 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGGNN: Graph-based GPU Nearest Neighbor Search
Dec 04, 2019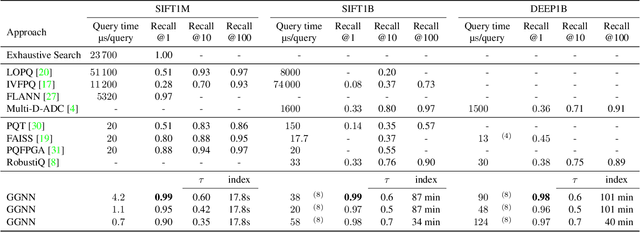
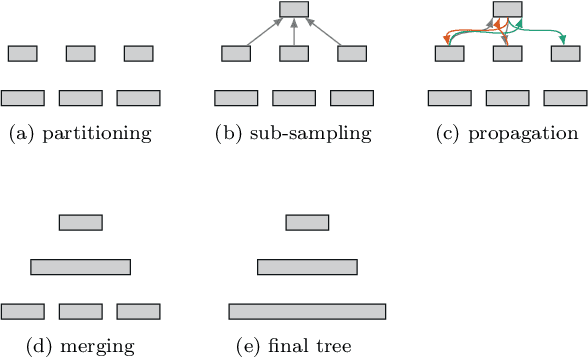

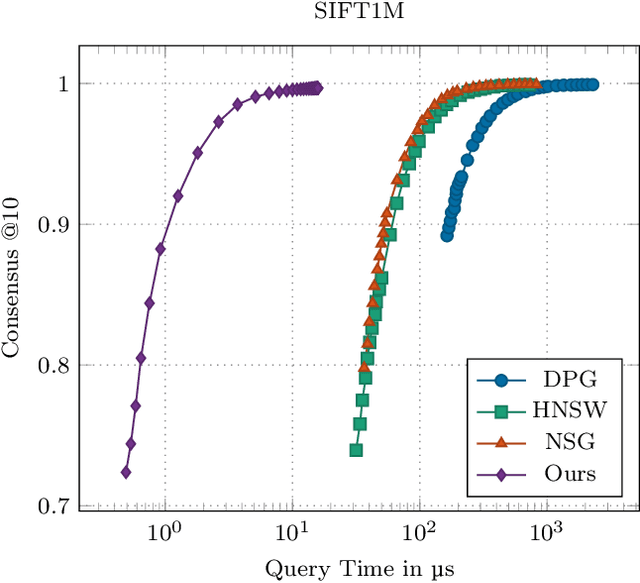
Approximate nearest neighbor (ANN) search in high dimensions is an integral part of several computer vision systems and gains importance in deep learning with explicit memory representations. Since PQT and FAISS started to leverage the massive parallelism offered by GPUs, GPU-based implementations are a crucial resource for today's state-of-the-art ANN methods. While most of these methods allow for faster queries, less emphasis is devoted to accelerate the construction of the underlying index structures. In this paper, we propose a novel search structure based on nearest neighbor graphs and information propagation on graphs. Our method is designed to take advantage of GPU architectures to accelerate the hierarchical building of the index structure and for performing the query. Empirical evaluation shows that GGNN significantly surpasses the state-of-the-art GPU- and CPU-based systems in terms of build-time, accuracy and search speed.
Flex-Convolution (Million-Scale Point-Cloud Learning Beyond Grid-Worlds)
Oct 25, 2018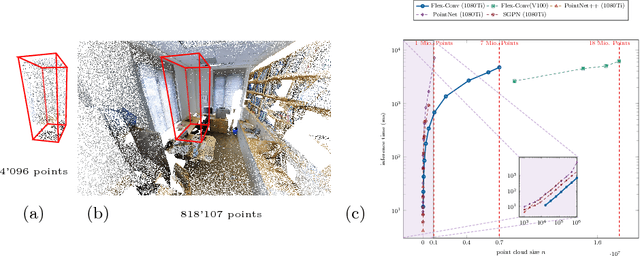
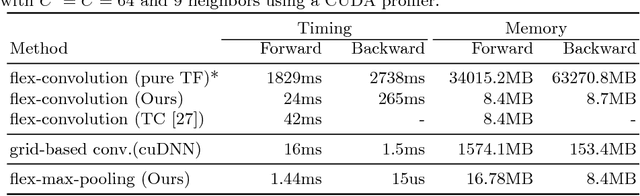


Traditional convolution layers are specifically designed to exploit the natural data representation of images -- a fixed and regular grid. However, unstructured data like 3D point clouds containing irregular neighborhoods constantly breaks the grid-based data assumption. Therefore applying best-practices and design choices from 2D-image learning methods towards processing point clouds are not readily possible. In this work, we introduce a natural generalization flex-convolution of the conventional convolution layer along with an efficient GPU implementation. We demonstrate competitive performance on rather small benchmark sets using fewer parameters and lower memory consumption and obtain significant improvements on a million-scale real-world dataset. Ours is the first which allows to efficiently process 7 million points concurrently.
Separating Reflection and Transmission Images in the Wild
Aug 16, 2018



The reflections caused by common semi-reflectors, such as glass windows, can impact the performance of computer vision algorithms. State-of-the-art methods can remove reflections on synthetic data and in controlled scenarios. However, they are based on strong assumptions and do not generalize well to real-world images. Contrary to a common misconception, real-world images are challenging even when polarization information is used. We present a deep learning approach to separate the reflected and the transmitted components of the recorded irradiance, which explicitly uses the polarization properties of light. To train it, we introduce an accurate synthetic data generation pipeline, which simulates realistic reflections, including those generated by curved and non-ideal surfaces, non-static scenes, and high-dynamic-range scenes.
Will People Like Your Image? Learning the Aesthetic Space
Dec 04, 2017



Rating how aesthetically pleasing an image appears is a highly complex matter and depends on a large number of different visual factors. Previous work has tackled the aesthetic rating problem by ranking on a 1-dimensional rating scale, e.g., incorporating handcrafted attributes. In this paper, we propose a rather general approach to automatically map aesthetic pleasingness with all its complexity into an "aesthetic space" to allow for a highly fine-grained resolution. In detail, making use of deep learning, our method directly learns an encoding of a given image into this high-dimensional feature space resembling visual aesthetics. Additionally to the mentioned visual factors, differences in personal judgments have a large impact on the likeableness of a photograph. Nowadays, online platforms allow users to "like" or favor certain content with a single click. To incorporate a huge diversity of people, we make use of such multi-user agreements and assemble a large data set of 380K images (AROD) with associated meta information and derive a score to rate how visually pleasing a given photo is. We validate our derived model of aesthetics in a user study. Further, without any extra data labeling or handcrafted features, we achieve state-of-the art accuracy on the AVA benchmark data set. Finally, as our approach is able to predict the aesthetic quality of any arbitrary image or video, we demonstrate our results on applications for resorting photo collections, capturing the best shot on mobile devices and aesthetic key-frame extraction from videos.
Learning Robust Video Synchronization without Annotations
Sep 16, 2017



Aligning video sequences is a fundamental yet still unsolved component for a broad range of applications in computer graphics and vision. Most classical image processing methods cannot be directly applied to related video problems due to the high amount of underlying data and their limit to small changes in appearance. We present a scalable and robust method for computing a non-linear temporal video alignment. The approach autonomously manages its training data for learning a meaningful representation in an iterative procedure each time increasing its own knowledge. It leverages on the nature of the videos themselves to remove the need for manually created labels. While previous alignment methods similarly consider weather conditions, season and illumination, our approach is able to align videos from data recorded months apart.
Learning Blind Motion Deblurring
Aug 14, 2017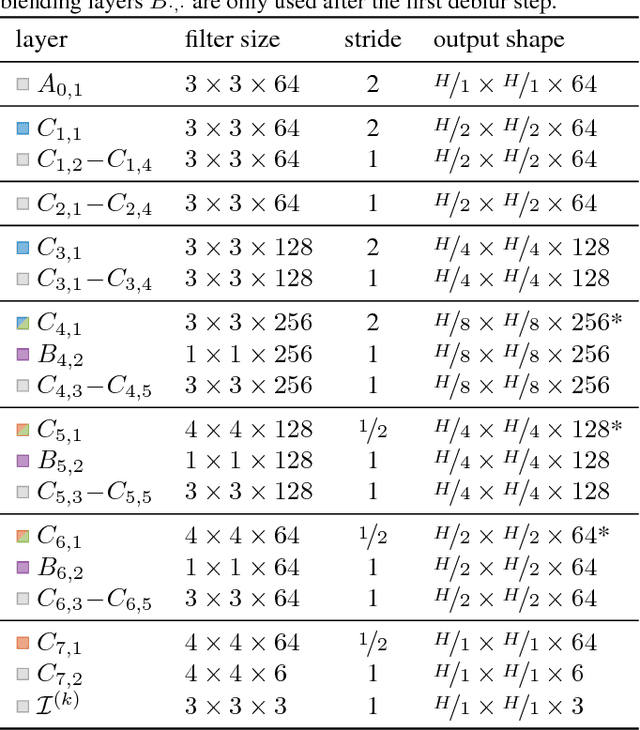

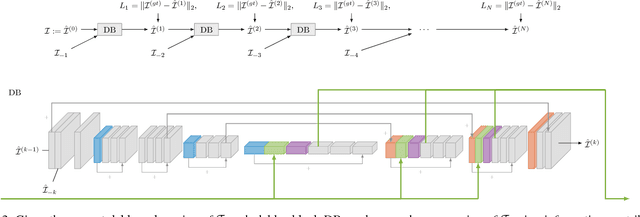

As handheld video cameras are now commonplace and available in every smartphone, images and videos can be recorded almost everywhere at anytime. However, taking a quick shot frequently yields a blurry result due to unwanted camera shake during recording or moving objects in the scene. Removing these artifacts from the blurry recordings is a highly ill-posed problem as neither the sharp image nor the motion blur kernel is known. Propagating information between multiple consecutive blurry observations can help restore the desired sharp image or video. Solutions for blind deconvolution based on neural networks rely on a massive amount of ground-truth data which is hard to acquire. In this work, we propose an efficient approach to produce a significant amount of realistic training data and introduce a novel recurrent network architecture to deblur frames taking temporal information into account, which can efficiently handle arbitrary spatial and temporal input sizes. We demonstrate the versatility of our approach in a comprehensive comparison on a number of challening real-world examples.
Efficient Large-scale Approximate Nearest Neighbor Search on the GPU
Feb 20, 2017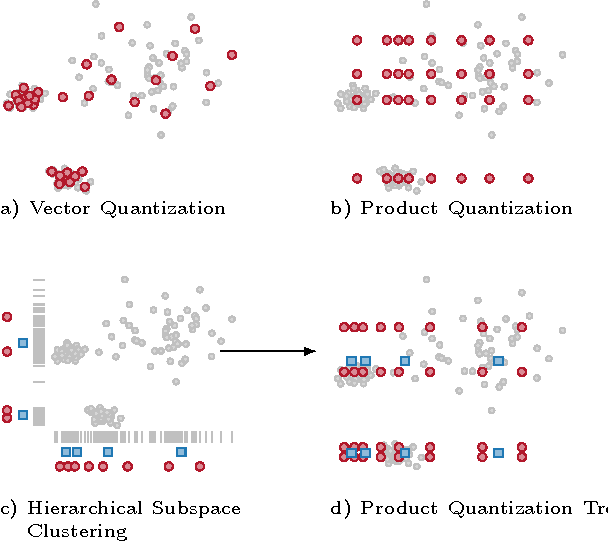
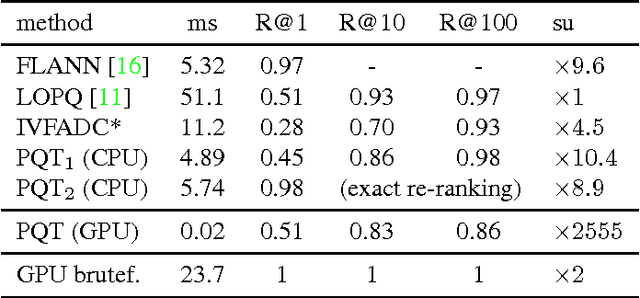


We present a new approach for efficient approximate nearest neighbor (ANN) search in high dimensional spaces, extending the idea of Product Quantization. We propose a two-level product and vector quantization tree that reduces the number of vector comparisons required during tree traversal. Our approach also includes a novel highly parallelizable re-ranking method for candidate vectors by efficiently reusing already computed intermediate values. Due to its small memory footprint during traversal, the method lends itself to an efficient, parallel GPU implementation. This Product Quantization Tree (PQT) approach significantly outperforms recent state of the art methods for high dimensional nearest neighbor queries on standard reference datasets. Ours is the first work that demonstrates GPU performance superior to CPU performance on high dimensional, large scale ANN problems in time-critical real-world applications, like loop-closing in videos.
Backpropagation Training for Fisher Vectors within Neural Networks
Feb 08, 2017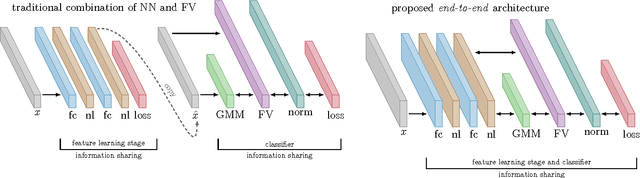
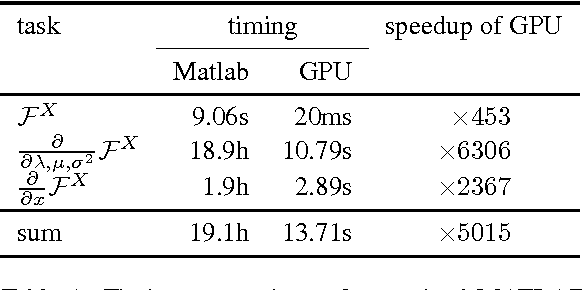
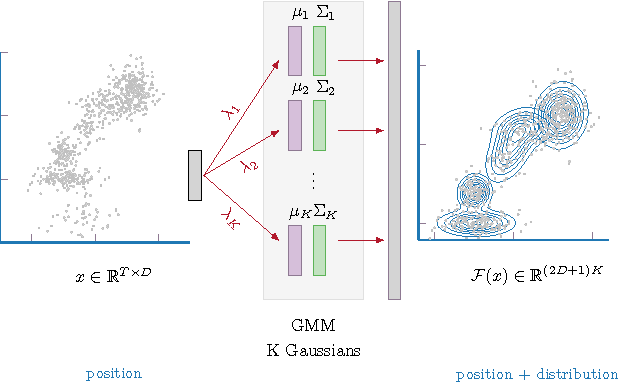
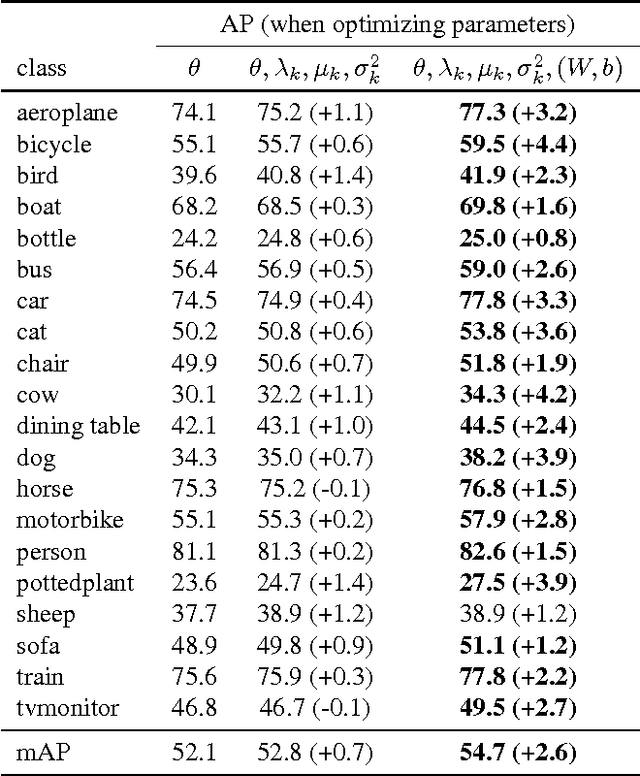
Fisher-Vectors (FV) encode higher-order statistics of a set of multiple local descriptors like SIFT features. They already show good performance in combination with shallow learning architectures on visual recognitions tasks. Current methods using FV as a feature descriptor in deep architectures assume that all original input features are static. We propose a framework to jointly learn the representation of original features, FV parameters and parameters of the classifier in the style of traditional neural networks. Our proof of concept implementation improves the performance of FV on the Pascal Voc 2007 challenge in a multi-GPU setting in comparison to a default SVM setting. We demonstrate that FV can be embedded into neural networks at arbitrary positions, allowing end-to-end training with back-propagation.
Transfer Learning for Material Classification using Convolutional Networks
Sep 20, 2016



Material classification in natural settings is a challenge due to complex interplay of geometry, reflectance properties, and illumination. Previous work on material classification relies strongly on hand-engineered features of visual samples. In this work we use a Convolutional Neural Network (convnet) that learns descriptive features for the specific task of material recognition. Specifically, transfer learning from the task of object recognition is exploited to more effectively train good features for material classification. The approach of transfer learning using convnets yields significantly higher recognition rates when compared to previous state-of-the-art approaches. We then analyze the relative contribution of reflectance and shading information by a decomposition of the image into its intrinsic components. The use of convnets for material classification was hindered by the strong demand for sufficient and diverse training data, even with transfer learning approaches. Therefore, we present a new data set containing approximately 10k images divided into 10 material categories.
End-to-End Learning for Image Burst Deblurring
Sep 06, 2016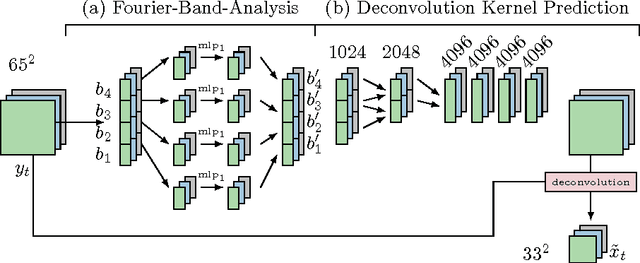
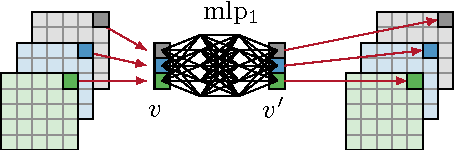

We present a neural network model approach for multi-frame blind deconvolution. The discriminative approach adopts and combines two recent techniques for image deblurring into a single neural network architecture. Our proposed hybrid-architecture combines the explicit prediction of a deconvolution filter and non-trivial averaging of Fourier coefficients in the frequency domain. In order to make full use of the information contained in all images in one burst, the proposed network embeds smaller networks, which explicitly allow the model to transfer information between images in early layers. Our system is trained end-to-end using standard backpropagation on a set of artificially generated training examples, enabling competitive performance in multi-frame blind deconvolution, both with respect to quality and runtime.