 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVISTA: Scale-Aware Visual Navigation via Action History Conditioning
Jun 15, 2026Vision Navigation Foundation Models (VNMs) promise end-to-end learned navigation policies capable of zero-shot deployment across diverse embodiments and environments. To maintain generality, many vision-based navigation models predict normalized actions. However, this normalization introduces a critical deployment vulnerability: applying different scaling factors to the same normalized trajectory alters its physical geometry, which degrades navigation performance and increases collision risks. We address this vulnerability by conditioning the model on normalized action histories alongside image observations, providing explicit context on the relationship between the model's predictions and the robot's actual physical displacement. Furthermore, current VNMs often struggle in visually repetitive environments that lack distinct features. To resolve this issue, we integrate a DINOv3 encoder, whose richer representations enable our model to capture both spatial and geometric dimensions between observations. VISTA generalizes robustly to out-of-distribution environments, achieving 100% goal prediction accuracy in zero-shot, real-world deployment in Outdoor, Forest and Office settings, and an average of 95% checkpoints crossed, demonstrating consistent path following in unseen environments.
To Select or not to Select, that is the Question: Distilling Robot Skill Prediction into a Small Ensemble
May 20, 2026As robot fleets become more heterogeneous, including humanoids, rovers, quadrupeds, and drones, selecting the right robot for a task becomes a core systems problem. We study robot skill prediction: mapping a natural-language task description to the physical capabilities required to execute it, such as fly, wheels, legs, surface water, under water and hands. Since labelled data that maps natural-language task descriptions to robot's physical capabilities does not exist, we construct a synthetic task-to-skill dataset using LLM-assisted generation and targeted label auditing. Trained on this data, a ~133M-parameter ensemble of two fine-tuned sentence encoders (mpnet + MiniLM) reaches 83.5% task-to-skill matching on a stratified 200 task dataset, outperforming Kimi K2 (1T MoE) at 72.0%, GPT-OSS-120B at 71.5%, and Llama-4-Scout-17B at 69.0% under the same zero-shot prompt. These results suggest that, for fixed robot skill taxonomies, small specialized models trained on synthetic data can outperform much larger general-purpose LLMs for fleet-level task routing.
Safe Aerial 3D Path Planning for Autonomous UAVs using Magnetic Potential Fields
May 11, 2026Safe autonomous Uncrewed Aerial Vehicle (UAV) navigation in urban environments requires real-time path planning that avoids obstacles. MaxConvNet is a potential-field planner that leverages properties of Maxwell's equations to generate a path to the goal without local minima. We extend the 2D MaxConvNet magnetic field planner to 3D, using a convolutional autoencoder to predict obstacle-aware potential fields from LiDAR-derived 101^3 voxel grids. Evaluation across 100 randomized closed-loop trials in two distinct Cosys-AirSim urban environments, a dense night-time cityscape and a suburban district shows a 100% path planning success rate on both maps without retraining. In offline path planning, 3DMaxConvNet produces path lengths comparable to A* on unseen maps while reducing runtime from 0.155--0.17s to 0.087--0.089s, or about 1.7--1.95 times faster than A*. Against RRT*(3k), 3DMaxConvNet achieves similar path quality while reducing planning runtime from 17.2--17.5s to about 0.09s, which is roughly 193--201 times faster than RRT*(3k).
Compact Keyframe-Optimized Multi-Agent Gaussian Splatting SLAM
Apr 01, 2026Efficient multi-agent 3D mapping is essential for robotic teams operating in unknown environments, but dense representations hinder real-time exchange over constrained communication links. In multi-agent Simultaneous Localization and Mapping (SLAM), systems typically rely on a centralized server to merge and optimize the local maps produced by individual agents. However, sharing these large map representations, particularly those generated by recent methods such as Gaussian Splatting, becomes a bottleneck in real-world scenarios with limited bandwidth. We present an improved multi-agent RGB-D Gaussian Splatting SLAM framework that reduces communication load while preserving map fidelity. First, we incorporate a compaction step into our SLAM system to remove redundant 3D Gaussians, without degrading the rendering quality. Second, our approach performs centralized loop closure computation without initial guess, operating in two modes: a pure rendered-depth mode that requires no data beyond the 3D Gaussians, and a camera-depth mode that includes lightweight depth images for improved registration accuracy and additional Gaussian pruning. Evaluation on both synthetic and real-world datasets shows up to 85-95\% reduction in transmitted data compared to state-of-the-art approaches in both modes, bringing 3D Gaussian multi-agent SLAM closer to practical deployment in real-world scenarios. Code: https://github.com/lemonci/coko-slam
Can Vision Foundation Models Navigate? Zero-Shot Real-World Evaluation and Lessons Learned
Mar 26, 2026Visual Navigation Models (VNMs) promise generalizable, robot navigation by learning from large-scale visual demonstrations. Despite growing real-world deployment, existing evaluations rely almost exclusively on success rate, whether the robot reaches its goal, which conceals trajectory quality, collision behavior, and robustness to environmental change. We present a real-world evaluation of five state-of-the-art VNMs (GNM, ViNT, NoMaD, NaviBridger, and CrossFormer) across two robot platforms and five environments spanning indoor and outdoor settings. Beyond success rate, we combine path-based metrics with vision-based goal-recognition scores and assess robustness through controlled image perturbations (motion blur, sunflare). Our analysis uncovers three systematic limitations: (a) even architecturally sophisticated diffusion and transformer-based models exhibit frequent collisions, indicating limited geometric understanding; (b) models fail to discriminate between different locations that are perceptually similar, however some semantics differences are present, causing goal prediction errors in repetitive environments; and (c) performance degrades under distribution shift. We will publicly release our evaluation codebase and dataset to facilitate reproducible benchmarking of VNMs.
3D Foundation Model-Based Loop Closing for Decentralized Collaborative SLAM
Feb 02, 2026Decentralized Collaborative Simultaneous Localization And Mapping (C-SLAM) techniques often struggle to identify map overlaps due to significant viewpoint variations among robots. Motivated by recent advancements in 3D foundation models, which can register images despite large viewpoint differences, we propose a robust loop closing approach that leverages these models to establish inter-robot measurements. In contrast to resource-intensive methods requiring full 3D reconstruction within a centralized map, our approach integrates foundation models into existing SLAM pipelines, yielding scalable and robust multi-robot mapping. Our contributions include: (1) integrating 3D foundation models to reliably estimate relative poses from monocular image pairs within decentralized C-SLAM; (2) introducing robust outlier mitigation techniques critical to the use of these relative poses; and (3) developing specialized pose graph optimization formulations that efficiently resolve scale ambiguities. We evaluate our method against state-of-the-art approaches, demonstrating improvements in localization and mapping accuracy, alongside significant gains in computational and memory efficiency. These results highlight the potential of our approach for deployment in large-scale multi-robot scenarios.
Multi-Robot Decentralized Collaborative SLAM in Planetary Analogue Environments: Dataset, Challenges, and Lessons Learned
Jan 28, 2026Decentralized collaborative simultaneous localization and mapping (C-SLAM) is essential to enable multirobot missions in unknown environments without relying on preexisting localization and communication infrastructure. This technology is anticipated to play a key role in the exploration of the Moon, Mars, and other planets. In this article, we share insights and lessons learned from C-SLAM experiments involving three robots operating on a Mars analogue terrain and communicating over an ad hoc network. We examine the impact of limited and intermittent communication on C-SLAM performance, as well as the unique localization challenges posed by planetary-like environments. Additionally, we introduce a novel dataset collected during our experiments, which includes real-time peer-to-peer inter-robot throughput and latency measurements. This dataset aims to support future research on communication-constrained, decentralized multirobot operations.
Revisiting the Learning Objectives of Vision-Language Reward Models
Dec 20, 2025Learning generalizable reward functions is a core challenge in embodied intelligence. Recent work leverages contrastive vision language models (VLMs) to obtain dense, domain-agnostic rewards without human supervision. These methods adapt VLMs into reward models through increasingly complex learning objectives, yet meaningful comparison remains difficult due to differences in training data, architectures, and evaluation settings. In this work, we isolate the impact of the learning objective by evaluating recent VLM-based reward models under a unified framework with identical backbones, finetuning data, and evaluation environments. Using Meta-World tasks, we assess modeling accuracy by measuring consistency with ground truth reward and correlation with expert progress. Remarkably, we show that a simple triplet loss outperforms state-of-the-art methods, suggesting that much of the improvements in recent approaches could be attributed to differences in data and architectures.
E-RGB-D: Real-Time Event-Based Perception with Structured Light
Dec 20, 2025



Event-based cameras (ECs) have emerged as bio-inspired sensors that report pixel brightness changes asynchronously, offering unmatched speed and efficiency in vision sensing. Despite their high dynamic range, temporal resolution, low power consumption, and computational simplicity, traditional monochrome ECs face limitations in detecting static or slowly moving objects and lack color information essential for certain applications. To address these challenges, we present a novel approach that integrates a Digital Light Processing (DLP) projector, forming Active Structured Light (ASL) for RGB-D sensing. By combining the benefits of ECs and projection-based techniques, our method enables the detection of color and the depth of each pixel separately. Dynamic projection adjustments optimize bandwidth, ensuring selective color data acquisition and yielding colorful point clouds without sacrificing spatial resolution. This integration, facilitated by a commercial TI LightCrafter 4500 projector and a monocular monochrome EC, not only enables frameless RGB-D sensing applications but also achieves remarkable performance milestones. With our approach, we achieved a color detection speed equivalent to 1400 fps and 4 kHz of pixel depth detection, significantly advancing the realm of computer vision across diverse fields from robotics to 3D reconstruction methods. Our code is publicly available: https://github.com/MISTLab/event_based_rgbd_ros
Guided by Guardrails: Control Barrier Functions as Safety Instructors for Robotic Learning
May 24, 2025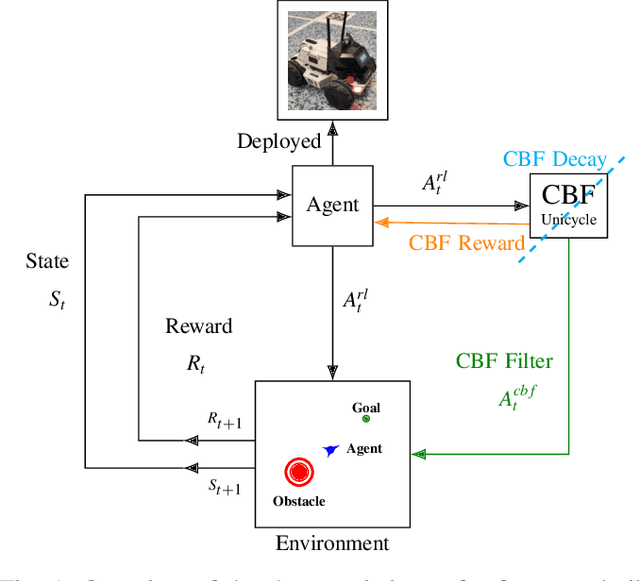
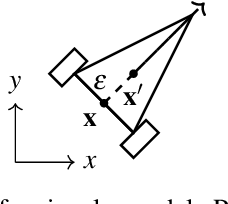
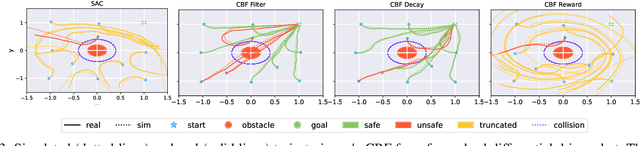
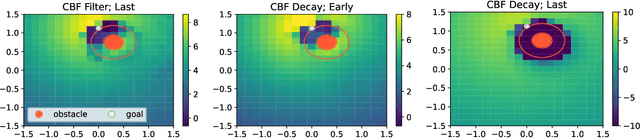
Safety stands as the primary obstacle preventing the widespread adoption of learning-based robotic systems in our daily lives. While reinforcement learning (RL) shows promise as an effective robot learning paradigm, conventional RL frameworks often model safety by using single scalar negative rewards with immediate episode termination, failing to capture the temporal consequences of unsafe actions (e.g., sustained collision damage). In this work, we introduce a novel approach that simulates these temporal effects by applying continuous negative rewards without episode termination. Our experiments reveal that standard RL methods struggle with this model, as the accumulated negative values in unsafe zones create learning barriers. To address this challenge, we demonstrate how Control Barrier Functions (CBFs), with their proven safety guarantees, effectively help robots avoid catastrophic regions while enhancing learning outcomes. We present three CBF-based approaches, each integrating traditional RL methods with Control Barrier Functions, guiding the agent to learn safe behavior. Our empirical analysis, conducted in both simulated environments and real-world settings using a four-wheel differential drive robot, explores the possibilities of employing these approaches for safe robotic learning.