 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproved Single Camera BEV Perception Using Multi-Camera Training
Sep 04, 2024



Bird's Eye View (BEV) map prediction is essential for downstream autonomous driving tasks like trajectory prediction. In the past, this was accomplished through the use of a sophisticated sensor configuration that captured a surround view from multiple cameras. However, in large-scale production, cost efficiency is an optimization goal, so that using fewer cameras becomes more relevant. But the consequence of fewer input images correlates with a performance drop. This raises the problem of developing a BEV perception model that provides a sufficient performance on a low-cost sensor setup. Although, primarily relevant for inference time on production cars, this cost restriction is less problematic on a test vehicle during training. Therefore, the objective of our approach is to reduce the aforementioned performance drop as much as possible using a modern multi-camera surround view model reduced for single-camera inference. The approach includes three features, a modern masking technique, a cyclic Learning Rate (LR) schedule, and a feature reconstruction loss for supervising the transition from six-camera inputs to one-camera input during training. Our method outperforms versions trained strictly with one camera or strictly with six-camera surround view for single-camera inference resulting in reduced hallucination and better quality of the BEV map.
Task Weighting through Gradient Projection for Multitask Learning
Sep 03, 2024In multitask learning, conflicts between task gradients are a frequent issue degrading a model's training performance. This is commonly addressed by using the Gradient Projection algorithm PCGrad that often leads to faster convergence and improved performance metrics. In this work, we present a method to adapt this algorithm to simultaneously also perform task prioritization. Our approach differs from traditional task weighting performed by scaling task losses in that our weighting scheme applies only in cases where tasks are in conflict, but lets the training proceed unhindered otherwise. We replace task weighting factors by a probability distribution that determines which task gradients get projected in conflict cases. Our experiments on the nuScenes, CIFAR-100, and CelebA datasets confirm that our approach is a practical method for task weighting. Paired with multiple different task weighting schemes, we observe a significant improvement in the performance metrics of most tasks compared to Gradient Projection with uniform projection probabilities.
On the Potential of Open-Vocabulary Models for Object Detection in Unusual Street Scenes
Aug 20, 2024



Out-of-distribution (OOD) object detection is a critical task focused on detecting objects that originate from a data distribution different from that of the training data. In this study, we investigate to what extent state-of-the-art open-vocabulary object detectors can detect unusual objects in street scenes, which are considered as OOD or rare scenarios with respect to common street scene datasets. Specifically, we evaluate their performance on the OoDIS Benchmark, which extends RoadAnomaly21 and RoadObstacle21 from SegmentMeIfYouCan, as well as LostAndFound, which was recently extended to object level annotations. The objective of our study is to uncover short-comings of contemporary object detectors in challenging real-world, and particularly in open-world scenarios. Our experiments reveal that open vocabulary models are promising for OOD object detection scenarios, however far from perfect. Substantial improvements are required before they can be reliably deployed in real-world applications. We benchmark four state-of-the-art open-vocabulary object detection models on three different datasets. Noteworthily, Grounding DINO achieves the best results on RoadObstacle21 and LostAndFound in our study with an AP of 48.3% and 25.4% respectively. YOLO-World excels on RoadAnomaly21 with an AP of 21.2%.
Polynomial Trajectory Predictions for Improved Learning Performance
Jan 29, 2021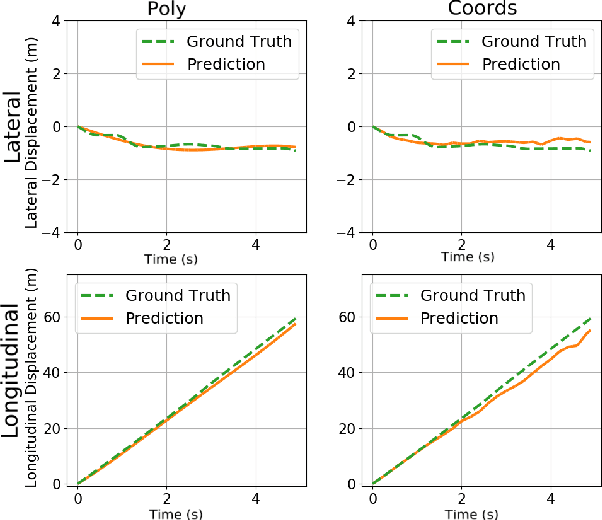
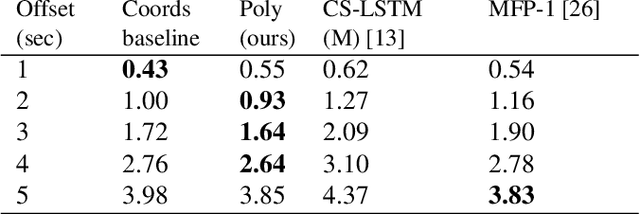
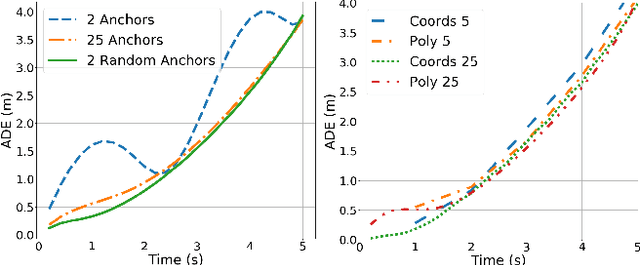
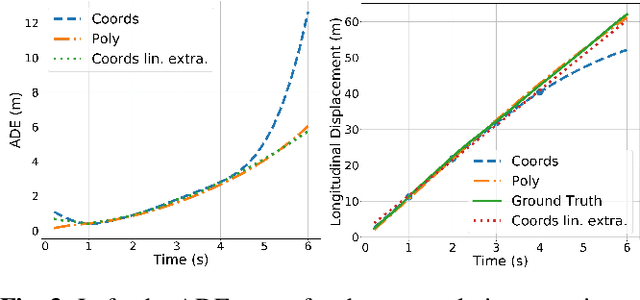
The rising demand for Active Safety systems in automotive applications stresses the need for a reliable short to mid-term trajectory prediction. Anticipating the unfolding path of road users, one can act to increase the overall safety. In this work, we propose to train artificial neural networks for movement understanding by predicting trajectories in their natural form, as a function of time. Predicting polynomial coefficients allows us to increased accuracy and improve generalisation.
A Statistical Defense Approach for Detecting Adversarial Examples
Aug 26, 2019



Adversarial examples are maliciously modified inputs created to fool deep neural networks (DNN). The discovery of such inputs presents a major issue to the expansion of DNN-based solutions. Many researchers have already contributed to the topic, providing both cutting edge-attack techniques and various defensive strategies. In this work, we focus on the development of a system capable of detecting adversarial samples by exploiting statistical information from the training-set. Our detector computes several distorted replicas of the test input, then collects the classifier's prediction vectors to build a meaningful signature for the detection task. Then, the signature is projected onto the class-specific statistic vector to infer the input's nature. The classification output of the original input is used to select the class-statistic vector. We show that our method reliably detects malicious inputs, outperforming state-of-the-art approaches in various settings, while being complementary to other defensive solutions.
EffNet: An Efficient Structure for Convolutional Neural Networks
Jun 05, 2018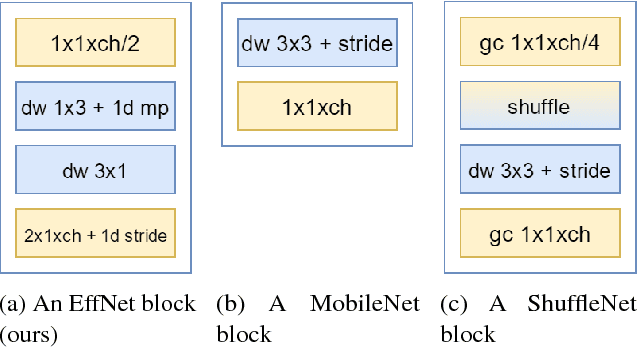
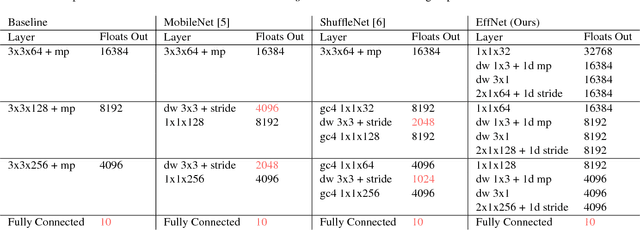
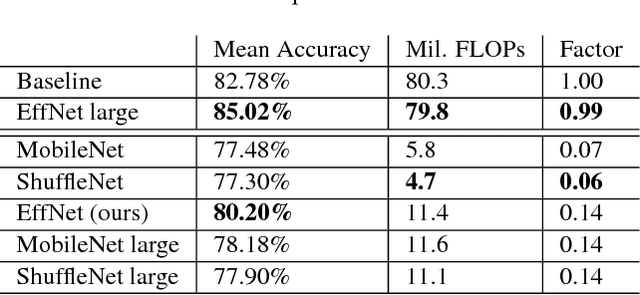
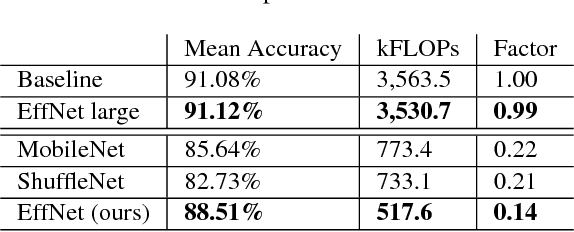
With the ever increasing application of Convolutional Neural Networks to customer products the need emerges for models to efficiently run on embedded, mobile hardware. Slimmer models have therefore become a hot research topic with various approaches which vary from binary networks to revised convolution layers. We offer our contribution to the latter and propose a novel convolution block which significantly reduces the computational burden while surpassing the current state-of-the-art. Our model, dubbed EffNet, is optimised for models which are slim to begin with and is created to tackle issues in existing models such as MobileNet and ShuffleNet.
Learning Robust Video Synchronization without Annotations
Sep 16, 2017



Aligning video sequences is a fundamental yet still unsolved component for a broad range of applications in computer graphics and vision. Most classical image processing methods cannot be directly applied to related video problems due to the high amount of underlying data and their limit to small changes in appearance. We present a scalable and robust method for computing a non-linear temporal video alignment. The approach autonomously manages its training data for learning a meaningful representation in an iterative procedure each time increasing its own knowledge. It leverages on the nature of the videos themselves to remove the need for manually created labels. While previous alignment methods similarly consider weather conditions, season and illumination, our approach is able to align videos from data recorded months apart.