 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBridging Swarm Intelligence and Reinforcement Learning
Oct 23, 2024



Swarm intelligence (SI) explores how large groups of simple individuals (e.g., insects, fish, birds) collaborate to produce complex behaviors, exemplifying that the whole is greater than the sum of its parts. A fundamental task in SI is Collective Decision-Making (CDM), where a group selects the best option among several alternatives, such as choosing an optimal foraging site. In this work, we demonstrate a theoretical and empirical equivalence between CDM and single-agent reinforcement learning (RL) in multi-armed bandit problems, utilizing concepts from opinion dynamics, evolutionary game theory, and RL. This equivalence bridges the gap between SI and RL and leads us to introduce a novel abstract RL update rule called Maynard-Cross Learning. Additionally, it provides a new population-based perspective on common RL practices like learning rate adjustment and batching. Our findings enable cross-disciplinary fertilization between RL and SI, allowing techniques from one field to enhance the understanding and methodologies of the other.
Evolution with Opponent-Learning Awareness
Oct 22, 2024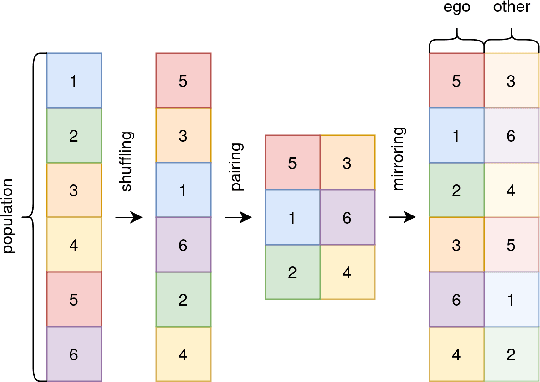
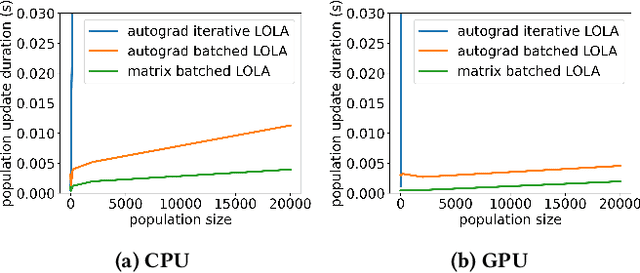
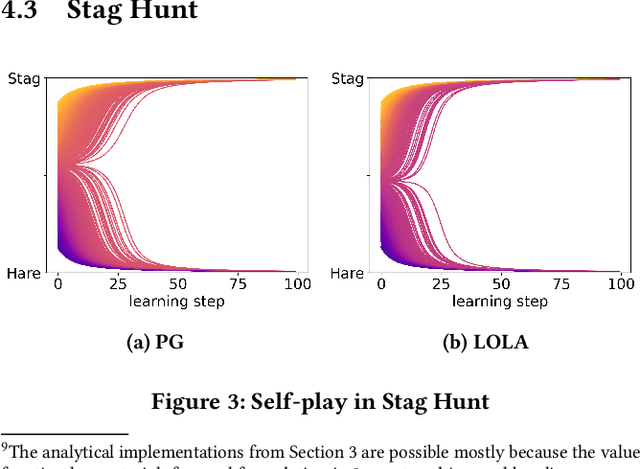

The universe involves many independent co-learning agents as an ever-evolving part of our observed environment. Yet, in practice, Multi-Agent Reinforcement Learning (MARL) applications are usually constrained to small, homogeneous populations and remain computationally intensive. In this paper, we study how large heterogeneous populations of learning agents evolve in normal-form games. We show how, under assumptions commonly made in the multi-armed bandit literature, Multi-Agent Policy Gradient closely resembles the Replicator Dynamic, and we further derive a fast, parallelizable implementation of Opponent-Learning Awareness tailored for evolutionary simulations. This enables us to simulate the evolution of very large populations made of heterogeneous co-learning agents, under both naive and advanced learning strategies. We demonstrate our approach in simulations of 200,000 agents, evolving in the classic games of Hawk-Dove, Stag-Hunt, and Rock-Paper-Scissors. Each game highlights distinct ways in which Opponent-Learning Awareness affects evolution.
From the Lab to the Theater: An Unconventional Field Robotics Journey
Apr 11, 2024Artistic performances involving robotic systems present unique technical challenges akin to those encountered in other field deployments. In this paper, we delve into the orchestration of robotic artistic performances, focusing on the complexities inherent in communication protocols and localization methods. Through our case studies and experimental insights, we demonstrate the breadth of technical requirements for this type of deployment, and, most importantly, the significant contributions of working closely with non-experts.
The Portiloop: a deep learning-based open science tool for closed-loop brain stimulation
Jul 30, 2021
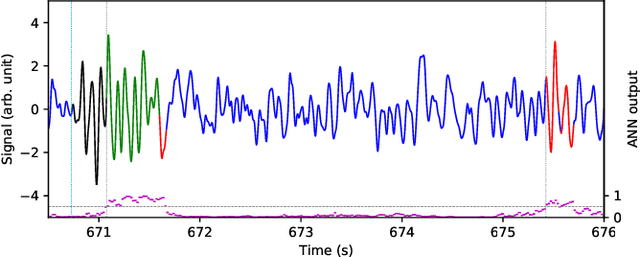
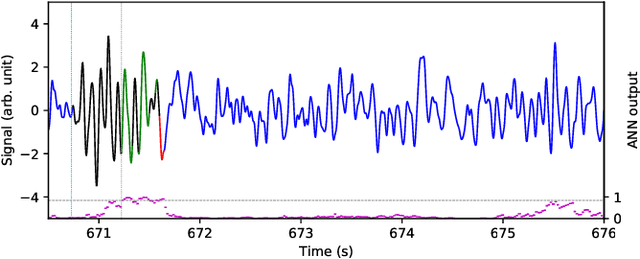
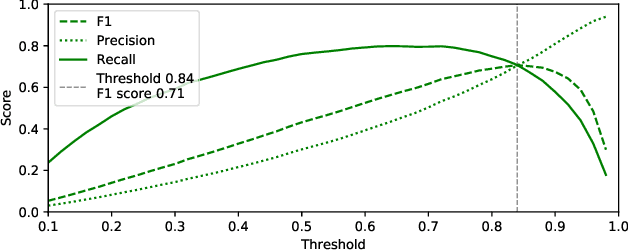
Electroencephalography (EEG) is a method of measuring the brain's electrical activity, using non-invasive scalp electrodes. In this article, we propose the Portiloop, a deep learning-based portable and low-cost device enabling the neuroscience community to capture EEG, process it in real time, detect patterns of interest, and respond with precisely-timed stimulation. The core of the Portiloop is a System on Chip composed of an Analog to Digital Converter (ADC) and a Field-Programmable Gate Array (FPGA). After being converted to digital by the ADC, the EEG signal is processed in the FPGA. The FPGA contains an ad-hoc Artificial Neural Network (ANN) with convolutional and recurrent units, directly implemented in hardware. The output of the ANN is then used to trigger the user-defined feedback. We use the Portiloop to develop a real-time sleep spindle stimulating application, as a case study. Sleep spindles are a specific type of transient oscillation ($\sim$2.5 s, 12-16 Hz) that are observed in EEG recordings, and are related to memory consolidation during sleep. We tested the Portiloop's capacity to detect and stimulate sleep spindles in real time using an existing database of EEG sleep recordings. With 71% for both precision and recall as compared with expert labels, the system is able to stimulate spindles within $\sim$300 ms of their onset, enabling experimental manipulation of early the entire spindle. The Portiloop can be extended to detect and stimulate other neural events in EEG. It is fully available to the research community as an open science project.
Reinforcement Learning with Random Delays
Oct 08, 2020
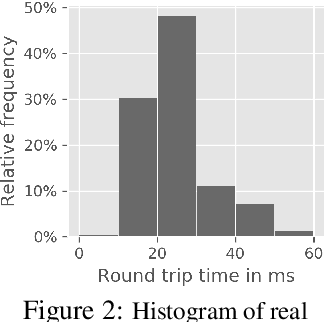
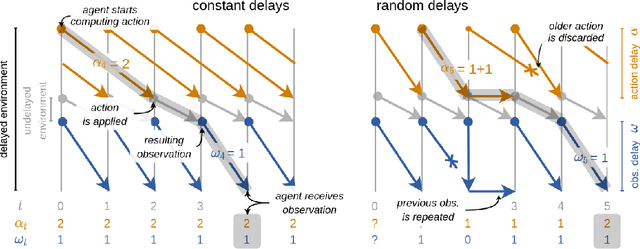
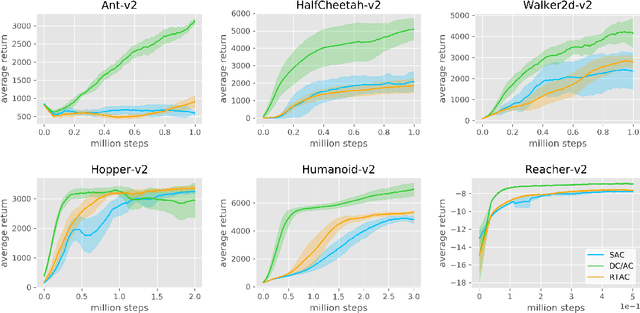
Action and observation delays commonly occur in many Reinforcement Learning applications, such as remote control scenarios. We study the anatomy of randomly delayed environments, and show that partially resampling trajectory fragments in hindsight allows for off-policy multi-step value estimation. We apply this principle to derive Delay-Correcting Actor-Critic (DCAC), an algorithm based on Soft Actor-Critic with significantly better performance in environments with delays. This is shown theoretically and also demonstrated practically on a delay-augmented version of the MuJoCo continuous control benchmark.