 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDomain Aligned CLIP for Few-shot Classification
Nov 15, 2023Large vision-language representation learning models like CLIP have demonstrated impressive performance for zero-shot transfer to downstream tasks while largely benefiting from inter-modal (image-text) alignment via contrastive objectives. This downstream performance can further be enhanced by full-scale fine-tuning which is often compute intensive, requires large labelled data, and can reduce out-of-distribution (OOD) robustness. Furthermore, sole reliance on inter-modal alignment might overlook the rich information embedded within each individual modality. In this work, we introduce a sample-efficient domain adaptation strategy for CLIP, termed Domain Aligned CLIP (DAC), which improves both intra-modal (image-image) and inter-modal alignment on target distributions without fine-tuning the main model. For intra-modal alignment, we introduce a lightweight adapter that is specifically trained with an intra-modal contrastive objective. To improve inter-modal alignment, we introduce a simple framework to modulate the precomputed class text embeddings. The proposed few-shot fine-tuning framework is computationally efficient, robust to distribution shifts, and does not alter CLIP's parameters. We study the effectiveness of DAC by benchmarking on 11 widely used image classification tasks with consistent improvements in 16-shot classification upon strong baselines by about 2.3% and demonstrate competitive performance on 4 OOD robustness benchmarks.
Dynamic Inference with Neural Interpreters
Oct 12, 2021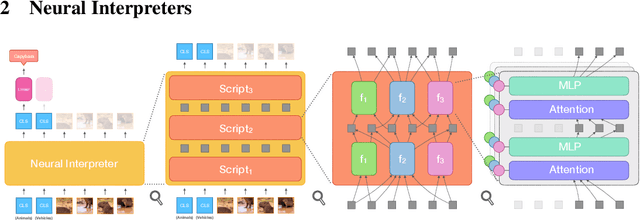
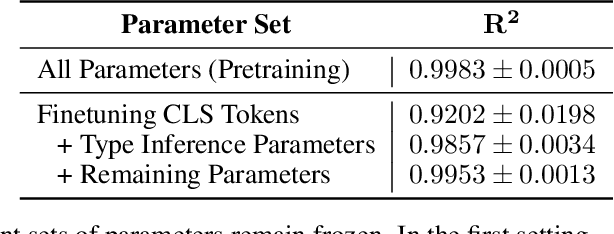
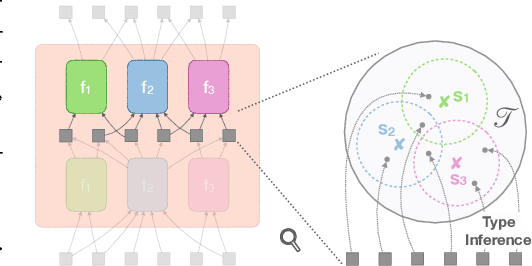
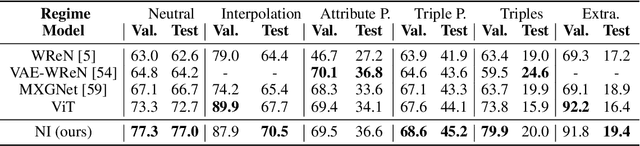
Modern neural network architectures can leverage large amounts of data to generalize well within the training distribution. However, they are less capable of systematic generalization to data drawn from unseen but related distributions, a feat that is hypothesized to require compositional reasoning and reuse of knowledge. In this work, we present Neural Interpreters, an architecture that factorizes inference in a self-attention network as a system of modules, which we call \emph{functions}. Inputs to the model are routed through a sequence of functions in a way that is end-to-end learned. The proposed architecture can flexibly compose computation along width and depth, and lends itself well to capacity extension after training. To demonstrate the versatility of Neural Interpreters, we evaluate it in two distinct settings: image classification and visual abstract reasoning on Raven Progressive Matrices. In the former, we show that Neural Interpreters perform on par with the vision transformer using fewer parameters, while being transferrable to a new task in a sample efficient manner. In the latter, we find that Neural Interpreters are competitive with respect to the state-of-the-art in terms of systematic generalization
Function Contrastive Learning of Transferable Representations
Oct 14, 2020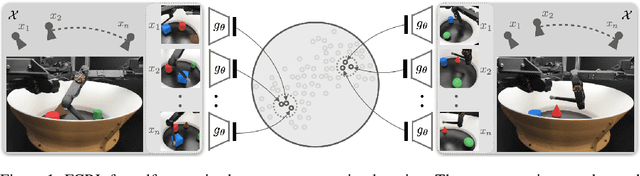
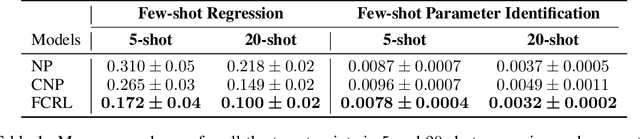
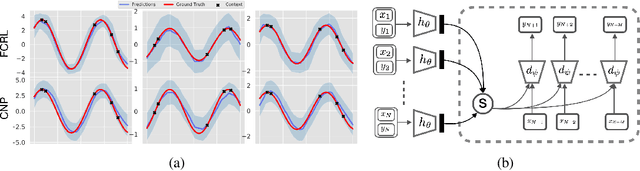
Few-shot-learning seeks to find models that are capable of fast-adaptation to novel tasks. Unlike typical few-shot learning algorithms, we propose a contrastive learning method which is not trained to solve a set of tasks, but rather attempts to find a good representation of the underlying data-generating processes (\emph{functions}). This allows for finding representations which are useful for an entire series of tasks sharing the same function. In particular, our training scheme is driven by the self-supervision signal indicating whether two sets of samples stem from the same underlying function. Our experiments on a number of synthetic and real-world datasets show that the representations we obtain can outperform strong baselines in terms of downstream performance and noise robustness, even when these baselines are trained in an end-to-end manner.
S2RMs: Spatially Structured Recurrent Modules
Jul 13, 2020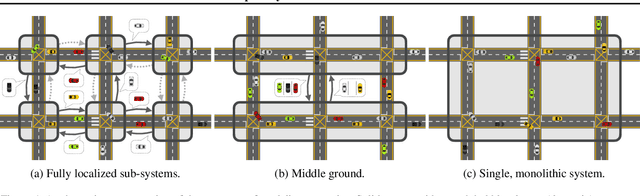
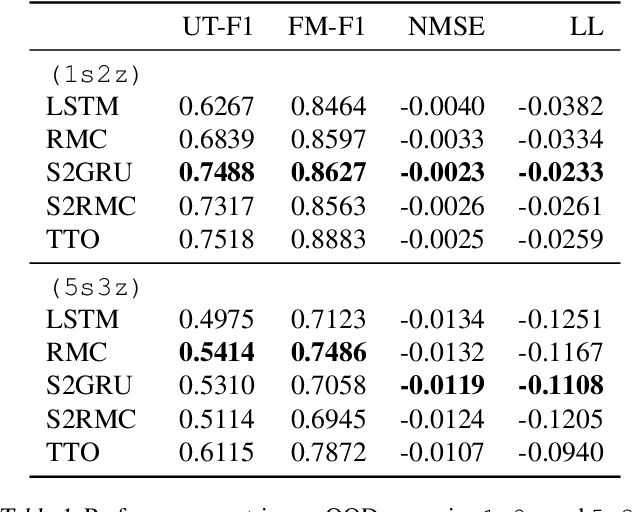
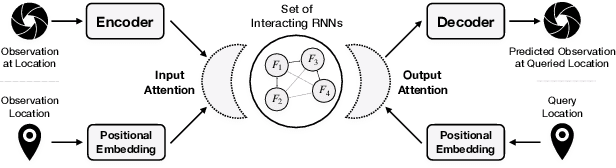
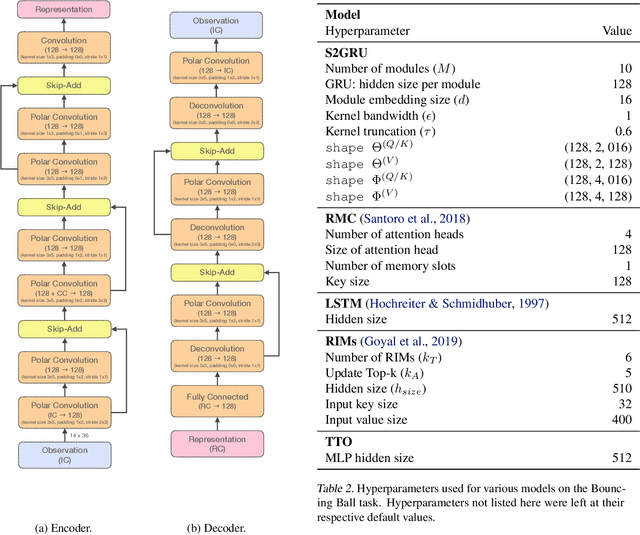
Capturing the structure of a data-generating process by means of appropriate inductive biases can help in learning models that generalize well and are robust to changes in the input distribution. While methods that harness spatial and temporal structures find broad application, recent work has demonstrated the potential of models that leverage sparse and modular structure using an ensemble of sparingly interacting modules. In this work, we take a step towards dynamic models that are capable of simultaneously exploiting both modular and spatiotemporal structures. We accomplish this by abstracting the modeled dynamical system as a collection of autonomous but sparsely interacting sub-systems. The sub-systems interact according to a topology that is learned, but also informed by the spatial structure of the underlying real-world system. This results in a class of models that are well suited for modeling the dynamics of systems that only offer local views into their state, along with corresponding spatial locations of those views. On the tasks of video prediction from cropped frames and multi-agent world modeling from partial observations in the challenging Starcraft2 domain, we find our models to be more robust to the number of available views and better capable of generalization to novel tasks without additional training, even when compared against strong baselines that perform equally well or better on the training distribution.
On the Transfer of Inductive Bias from Simulation to the Real World: a New Disentanglement Dataset
Jun 07, 2019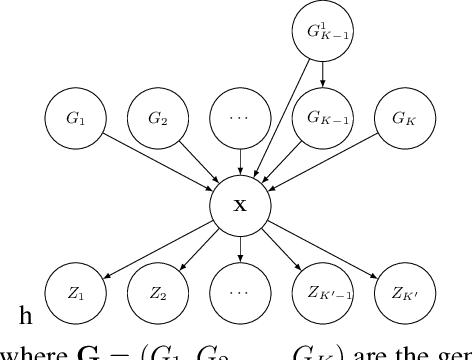
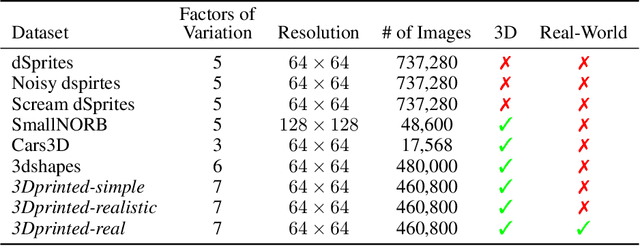
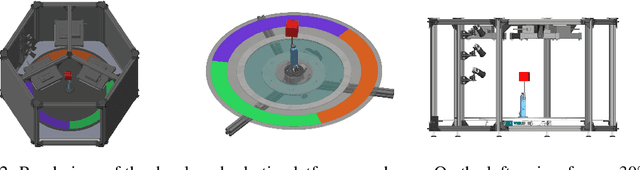
Learning meaningful and compact representations with structurally disentangled semantic aspects is considered to be of key importance in representation learning. Since real-world data is notoriously costly to collect, many recent state-of-the-art disentanglement models have heavily relied on synthetic toy data-sets. In this paper, we propose a novel data-set which consists of over 450'000 images of physical 3D objects with seven factors of variation, such as object color, shape, size and position. In order to be able to control all the factors of variation precisely, we built an experimental platform where the objects are being moved by a robotic arm. In addition, we provide two more datasets which consist of simulations of the experimental setup. These datasets provide for the first time the possibility to systematically investigate how well different disentanglement methods perform on real data in comparison to simulation, and how simulated data can be leveraged to build better representations of the real world.
Disentangled State Space Representations
Jun 07, 2019

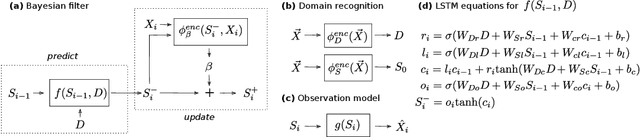
Sequential data often originates from diverse domains across which statistical regularities and domain specifics exist. To specifically learn cross-domain sequence representations, we introduce disentangled state space models (DSSM) -- a class of SSM in which domain-invariant state dynamics is explicitly disentangled from domain-specific information governing that dynamics. We analyze how such separation can improve knowledge transfer to new domains, and enable robust prediction, sequence manipulation and domain characterization. We furthermore propose an unsupervised VAE-based training procedure to implement DSSM in form of Bayesian filters. In our experiments, we applied VAE-DSSM framework to achieve competitive performance in online ODE system identification and regression across experimental settings, and controlled generation and prediction of bouncing ball video sequences across varying gravitational influences.
Kernel Mean Matching for Content Addressability of GANs
May 14, 2019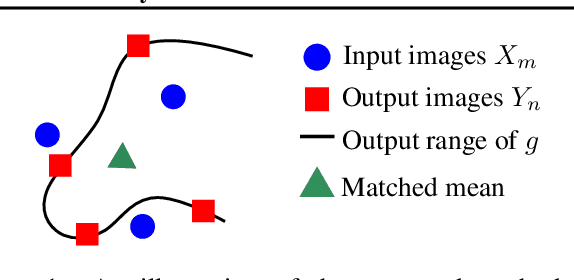
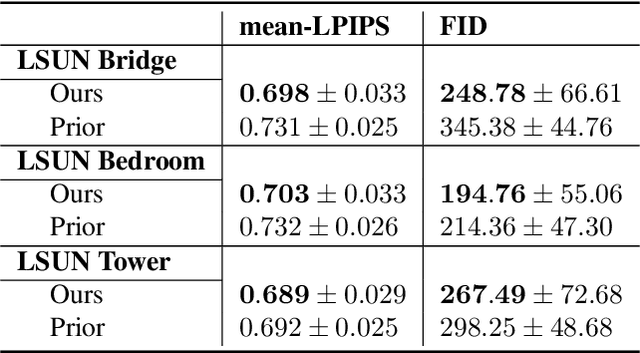


We propose a novel procedure which adds "content-addressability" to any given unconditional implicit model e.g., a generative adversarial network (GAN). The procedure allows users to control the generative process by specifying a set (arbitrary size) of desired examples based on which similar samples are generated from the model. The proposed approach, based on kernel mean matching, is applicable to any generative models which transform latent vectors to samples, and does not require retraining of the model. Experiments on various high-dimensional image generation problems (CelebA-HQ, LSUN bedroom, bridge, tower) show that our approach is able to generate images which are consistent with the input set, while retaining the image quality of the original model. To our knowledge, this is the first work that attempts to construct, at test time, a content-addressable generative model from a trained marginal model.
The Unreasonable Effectiveness of Texture Transfer for Single Image Super-resolution
Jul 31, 2018
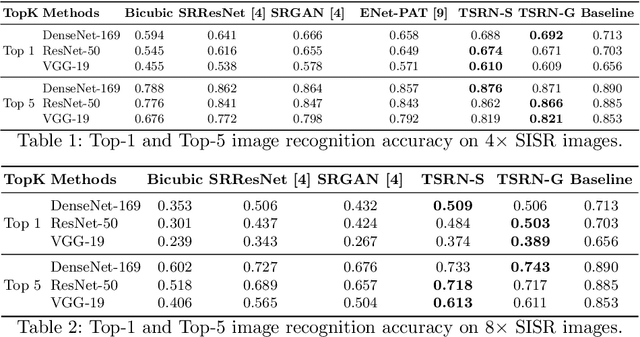

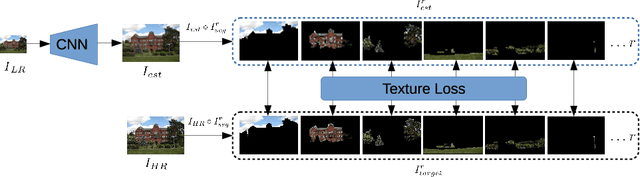
While implicit generative models such as GANs have shown impressive results in high quality image reconstruction and manipulation using a combination of various losses, we consider a simpler approach leading to surprisingly strong results. We show that texture loss alone allows the generation of perceptually high quality images. We provide a better understanding of texture constraining mechanism and develop a novel semantically guided texture constraining method for further improvement. Using a recently developed perceptual metric employing "deep features" and termed LPIPS, the method obtains state-of-the-art results. Moreover, we show that a texture representation of those deep features better capture the perceptual quality of an image than the original deep features. Using texture information, off-the-shelf deep classification networks (without training) perform as well as the best performing (tuned and calibrated) LPIPS metrics. The code is publicly available.