 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBlabberSeg: Real-Time Embedded Open-Vocabulary Aerial Segmentation
Oct 16, 2024



Real-time aerial image segmentation plays an important role in the environmental perception of Uncrewed Aerial Vehicles (UAVs). We introduce BlabberSeg, an optimized Vision-Language Model built on CLIPSeg for on-board, real-time processing of aerial images by UAVs. BlabberSeg improves the efficiency of CLIPSeg by reusing prompt and model features, reducing computational overhead while achieving real-time open-vocabulary aerial segmentation. We validated BlabberSeg in a safe landing scenario using the Dynamic Open-Vocabulary Enhanced SafE-Landing with Intelligence (DOVESEI) framework, which uses visual servoing and open-vocabulary segmentation. BlabberSeg reduces computational costs significantly, with a speed increase of 927.41% (16.78 Hz) on a NVIDIA Jetson Orin AGX (64GB) compared with the original CLIPSeg (1.81Hz), achieving real-time aerial segmentation with negligible loss in accuracy (2.1% as the ratio of the correctly segmented area with respect to CLIPSeg). BlabberSeg's source code is open and available online.
PEACE: Prompt Engineering Automation for CLIPSeg Enhancement in Aerial Robotics
Sep 29, 2023From industrial to space robotics, safe landing is an essential component for flight operations. With the growing interest in artificial intelligence, we direct our attention to learning based safe landing approaches. This paper extends our previous work, DOVESEI, which focused on a reactive UAV system by harnessing the capabilities of open vocabulary image segmentation. Prompt-based safe landing zone segmentation using an open vocabulary based model is no more just an idea, but proven to be feasible by the work of DOVESEI. However, a heuristic selection of words for prompt is not a reliable solution since it cannot take the changing environment into consideration and detrimental consequences can occur if the observed environment is not well represented by the given prompt. Therefore, we introduce PEACE (Prompt Engineering Automation for CLIPSeg Enhancement), powering DOVESEI to automate the prompt generation and engineering to adapt to data distribution shifts. Our system is capable of performing safe landing operations with collision avoidance at altitudes as low as 20 meters using only monocular cameras and image segmentation. We take advantage of DOVESEI's dynamic focus to circumvent abrupt fluctuations in the terrain segmentation between frames in a video stream. PEACE shows promising improvements in prompt generation and engineering for aerial images compared to the standard prompt used for CLIP and CLIPSeg. Combining DOVESEI and PEACE, our system was able improve successful safe landing zone selections by 58.62% compared to using only DOVESEI. All the source code is open source and available online.
Dynamic Open Vocabulary Enhanced Safe-landing with Intelligence (DOVESEI)
Aug 24, 2023This work targets what we consider to be the foundational step for urban airborne robots, a safe landing. Our attention is directed toward what we deem the most crucial aspect of the safe landing perception stack: segmentation. We present a streamlined reactive UAV system that employs visual servoing by harnessing the capabilities of open vocabulary image segmentation. This approach can adapt to various scenarios with minimal adjustments, bypassing the necessity for extensive data accumulation for refining internal models, thanks to its open vocabulary methodology. Given the limitations imposed by local authorities, our primary focus centers on operations originating from altitudes of 100 meters. This choice is deliberate, as numerous preceding works have dealt with altitudes up to 30 meters, aligning with the capabilities of small stereo cameras. Consequently, we leave the remaining 20m to be navigated using conventional 3D path planning methods. Utilizing monocular cameras and image segmentation, our findings demonstrate the system's capability to successfully execute landing maneuvers at altitudes as low as 20 meters. However, this approach is vulnerable to intermittent and occasionally abrupt fluctuations in the segmentation between frames in a video stream. To address this challenge, we enhance the image segmentation output by introducing what we call a dynamic focus: a masking mechanism that self adjusts according to the current landing stage. This dynamic focus guides the control system to avoid regions beyond the drone's safety radius projected onto the ground, thus mitigating the problems with fluctuations. Through the implementation of this supplementary layer, our experiments have reached improvements in the landing success rate of almost tenfold when compared to global segmentation. All the source code is open source and available online (github.com/MISTLab/DOVESEI).
A Flexible Exoskeleton for Collision Resilience
Jul 23, 2021

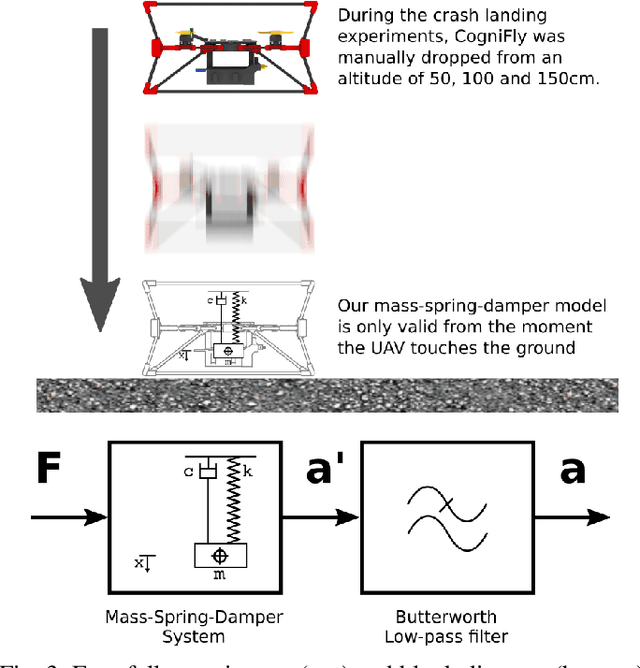

With inspiration from arthropods' exoskeletons, we designed a simple, easily manufactured, semi-rigid structure with flexible joints that can passively damp impact energy. This exoskeleton fuses the protective shell to the main robot structure, thereby minimizing its loss in payload capacity. Our design is simple to build and customize using cheap components and consumer-grade 3D printers. Our results show we can build a sub-250g, autonomous quadcopter with visual navigation that can survive multiple collisions, shows a five-fold increase in the passive energy absorption, that is also suitable for automated battery swapping, and with enough computing power to run deep neural network models. This structure makes for an ideal platform for high-risk activities (such as flying in a cluttered environment or reinforcement learning training) without damage to the hardware or the environment.
When Being Soft Makes You Tough: A Collision Resilient Quadcopter Inspired by Arthropod Exoskeletons
Mar 07, 2021

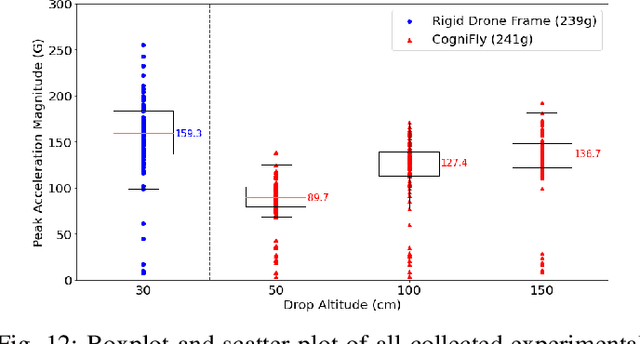
Flying robots are usually rather delicate, and require protective enclosures when facing the risk of collision. High complexity and reduced payload are recurrent problems with collision-tolerant flying robots. Inspired by arthropods' exoskeletons, we design a simple, easily manufactured, semi-rigid structure with flexible joints that can withstand high-velocity impacts. With an exoskeleton, the protective shell becomes part of the main robot structure, thereby minimizing its loss in payload capacity. Our design is simple to build and customize using cheap components and consumer-grade 3D printers. Our results show we can build a sub-250g, autonomous quadcopter with visual navigation that can survive multiple collisions at speeds up to 7m/s that is also suitable for automated battery swapping, and with enough computing power to run deep neural network models. This structure makes for an ideal platform for high-risk activities (such as flying in a cluttered environment or reinforcement learning training) without damage to the hardware or the environment.
CAPRICORN: Communication Aware Place Recognition using Interpretable Constellations of Objects in Robot Networks
Oct 19, 2019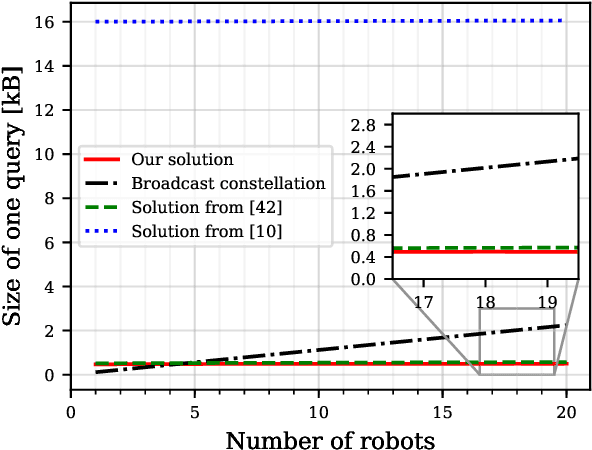
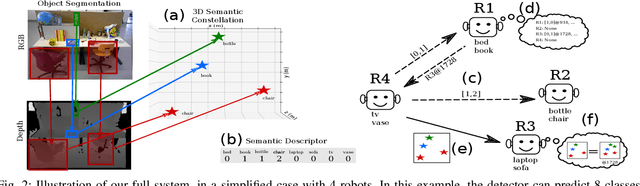
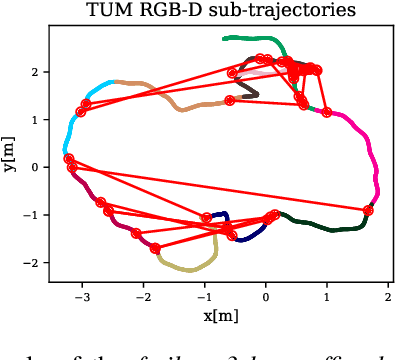
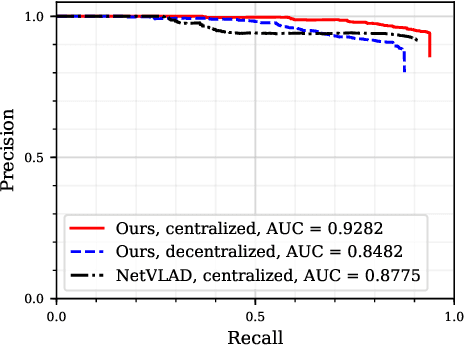
Using multiple robots for exploring and mapping environments can provide improved robustness and performance, but it can be difficult to implement. In particular, limited communication bandwidth is a considerable constraint when a robot needs to determine if it has visited a location that was previously explored by another robot, as it requires for robots to share descriptions of places they have visited. One way to compress this description is to use constellations, groups of 3D points that correspond to the estimate of a set of relative object positions. Constellations maintain the same pattern from different viewpoints and can be robust to illumination changes or dynamic elements. We present a method to extract from these constellations compact spatial and semantic descriptors of the objects in a scene. We use this representation in a 2-step decentralized loop closure verification: first, we distribute the compact semantic descriptors to determine which other robots might have seen scenes with similar objects; then we query matching robots with the full constellation to validate the match using geometric information. The proposed method requires less memory, is more interpretable than global image descriptors, and could be useful for other tasks and interactions with the environment. We validate our system's performance on a TUM RGB-D SLAM sequence and show its benefits in terms of bandwidth requirements.