 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGGNN: Graph-based GPU Nearest Neighbor Search
Dec 04, 2019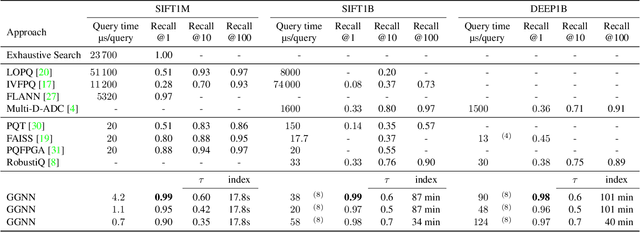
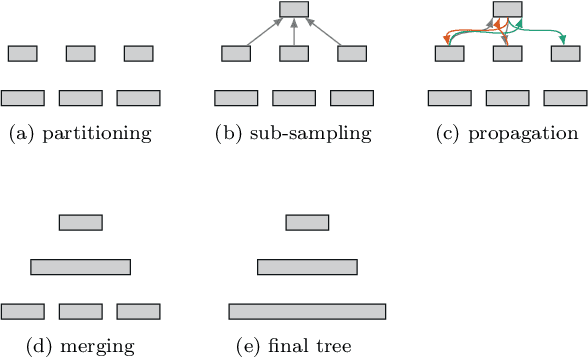

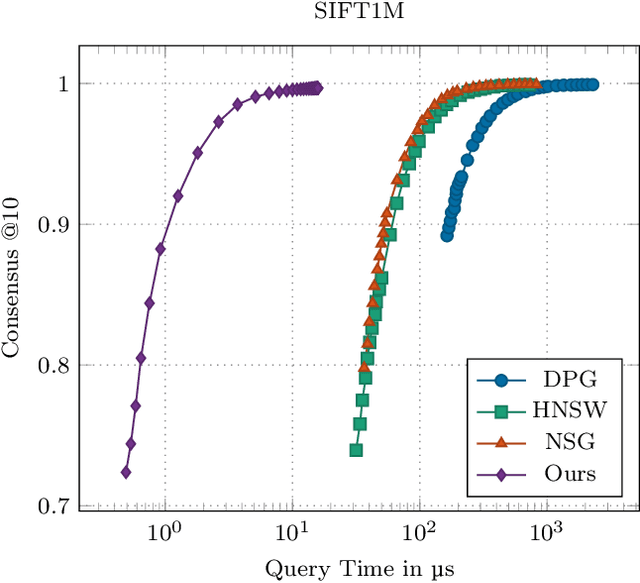
Approximate nearest neighbor (ANN) search in high dimensions is an integral part of several computer vision systems and gains importance in deep learning with explicit memory representations. Since PQT and FAISS started to leverage the massive parallelism offered by GPUs, GPU-based implementations are a crucial resource for today's state-of-the-art ANN methods. While most of these methods allow for faster queries, less emphasis is devoted to accelerate the construction of the underlying index structures. In this paper, we propose a novel search structure based on nearest neighbor graphs and information propagation on graphs. Our method is designed to take advantage of GPU architectures to accelerate the hierarchical building of the index structure and for performing the query. Empirical evaluation shows that GGNN significantly surpasses the state-of-the-art GPU- and CPU-based systems in terms of build-time, accuracy and search speed.
Flex-Convolution (Million-Scale Point-Cloud Learning Beyond Grid-Worlds)
Oct 25, 2018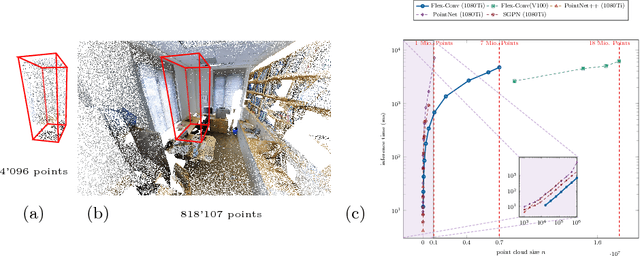
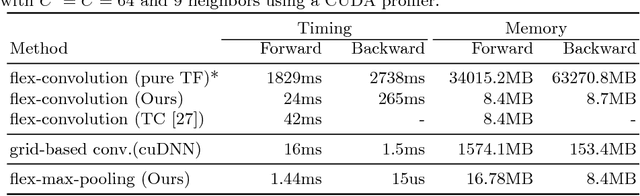


Traditional convolution layers are specifically designed to exploit the natural data representation of images -- a fixed and regular grid. However, unstructured data like 3D point clouds containing irregular neighborhoods constantly breaks the grid-based data assumption. Therefore applying best-practices and design choices from 2D-image learning methods towards processing point clouds are not readily possible. In this work, we introduce a natural generalization flex-convolution of the conventional convolution layer along with an efficient GPU implementation. We demonstrate competitive performance on rather small benchmark sets using fewer parameters and lower memory consumption and obtain significant improvements on a million-scale real-world dataset. Ours is the first which allows to efficiently process 7 million points concurrently.
Backpropagation Training for Fisher Vectors within Neural Networks
Feb 08, 2017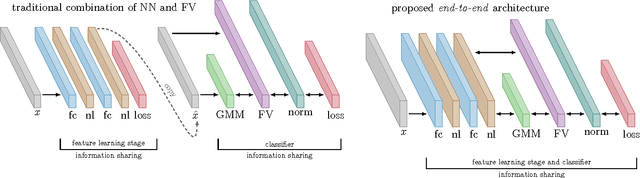
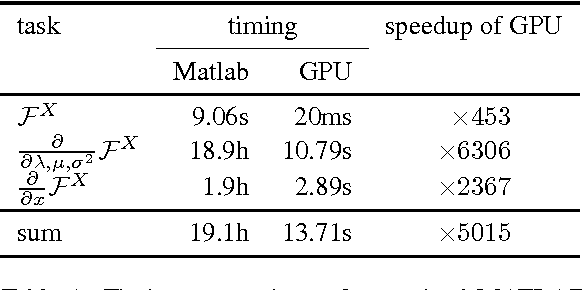
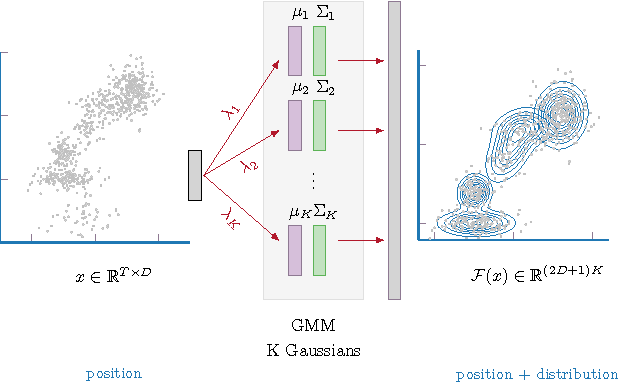
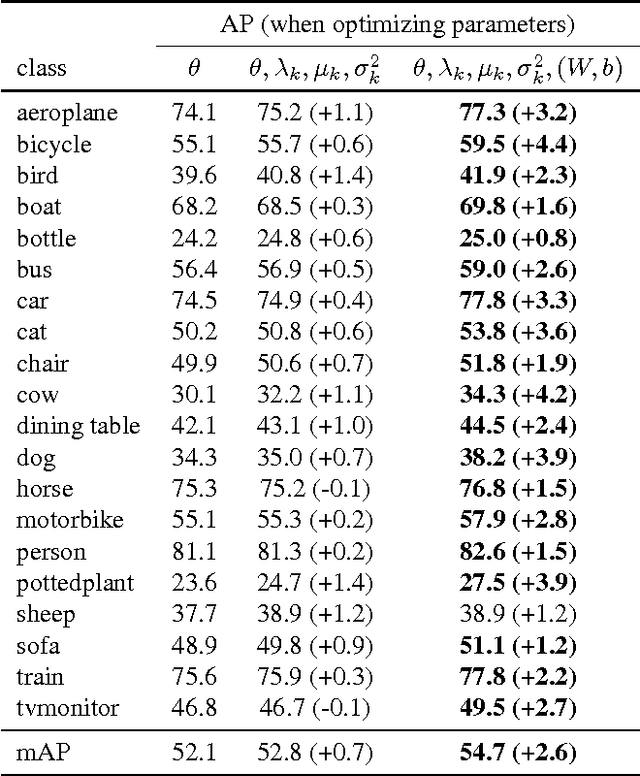
Fisher-Vectors (FV) encode higher-order statistics of a set of multiple local descriptors like SIFT features. They already show good performance in combination with shallow learning architectures on visual recognitions tasks. Current methods using FV as a feature descriptor in deep architectures assume that all original input features are static. We propose a framework to jointly learn the representation of original features, FV parameters and parameters of the classifier in the style of traditional neural networks. Our proof of concept implementation improves the performance of FV on the Pascal Voc 2007 challenge in a multi-GPU setting in comparison to a default SVM setting. We demonstrate that FV can be embedded into neural networks at arbitrary positions, allowing end-to-end training with back-propagation.