 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvolution with Opponent-Learning Awareness
Paper and Code
Oct 22, 2024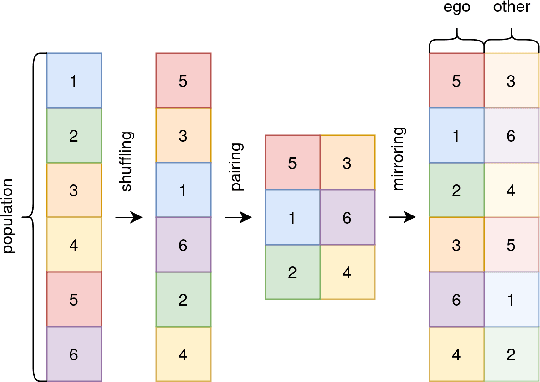
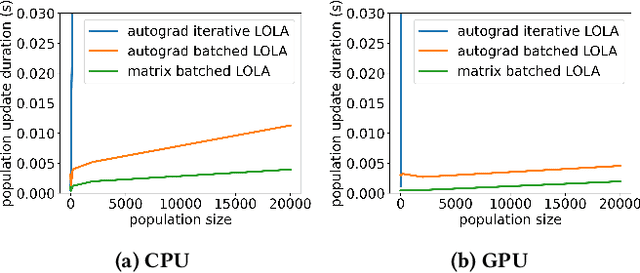
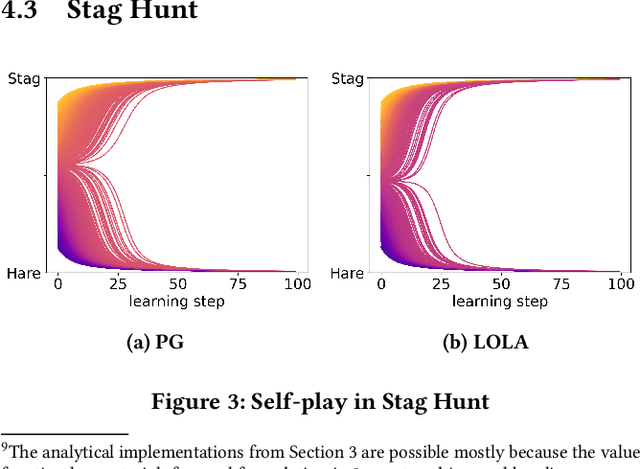

The universe involves many independent co-learning agents as an ever-evolving part of our observed environment. Yet, in practice, Multi-Agent Reinforcement Learning (MARL) applications are usually constrained to small, homogeneous populations and remain computationally intensive. In this paper, we study how large heterogeneous populations of learning agents evolve in normal-form games. We show how, under assumptions commonly made in the multi-armed bandit literature, Multi-Agent Policy Gradient closely resembles the Replicator Dynamic, and we further derive a fast, parallelizable implementation of Opponent-Learning Awareness tailored for evolutionary simulations. This enables us to simulate the evolution of very large populations made of heterogeneous co-learning agents, under both naive and advanced learning strategies. We demonstrate our approach in simulations of 200,000 agents, evolving in the classic games of Hawk-Dove, Stag-Hunt, and Rock-Paper-Scissors. Each game highlights distinct ways in which Opponent-Learning Awareness affects evolution.