 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Unreasonable Effectiveness of Texture Transfer for Single Image Super-resolution
Jul 31, 2018
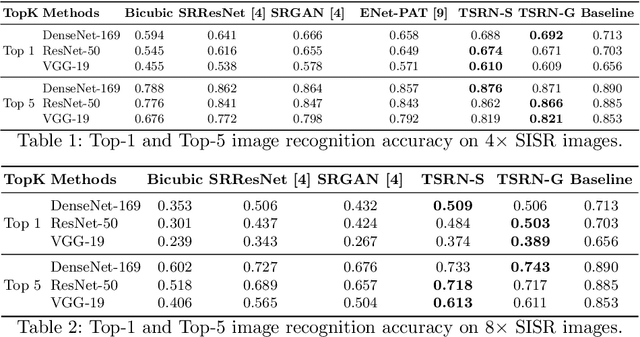

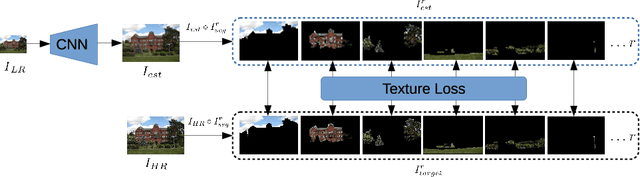
While implicit generative models such as GANs have shown impressive results in high quality image reconstruction and manipulation using a combination of various losses, we consider a simpler approach leading to surprisingly strong results. We show that texture loss alone allows the generation of perceptually high quality images. We provide a better understanding of texture constraining mechanism and develop a novel semantically guided texture constraining method for further improvement. Using a recently developed perceptual metric employing "deep features" and termed LPIPS, the method obtains state-of-the-art results. Moreover, we show that a texture representation of those deep features better capture the perceptual quality of an image than the original deep features. Using texture information, off-the-shelf deep classification networks (without training) perform as well as the best performing (tuned and calibrated) LPIPS metrics. The code is publicly available.
Photorealistic Video Super Resolution
Jul 20, 2018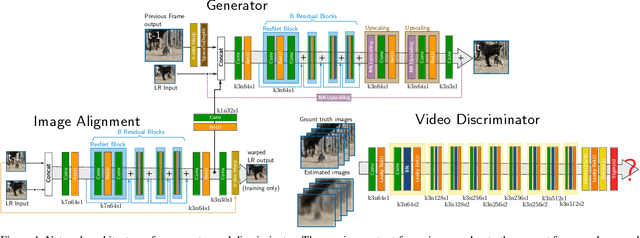
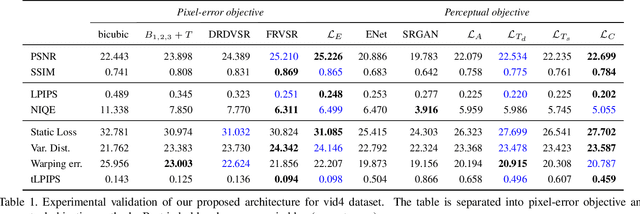
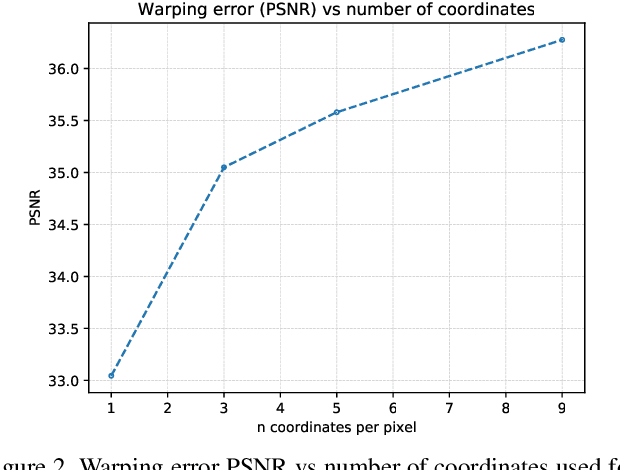
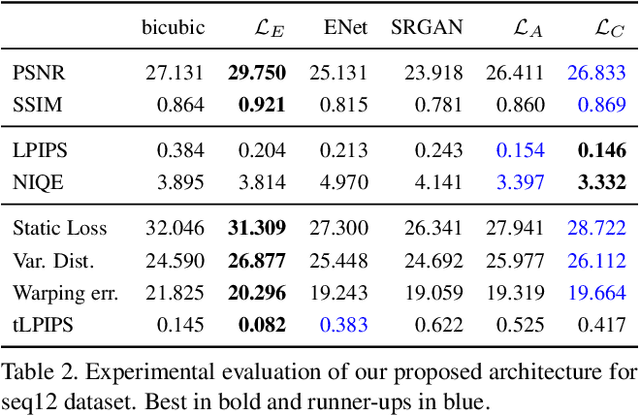
With the advent of perceptual loss functions, new possibilities in super-resolution have emerged, and we currently have models that successfully generate near-photorealistic high-resolution images from their low-resolution observations. Up to now, however, such approaches have been exclusively limited to single image super-resolution. The application of perceptual loss functions on video processing still entails several challenges, mostly related to the lack of temporal consistency of the generated images, i.e., flickering artifacts. In this work, we present a novel adversarial recurrent network for video upscaling that is able to produce realistic textures in a temporally consistent way. The proposed architecture naturally leverages information from previous frames due to its recurrent architecture, i.e. the input to the generator is composed of the low-resolution image and, additionally, the warped output of the network at the previous step. We also propose an additional loss function to further reinforce temporal consistency in the generated sequences. The experimental validation of our algorithm shows the effectiveness of our approach which obtains competitive samples in terms of perceptual quality with improved temporal consistency.
Automatic Estimation of Modulation Transfer Functions
May 04, 2018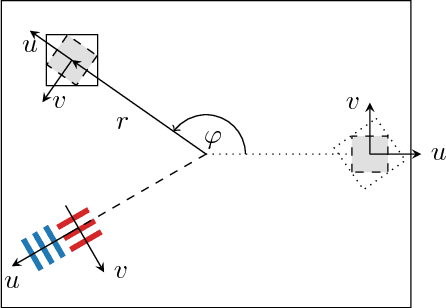
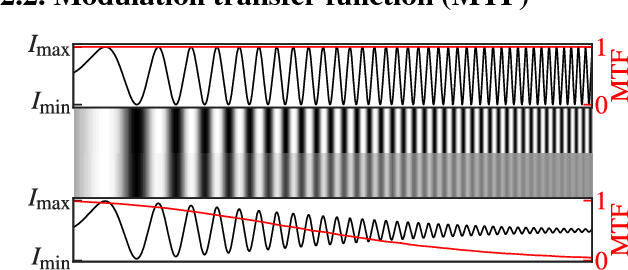
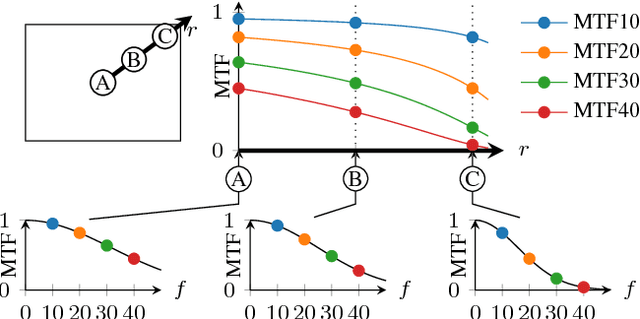
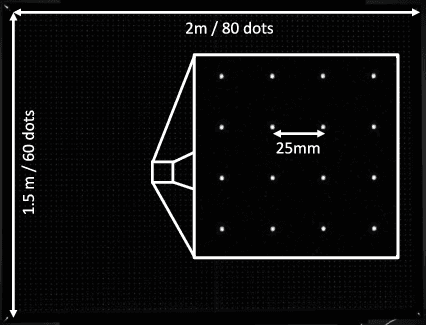
The modulation transfer function (MTF) is widely used to characterise the performance of optical systems. Measuring it is costly and it is thus rarely available for a given lens specimen. Instead, MTFs based on simulations or, at best, MTFs measured on other specimens of the same lens are used. Fortunately, images recorded through an optical system contain ample information about its MTF, only that it is confounded with the statistics of the images. This work presents a method to estimate the MTF of camera lens systems directly from photographs, without the need for expensive equipment. We use a custom grid display to accurately measure the point response of lenses to acquire ground truth training data. We then use the same lenses to record natural images and employ a data-driven supervised learning approach using a convolutional neural network to estimate the MTF on small image patches, aggregating the information into MTF charts over the entire field of view. It generalises to unseen lenses and can be applied for single photographs, with the performance improving if multiple photographs are available.
Learning Blind Motion Deblurring
Aug 14, 2017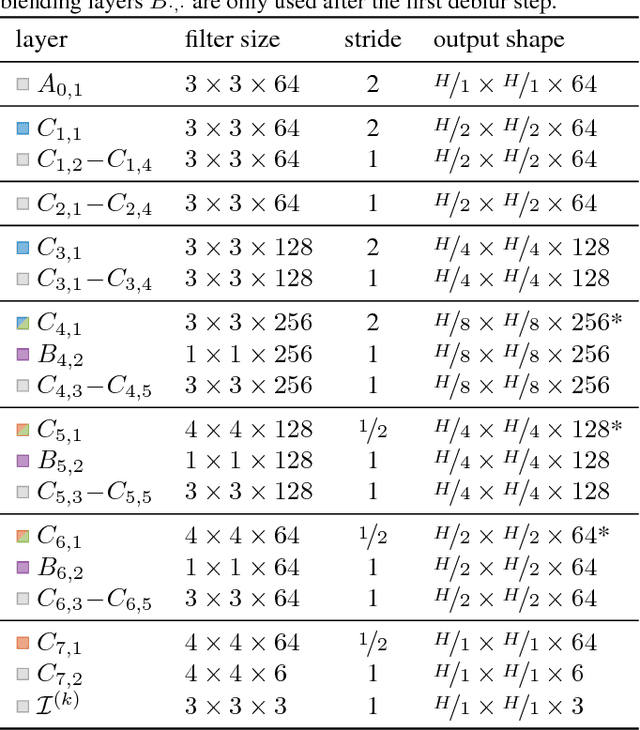

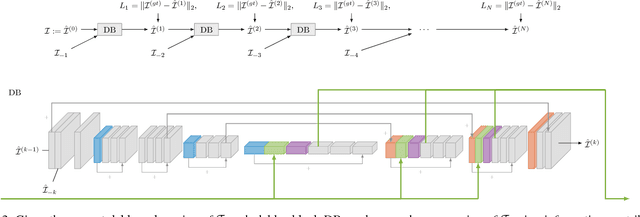

As handheld video cameras are now commonplace and available in every smartphone, images and videos can be recorded almost everywhere at anytime. However, taking a quick shot frequently yields a blurry result due to unwanted camera shake during recording or moving objects in the scene. Removing these artifacts from the blurry recordings is a highly ill-posed problem as neither the sharp image nor the motion blur kernel is known. Propagating information between multiple consecutive blurry observations can help restore the desired sharp image or video. Solutions for blind deconvolution based on neural networks rely on a massive amount of ground-truth data which is hard to acquire. In this work, we propose an efficient approach to produce a significant amount of realistic training data and introduce a novel recurrent network architecture to deblur frames taking temporal information into account, which can efficiently handle arbitrary spatial and temporal input sizes. We demonstrate the versatility of our approach in a comprehensive comparison on a number of challening real-world examples.
EnhanceNet: Single Image Super-Resolution Through Automated Texture Synthesis
Jul 30, 2017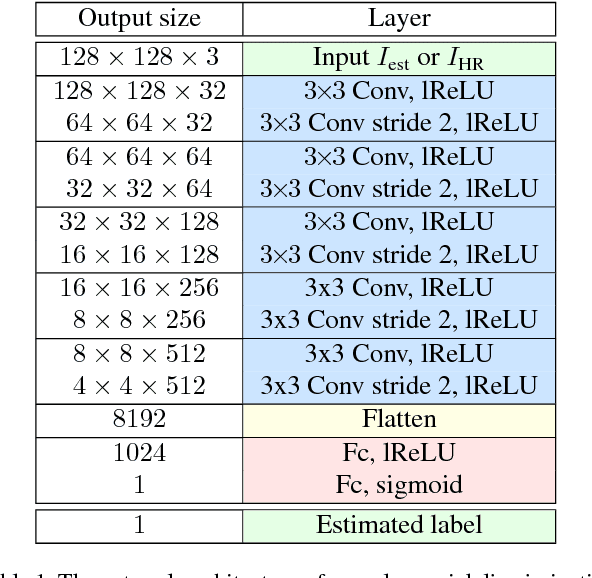


Single image super-resolution is the task of inferring a high-resolution image from a single low-resolution input. Traditionally, the performance of algorithms for this task is measured using pixel-wise reconstruction measures such as peak signal-to-noise ratio (PSNR) which have been shown to correlate poorly with the human perception of image quality. As a result, algorithms minimizing these metrics tend to produce over-smoothed images that lack high-frequency textures and do not look natural despite yielding high PSNR values. We propose a novel application of automated texture synthesis in combination with a perceptual loss focusing on creating realistic textures rather than optimizing for a pixel-accurate reproduction of ground truth images during training. By using feed-forward fully convolutional neural networks in an adversarial training setting, we achieve a significant boost in image quality at high magnification ratios. Extensive experiments on a number of datasets show the effectiveness of our approach, yielding state-of-the-art results in both quantitative and qualitative benchmarks.
Weakly-supervised localization of diabetic retinopathy lesions in retinal fundus images
Jun 29, 2017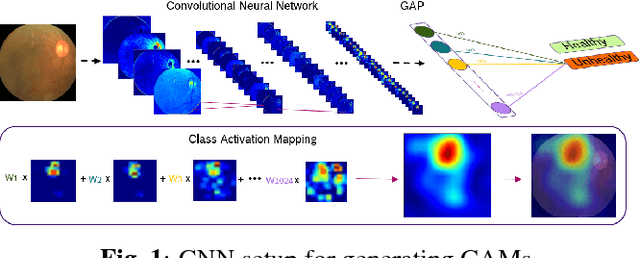

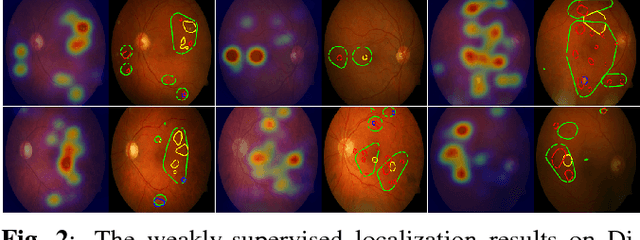

Convolutional neural networks (CNNs) show impressive performance for image classification and detection, extending heavily to the medical image domain. Nevertheless, medical experts are sceptical in these predictions as the nonlinear multilayer structure resulting in a classification outcome is not directly graspable. Recently, approaches have been shown which help the user to understand the discriminative regions within an image which are decisive for the CNN to conclude to a certain class. Although these approaches could help to build trust in the CNNs predictions, they are only slightly shown to work with medical image data which often poses a challenge as the decision for a class relies on different lesion areas scattered around the entire image. Using the DiaretDB1 dataset, we show that on retina images different lesion areas fundamental for diabetic retinopathy are detected on an image level with high accuracy, comparable or exceeding supervised methods. On lesion level, we achieve few false positives with high sensitivity, though, the network is solely trained on image-level labels which do not include information about existing lesions. Classifying between diseased and healthy images, we achieve an AUC of 0.954 on the DiaretDB1.
Online Video Deblurring via Dynamic Temporal Blending Network
Apr 11, 2017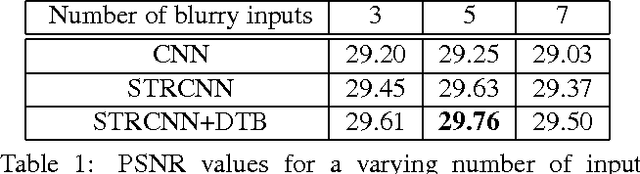
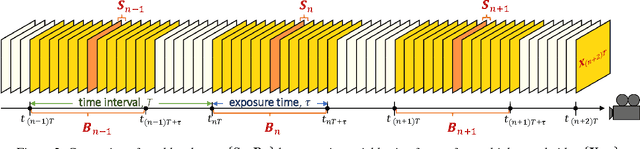
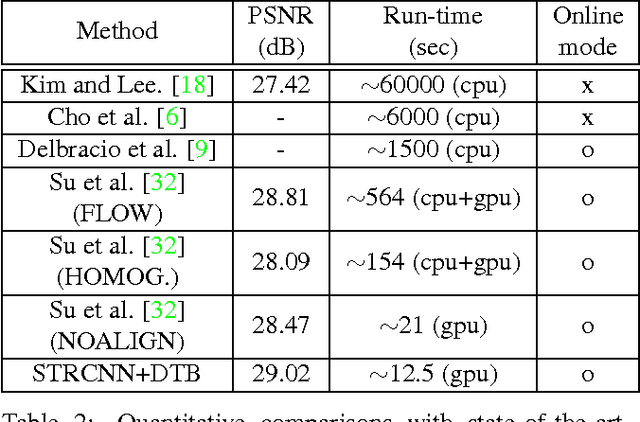
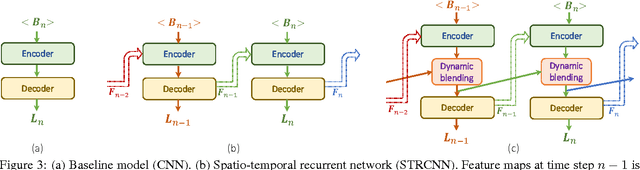
State-of-the-art video deblurring methods are capable of removing non-uniform blur caused by unwanted camera shake and/or object motion in dynamic scenes. However, most existing methods are based on batch processing and thus need access to all recorded frames, rendering them computationally demanding and time consuming and thus limiting their practical use. In contrast, we propose an online (sequential) video deblurring method based on a spatio-temporal recurrent network that allows for real-time performance. In particular, we introduce a novel architecture which extends the receptive field while keeping the overall size of the network small to enable fast execution. In doing so, our network is able to remove even large blur caused by strong camera shake and/or fast moving objects. Furthermore, we propose a novel network layer that enforces temporal consistency between consecutive frames by dynamic temporal blending which compares and adaptively (at test time) shares features obtained at different time steps. We show the superiority of the proposed method in an extensive experimental evaluation.
Discriminative Transfer Learning for General Image Restoration
Mar 27, 2017
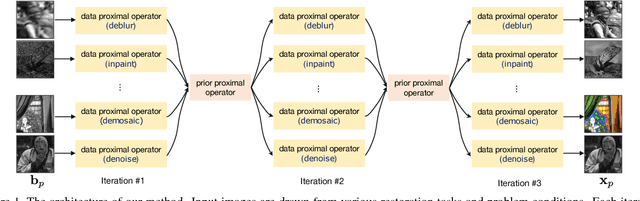

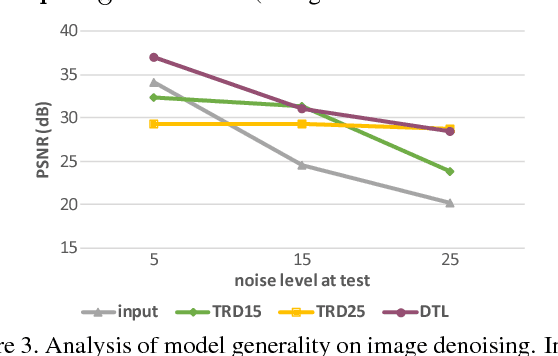
Recently, several discriminative learning approaches have been proposed for effective image restoration, achieving convincing trade-off between image quality and computational efficiency. However, these methods require separate training for each restoration task (e.g., denoising, deblurring, demosaicing) and problem condition (e.g., noise level of input images). This makes it time-consuming and difficult to encompass all tasks and conditions during training. In this paper, we propose a discriminative transfer learning method that incorporates formal proximal optimization and discriminative learning for general image restoration. The method requires a single-pass training and allows for reuse across various problems and conditions while achieving an efficiency comparable to previous discriminative approaches. Furthermore, after being trained, our model can be easily transferred to new likelihood terms to solve untrained tasks, or be combined with existing priors to further improve image restoration quality.
End-to-End Learning for Image Burst Deblurring
Sep 06, 2016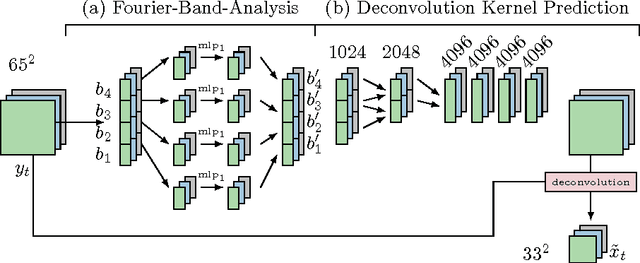
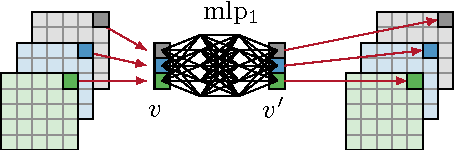

We present a neural network model approach for multi-frame blind deconvolution. The discriminative approach adopts and combines two recent techniques for image deblurring into a single neural network architecture. Our proposed hybrid-architecture combines the explicit prediction of a deconvolution filter and non-trivial averaging of Fourier coefficients in the frequency domain. In order to make full use of the information contained in all images in one burst, the proposed network embeds smaller networks, which explicitly allow the model to transfer information between images in early layers. Our system is trained end-to-end using standard backpropagation on a set of artificially generated training examples, enabling competitive performance in multi-frame blind deconvolution, both with respect to quality and runtime.
Depth Estimation Through a Generative Model of Light Field Synthesis
Sep 06, 2016



Light field photography captures rich structural information that may facilitate a number of traditional image processing and computer vision tasks. A crucial ingredient in such endeavors is accurate depth recovery. We present a novel framework that allows the recovery of a high quality continuous depth map from light field data. To this end we propose a generative model of a light field that is fully parametrized by its corresponding depth map. The model allows for the integration of powerful regularization techniques such as a non-local means prior, facilitating accurate depth map estimation.