 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraph Query Networks for Object Detection with Automotive Radar
Nov 19, 2025

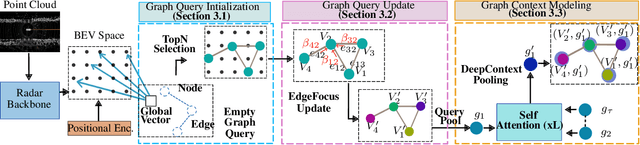

Object detection with 3D radar is essential for 360-degree automotive perception, but radar's long wavelengths produce sparse and irregular reflections that challenge traditional grid and sequence-based convolutional and transformer detectors. This paper introduces Graph Query Networks (GQN), an attention-based framework that models objects sensed by radar as graphs, to extract individualized relational and contextual features. GQN employs a novel concept of graph queries to dynamically attend over the bird's-eye view (BEV) space, constructing object-specific graphs processed by two novel modules: EdgeFocus for relational reasoning and DeepContext Pooling for contextual aggregation. On the NuScenes dataset, GQN improves relative mAP by up to +53%, including a +8.2% gain over the strongest prior radar method, while reducing peak graph construction overhead by 80% with moderate FLOPs cost.
Multi-Agent Multimodal Large Language Model Framework for Automated Interpretation of Fuel Efficiency Analytics in Public Transportation
Nov 17, 2025Enhancing fuel efficiency in public transportation requires the integration of complex multimodal data into interpretable, decision-relevant insights. However, traditional analytics and visualization methods often yield fragmented outputs that demand extensive human interpretation, limiting scalability and consistency. This study presents a multi-agent framework that leverages multimodal large language models (LLMs) to automate data narration and energy insight generation. The framework coordinates three specialized agents, including a data narration agent, an LLM-as-a-judge agent, and an optional human-in-the-loop evaluator, to iteratively transform analytical artifacts into coherent, stakeholder-oriented reports. The system is validated through a real-world case study on public bus transportation in Northern Jutland, Denmark, where fuel efficiency data from 4006 trips are analyzed using Gaussian Mixture Model clustering. Comparative experiments across five state-of-the-art LLMs and three prompting paradigms identify GPT-4.1 mini with Chain-of-Thought prompting as the optimal configuration, achieving 97.3% narrative accuracy while balancing interpretability and computational cost. The findings demonstrate that multi-agent orchestration significantly enhances factual precision, coherence, and scalability in LLM-based reporting. The proposed framework establishes a replicable and domain-adaptive methodology for AI-driven narrative generation and decision support in energy informatics.
Rethinking Backbone Design for Lightweight 3D Object Detection in LiDAR
Aug 01, 2025Recent advancements in LiDAR-based 3D object detection have significantly accelerated progress toward the realization of fully autonomous driving in real-world environments. Despite achieving high detection performance, most of the approaches still rely on a VGG-based or ResNet-based backbone for feature exploration, which increases the model complexity. Lightweight backbone design is well-explored for 2D object detection, but research on 3D object detection still remains limited. In this work, we introduce Dense Backbone, a lightweight backbone that combines the benefits of high processing speed, lightweight architecture, and robust detection accuracy. We adapt multiple SoTA 3d object detectors, such as PillarNet, with our backbone and show that with our backbone, these models retain most of their detection capability at a significantly reduced computational cost. To our knowledge, this is the first dense-layer-based backbone tailored specifically for 3D object detection from point cloud data. DensePillarNet, our adaptation of PillarNet, achieves a 29% reduction in model parameters and a 28% reduction in latency with just a 2% drop in detection accuracy on the nuScenes test set. Furthermore, Dense Backbone's plug-and-play design allows straightforward integration into existing architectures, requiring no modifications to other network components.
Inferring Driving Maps by Deep Learning-based Trail Map Extraction
May 15, 2025High-definition (HD) maps offer extensive and accurate environmental information about the driving scene, making them a crucial and essential element for planning within autonomous driving systems. To avoid extensive efforts from manual labeling, methods for automating the map creation have emerged. Recent trends have moved from offline mapping to online mapping, ensuring availability and actuality of the utilized maps. While the performance has increased in recent years, online mapping still faces challenges regarding temporal consistency, sensor occlusion, runtime, and generalization. We propose a novel offline mapping approach that integrates trails - informal routes used by drivers - into the map creation process. Our method aggregates trail data from the ego vehicle and other traffic participants to construct a comprehensive global map using transformer-based deep learning models. Unlike traditional offline mapping, our approach enables continuous updates while remaining sensor-agnostic, facilitating efficient data transfer. Our method demonstrates superior performance compared to state-of-the-art online mapping approaches, achieving improved generalization to previously unseen environments and sensor configurations. We validate our approach on two benchmark datasets, highlighting its robustness and applicability in autonomous driving systems.
LMFormer: Lane based Motion Prediction Transformer
Apr 14, 2025
Motion prediction plays an important role in autonomous driving. This study presents LMFormer, a lane-aware transformer network for trajectory prediction tasks. In contrast to previous studies, our work provides a simple mechanism to dynamically prioritize the lanes and shows that such a mechanism introduces explainability into the learning behavior of the network. Additionally, LMFormer uses the lane connection information at intersections, lane merges, and lane splits, in order to learn long-range dependency in lane structure. Moreover, we also address the issue of refining the predicted trajectories and propose an efficient method for iterative refinement through stacked transformer layers. For benchmarking, we evaluate LMFormer on the nuScenes dataset and demonstrate that it achieves SOTA performance across multiple metrics. Furthermore, the Deep Scenario dataset is used to not only illustrate cross-dataset network performance but also the unification capabilities of LMFormer to train on multiple datasets and achieve better performance.
AttentiveGRU: Recurrent Spatio-Temporal Modeling for Advanced Radar-Based BEV Object Detection
Apr 01, 2025Bird's-eye view (BEV) object detection has become important for advanced automotive 3D radar-based perception systems. However, the inherently sparse and non-deterministic nature of radar data limits the effectiveness of traditional single-frame BEV paradigms. In this paper, we addresses this limitation by introducing AttentiveGRU, a novel attention-based recurrent approach tailored for radar constraints, which extracts individualized spatio-temporal context for objects by dynamically identifying and fusing temporally correlated structures across present and memory states. By leveraging the consistency of object's latent representation over time, our approach exploits temporal relations to enrich feature representations for both stationary and moving objects, thereby enhancing detection performance and eliminating the need for externally providing or estimating any information about ego vehicle motion. Our experimental results on the public nuScenes dataset show a significant increase in mAP for the car category by 21% over the best radar-only submission. Further evaluations on an additional dataset demonstrate notable improvements in object detection capabilities, underscoring the applicability and effectiveness of our method.
CASPFormer: Trajectory Prediction from BEV Images with Deformable Attention
Sep 26, 2024



Motion prediction is an important aspect for Autonomous Driving (AD) and Advance Driver Assistance Systems (ADAS). Current state-of-the-art motion prediction methods rely on High Definition (HD) maps for capturing the surrounding context of the ego vehicle. Such systems lack scalability in real-world deployment as HD maps are expensive to produce and update in real-time. To overcome this issue, we propose Context Aware Scene Prediction Transformer (CASPFormer), which can perform multi-modal motion prediction from rasterized Bird-Eye-View (BEV) images. Our system can be integrated with any upstream perception module that is capable of generating BEV images. Moreover, CASPFormer directly decodes vectorized trajectories without any postprocessing. Trajectories are decoded recurrently using deformable attention, as it is computationally efficient and provides the network with the ability to focus its attention on the important spatial locations of the BEV images. In addition, we also address the issue of mode collapse for generating multiple scene-consistent trajectories by incorporating learnable mode queries. We evaluate our model on the nuScenes dataset and show that it reaches state-of-the-art across multiple metrics
Improved Single Camera BEV Perception Using Multi-Camera Training
Sep 04, 2024



Bird's Eye View (BEV) map prediction is essential for downstream autonomous driving tasks like trajectory prediction. In the past, this was accomplished through the use of a sophisticated sensor configuration that captured a surround view from multiple cameras. However, in large-scale production, cost efficiency is an optimization goal, so that using fewer cameras becomes more relevant. But the consequence of fewer input images correlates with a performance drop. This raises the problem of developing a BEV perception model that provides a sufficient performance on a low-cost sensor setup. Although, primarily relevant for inference time on production cars, this cost restriction is less problematic on a test vehicle during training. Therefore, the objective of our approach is to reduce the aforementioned performance drop as much as possible using a modern multi-camera surround view model reduced for single-camera inference. The approach includes three features, a modern masking technique, a cyclic Learning Rate (LR) schedule, and a feature reconstruction loss for supervising the transition from six-camera inputs to one-camera input during training. Our method outperforms versions trained strictly with one camera or strictly with six-camera surround view for single-camera inference resulting in reduced hallucination and better quality of the BEV map.
A Survey on Emergent Language
Sep 04, 2024



The field of emergent language represents a novel area of research within the domain of artificial intelligence, particularly within the context of multi-agent reinforcement learning. Although the concept of studying language emergence is not new, early approaches were primarily concerned with explaining human language formation, with little consideration given to its potential utility for artificial agents. In contrast, studies based on reinforcement learning aim to develop communicative capabilities in agents that are comparable to or even superior to human language. Thus, they extend beyond the learned statistical representations that are common in natural language processing research. This gives rise to a number of fundamental questions, from the prerequisites for language emergence to the criteria for measuring its success. This paper addresses these questions by providing a comprehensive review of 181 scientific publications on emergent language in artificial intelligence. Its objective is to serve as a reference for researchers interested in or proficient in the field. Consequently, the main contributions are the definition and overview of the prevailing terminology, the analysis of existing evaluation methods and metrics, and the description of the identified research gaps.
Decision Transformer for Enhancing Neural Local Search on the Job Shop Scheduling Problem
Sep 04, 2024



The job shop scheduling problem (JSSP) and its solution algorithms have been of enduring interest in both academia and industry for decades. In recent years, machine learning (ML) is playing an increasingly important role in advancing existing and building new heuristic solutions for the JSSP, aiming to find better solutions in shorter computation times. In this paper we build on top of a state-of-the-art deep reinforcement learning (DRL) agent, called Neural Local Search (NLS), which can efficiently and effectively control a large local neighborhood search on the JSSP. In particular, we develop a method for training the decision transformer (DT) algorithm on search trajectories taken by a trained NLS agent to further improve upon the learned decision-making sequences. Our experiments show that the DT successfully learns local search strategies that are different and, in many cases, more effective than those of the NLS agent itself. In terms of the tradeoff between solution quality and acceptable computational time needed for the search, the DT is particularly superior in application scenarios where longer computational times are acceptable. In this case, it makes up for the longer inference times required per search step, which are caused by the larger neural network architecture, through better quality decisions per step. Thereby, the DT achieves state-of-the-art results for solving the JSSP with ML-enhanced search.