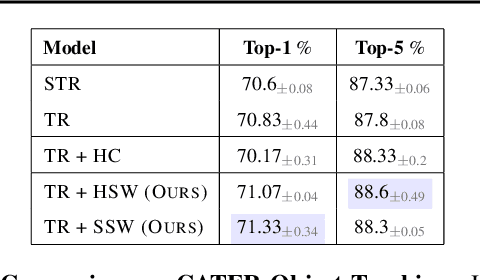
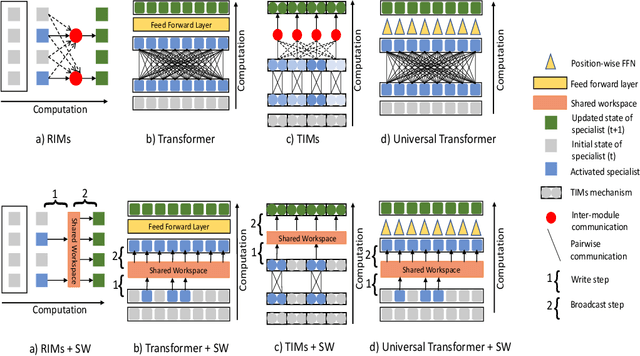
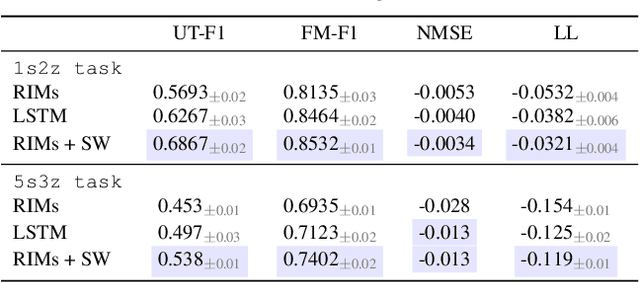
Deep learning has seen a movement away from representing examples with a monolithic hidden state towards a richly structured state. For example, Transformers segment by position, and object-centric architectures decompose images into entities. In all these architectures, interactions between different elements are modeled via pairwise interactions: Transformers make use of self-attention to incorporate information from other positions; object-centric architectures make use of graph neural networks to model interactions among entities. However, pairwise interactions may not achieve global coordination or a coherent, integrated representation that can be used for downstream tasks. In cognitive science, a global workspace architecture has been proposed in which functionally specialized components share information through a common, bandwidth-limited communication channel. We explore the use of such a communication channel in the context of deep learning for modeling the structure of complex environments. The proposed method includes a shared workspace through which communication among different specialist modules takes place but due to limits on the communication bandwidth, specialist modules must compete for access. We show that capacity limitations have a rational basis in that (1) they encourage specialization and compositionality and (2) they facilitate the synchronization of otherwise independent specialists.
Reinforcement Learning with Random Delays
Oct 08, 2020
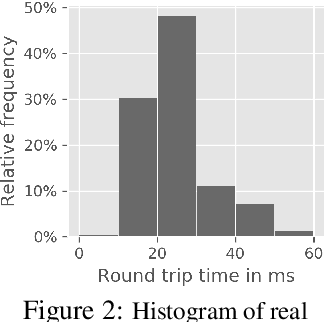
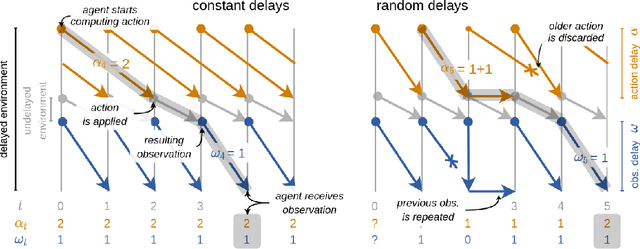
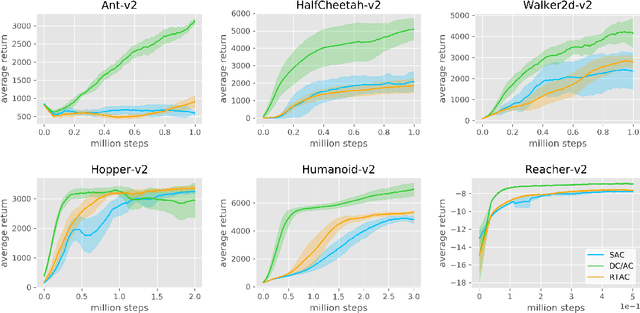
Action and observation delays commonly occur in many Reinforcement Learning applications, such as remote control scenarios. We study the anatomy of randomly delayed environments, and show that partially resampling trajectory fragments in hindsight allows for off-policy multi-step value estimation. We apply this principle to derive Delay-Correcting Actor-Critic (DCAC), an algorithm based on Soft Actor-Critic with significantly better performance in environments with delays. This is shown theoretically and also demonstrated practically on a delay-augmented version of the MuJoCo continuous control benchmark.
DDD20 End-to-End Event Camera Driving Dataset: Fusing Frames and Events with Deep Learning for Improved Steering Prediction
May 18, 2020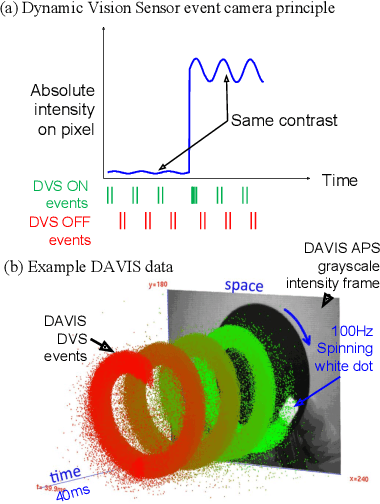



Neuromorphic event cameras are useful for dynamic vision problems under difficult lighting conditions. To enable studies of using event cameras in automobile driving applications, this paper reports a new end-to-end driving dataset called DDD20. The dataset was captured with a DAVIS camera that concurrently streams both dynamic vision sensor (DVS) brightness change events and active pixel sensor (APS) intensity frames. DDD20 is the longest event camera end-to-end driving dataset to date with 51h of DAVIS event+frame camera and vehicle human control data collected from 4000km of highway and urban driving under a variety of lighting conditions. Using DDD20, we report the first study of fusing brightness change events and intensity frame data using a deep learning approach to predict the instantaneous human steering wheel angle. Over all day and night conditions, the explained variance for human steering prediction from a Resnet-32 is significantly better from the fused DVS+APS frames (0.88) than using either DVS (0.67) or APS (0.77) data alone.
Out-of-Distribution Generalization via Risk Extrapolation (REx)
Mar 13, 2020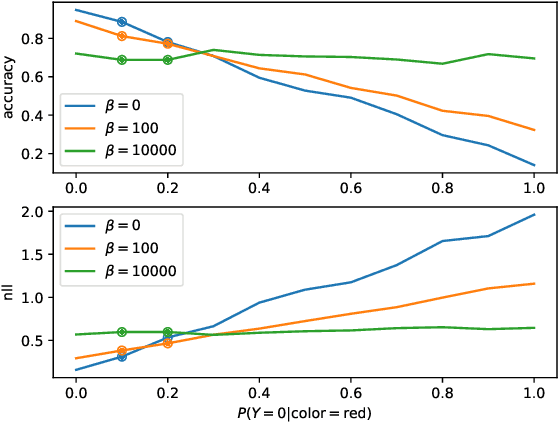
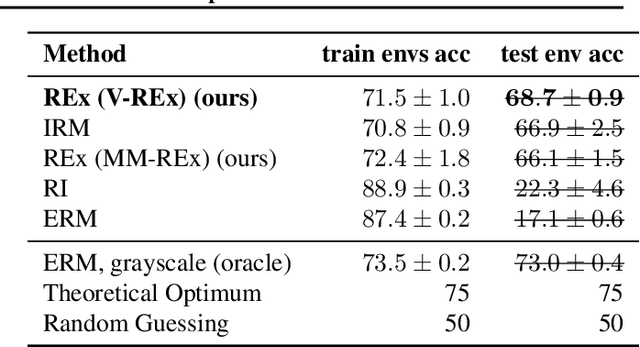
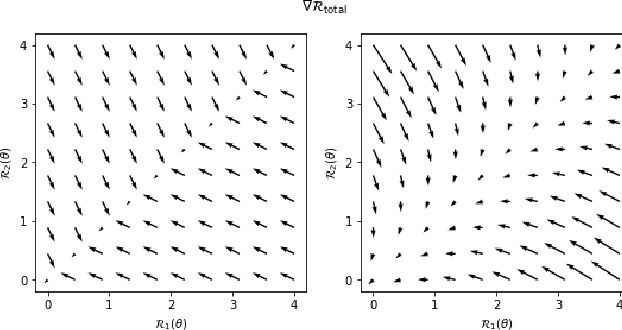
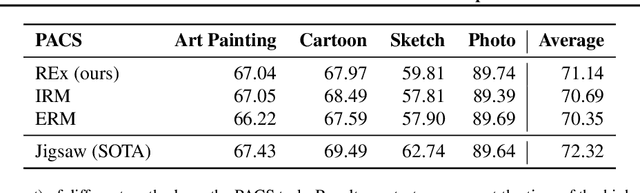
Generalizing outside of the training distribution is an open challenge for current machine learning systems. A weak form of out-of-distribution (OoD) generalization is the ability to successfully interpolate between multiple observed distributions. One way to achieve this is through robust optimization, which seeks to minimize the worst-case risk over convex combinations of the training distributions. However, a much stronger form of OoD generalization is the ability of models to extrapolate beyond the distributions observed during training. In pursuit of strong OoD generalization, we introduce the principle of Risk Extrapolation (REx). REx can be viewed as encouraging robustness over affine combinations of training risks, by encouraging strict equality between training risks. We show conceptually how this principle enables extrapolation, and demonstrate the effectiveness and scalability of instantiations of REx on various OoD generalization tasks. Our code can be found at https://github.com/capybaralet/REx_code_release.
Reinforcement Learning with Competitive Ensembles of Information-Constrained Primitives
Jun 25, 2019



Reinforcement learning agents that operate in diverse and complex environments can benefit from the structured decomposition of their behavior. Often, this is addressed in the context of hierarchical reinforcement learning, where the aim is to decompose a policy into lower-level primitives or options, and a higher-level meta-policy that triggers the appropriate behaviors for a given situation. However, the meta-policy must still produce appropriate decisions in all states. In this work, we propose a policy design that decomposes into primitives, similarly to hierarchical reinforcement learning, but without a high-level meta-policy. Instead, each primitive can decide for themselves whether they wish to act in the current state. We use an information-theoretic mechanism for enabling this decentralized decision: each primitive chooses how much information it needs about the current state to make a decision and the primitive that requests the most information about the current state acts in the world. The primitives are regularized to use as little information as possible, which leads to natural competition and specialization. We experimentally demonstrate that this policy architecture improves over both flat and hierarchical policies in terms of generalization.
State-Reification Networks: Improving Generalization by Modeling the Distribution of Hidden Representations
May 26, 2019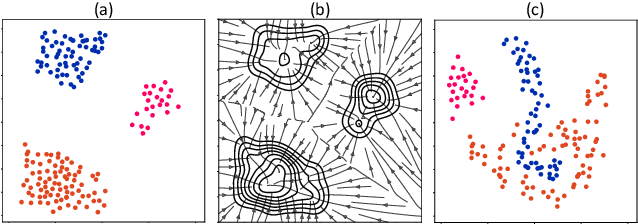
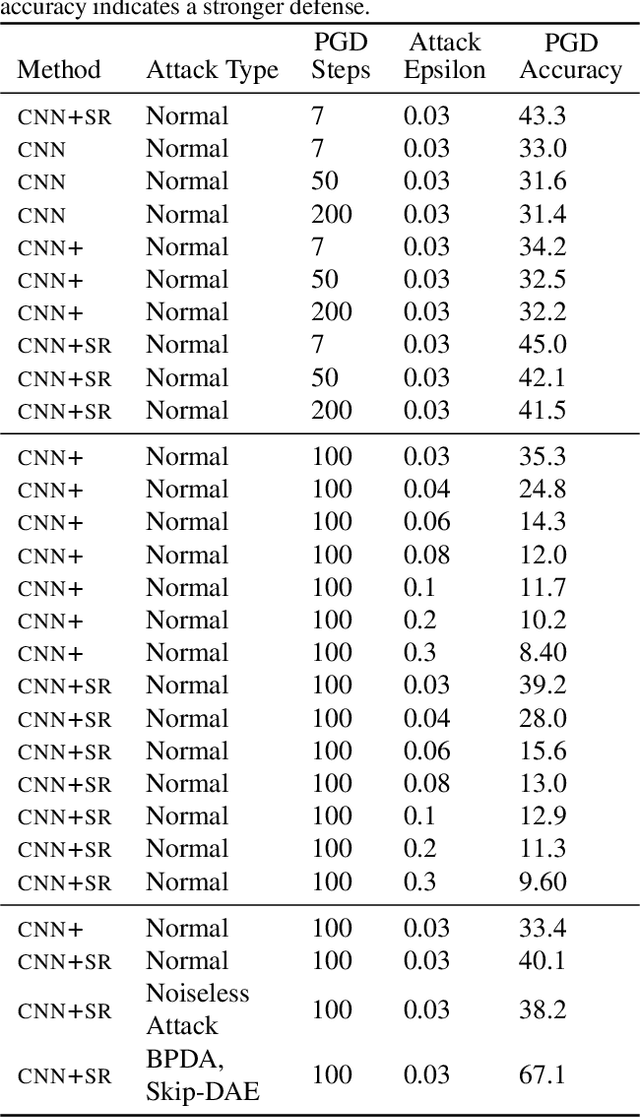
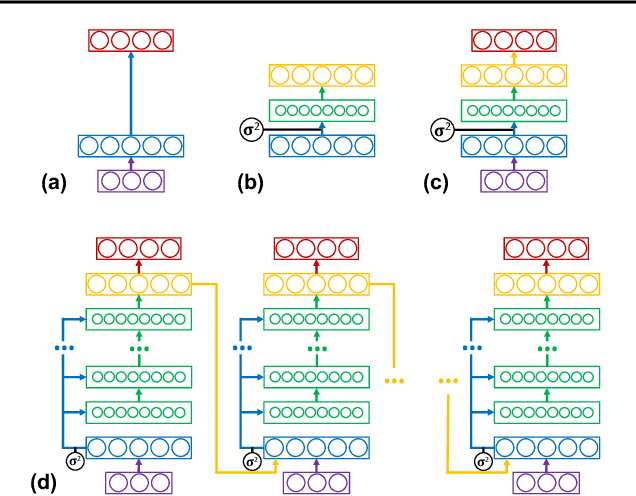
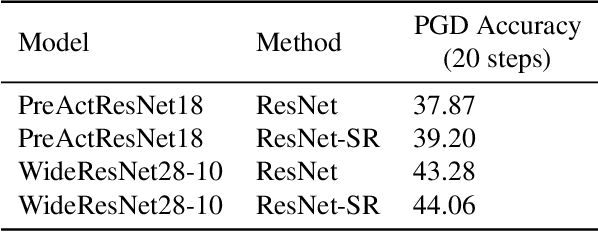
Machine learning promises methods that generalize well from finite labeled data. However, the brittleness of existing neural net approaches is revealed by notable failures, such as the existence of adversarial examples that are misclassified despite being nearly identical to a training example, or the inability of recurrent sequence-processing nets to stay on track without teacher forcing. We introduce a method, which we refer to as \emph{state reification}, that involves modeling the distribution of hidden states over the training data and then projecting hidden states observed during testing toward this distribution. Our intuition is that if the network can remain in a familiar manifold of hidden space, subsequent layers of the net should be well trained to respond appropriately. We show that this state-reification method helps neural nets to generalize better, especially when labeled data are sparse, and also helps overcome the challenge of achieving robust generalization with adversarial training.
The Journey is the Reward: Unsupervised Learning of Influential Trajectories
May 22, 2019
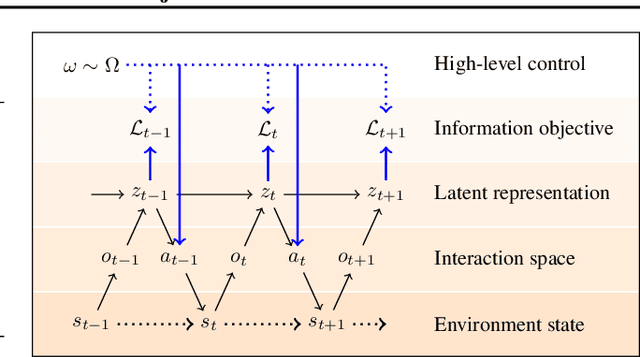
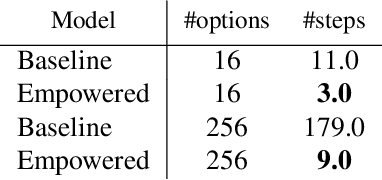
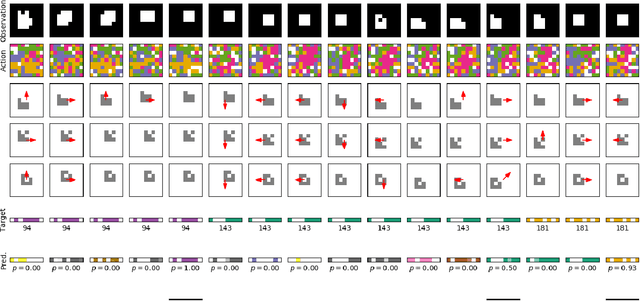
Unsupervised exploration and representation learning become increasingly important when learning in diverse and sparse environments. The information-theoretic principle of empowerment formalizes an unsupervised exploration objective through an agent trying to maximize its influence on the future states of its environment. Previous approaches carry certain limitations in that they either do not employ closed-loop feedback or do not have an internal state. As a consequence, a privileged final state is taken as an influence measure, rather than the full trajectory. We provide a model-free method which takes into account the whole trajectory while still offering the benefits of option-based approaches. We successfully apply our approach to settings with large action spaces, where discovery of meaningful action sequences is particularly difficult.
Sparse Attentive Backtracking: Temporal CreditAssignment Through Reminding
Sep 11, 2018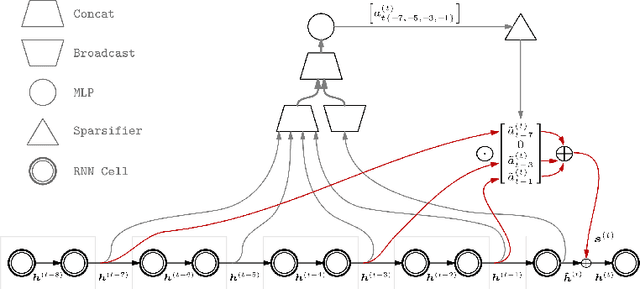

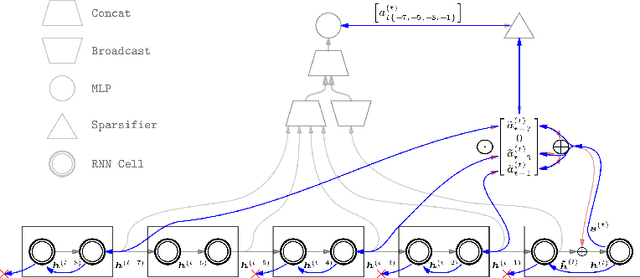
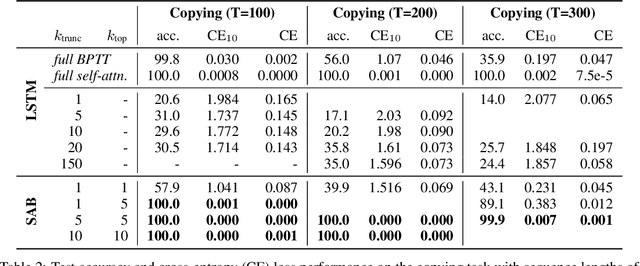
Learning long-term dependencies in extended temporal sequences requires credit assignment to events far back in the past. The most common method for training recurrent neural networks, back-propagation through time (BPTT), requires credit information to be propagated backwards through every single step of the forward computation, potentially over thousands or millions of time steps. This becomes computationally expensive or even infeasible when used with long sequences. Importantly, biological brains are unlikely to perform such detailed reverse replay over very long sequences of internal states (consider days, months, or years.) However, humans are often reminded of past memories or mental states which are associated with the current mental state. We consider the hypothesis that such memory associations between past and present could be used for credit assignment through arbitrarily long sequences, propagating the credit assigned to the current state to the associated past state. Based on this principle, we study a novel algorithm which only back-propagates through a few of these temporal skip connections, realized by a learned attention mechanism that associates current states with relevant past states. We demonstrate in experiments that our method matches or outperforms regular BPTT and truncated BPTT in tasks involving particularly long-term dependencies, but without requiring the biologically implausible backward replay through the whole history of states. Additionally, we demonstrate that the proposed method transfers to longer sequences significantly better than LSTMs trained with BPTT and LSTMs trained with full self-attention.
Generalization of Equilibrium Propagation to Vector Field Dynamics
Aug 14, 2018

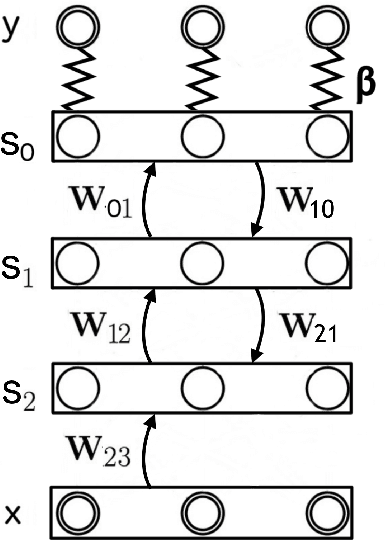

The biological plausibility of the backpropagation algorithm has long been doubted by neuroscientists. Two major reasons are that neurons would need to send two different types of signal in the forward and backward phases, and that pairs of neurons would need to communicate through symmetric bidirectional connections. We present a simple two-phase learning procedure for fixed point recurrent networks that addresses both these issues. In our model, neurons perform leaky integration and synaptic weights are updated through a local mechanism. Our learning method generalizes Equilibrium Propagation to vector field dynamics, relaxing the requirement of an energy function. As a consequence of this generalization, the algorithm does not compute the true gradient of the objective function, but rather approximates it at a precision which is proven to be directly related to the degree of symmetry of the feedforward and feedback weights. We show experimentally that our algorithm optimizes the objective function.
Low-memory convolutional neural networks through incremental depth-first processing
Apr 28, 2018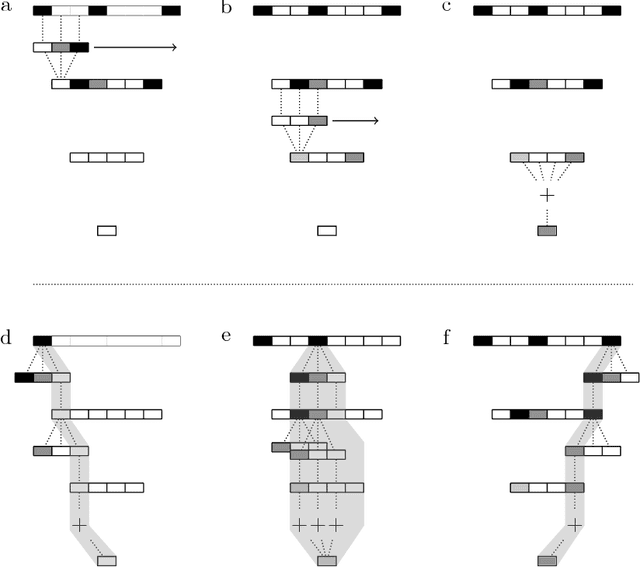
We introduce an incremental processing scheme for convolutional neural network (CNN) inference, targeted at embedded applications with limited memory budgets. Instead of processing layers one by one, individual input pixels are propagated through all parts of the network they can influence under the given structural constraints. This depth-first updating scheme comes with hard bounds on the memory footprint: the memory required is constant in the case of 1D input and proportional to the square root of the input dimension in the case of 2D input.