 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttentiveGRU: Recurrent Spatio-Temporal Modeling for Advanced Radar-Based BEV Object Detection
Apr 01, 2025Bird's-eye view (BEV) object detection has become important for advanced automotive 3D radar-based perception systems. However, the inherently sparse and non-deterministic nature of radar data limits the effectiveness of traditional single-frame BEV paradigms. In this paper, we addresses this limitation by introducing AttentiveGRU, a novel attention-based recurrent approach tailored for radar constraints, which extracts individualized spatio-temporal context for objects by dynamically identifying and fusing temporally correlated structures across present and memory states. By leveraging the consistency of object's latent representation over time, our approach exploits temporal relations to enrich feature representations for both stationary and moving objects, thereby enhancing detection performance and eliminating the need for externally providing or estimating any information about ego vehicle motion. Our experimental results on the public nuScenes dataset show a significant increase in mAP for the car category by 21% over the best radar-only submission. Further evaluations on an additional dataset demonstrate notable improvements in object detection capabilities, underscoring the applicability and effectiveness of our method.
SparseRadNet: Sparse Perception Neural Network on Subsampled Radar Data
Jun 18, 2024



Radar-based perception has gained increasing attention in autonomous driving, yet the inherent sparsity of radars poses challenges. Radar raw data often contains excessive noise, whereas radar point clouds retain only limited information. In this work, we holistically treat the sparse nature of radar data by introducing an adaptive subsampling method together with a tailored network architecture that exploits the sparsity patterns to discover global and local dependencies in the radar signal. Our subsampling module selects a subset of pixels from range-doppler (RD) spectra that contribute most to the downstream perception tasks. To improve the feature extraction on sparse subsampled data, we propose a new way of applying graph neural networks on radar data and design a novel two-branch backbone to capture both global and local neighbor information. An attentive fusion module is applied to combine features from both branches. Experiments on the RADIal dataset show that our SparseRadNet exceeds state-of-the-art (SOTA) performance in object detection and achieves close to SOTA accuracy in freespace segmentation, meanwhile using sparse subsampled input data.
Deep Learning Method for Cell-Wise Object Tracking, Velocity Estimation and Projection of Sensor Data over Time
Jun 18, 2023Current Deep Learning methods for environment segmentation and velocity estimation rely on Convolutional Recurrent Neural Networks to exploit spatio-temporal relationships within obtained sensor data. These approaches derive scene dynamics implicitly by correlating novel input and memorized data utilizing ConvNets. We show how ConvNets suffer from architectural restrictions for this task. Based on these findings, we then provide solutions to various issues on exploiting spatio-temporal correlations in a sequence of sensor recordings by presenting a novel Recurrent Neural Network unit utilizing Transformer mechanisms. Within this unit, object encodings are tracked across consecutive frames by correlating key-query pairs derived from sensor inputs and memory states, respectively. We then use resulting tracking patterns to obtain scene dynamics and regress velocities. In a last step, the memory state of the Recurrent Neural Network is projected based on extracted velocity estimates to resolve aforementioned spatio-temporal misalignment.
Efficient fine-grained road segmentation using superpixel-based CNN and CRF models
Jun 22, 2022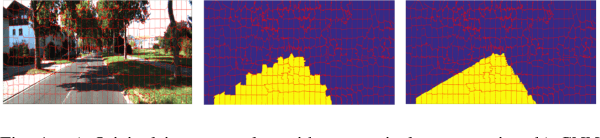
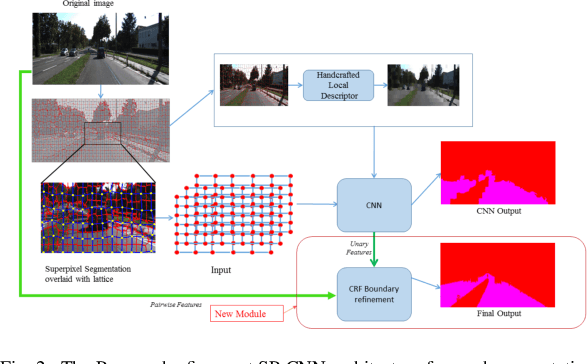

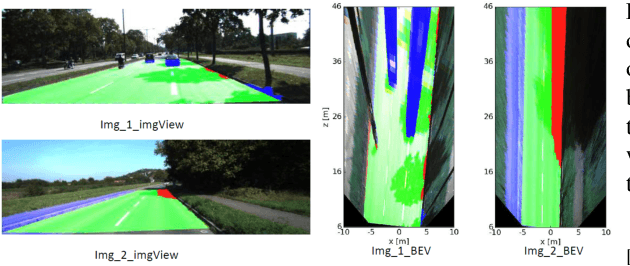
Towards a safe and comfortable driving, road scene segmentation is a rudimentary problem in camera-based advance driver assistance systems (ADAS). Despite of the great achievement of Convolutional Neural Networks (CNN) for semantic segmentation task, the high computational efforts of CNN based methods is still a challenging area. In recent work, we proposed a novel approach to utilise the advantages of CNNs for the task of road segmentation at reasonable computational effort. The runtime benefits from using irregular super pixels as basis for the input for the CNN rather than the image grid, which tremendously reduces the input size. Although, this method achieved remarkable low computational time in both training and testing phases, the lower resolution of the super pixel domain yields naturally lower accuracy compared to high cost state of the art methods. In this work, we focus on a refinement of the road segmentation utilising a Conditional Random Field (CRF).The refinement procedure is limited to the super pixels touching the predicted road boundary to keep the additional computational effort low. Reducing the input to the super pixel domain allows the CNNs structure to stay small and efficient to compute while keeping the advantage of convolutional layers and makes them eligible for ADAS. Applying CRF compensate the trade off between accuracy and computational efficiency. The proposed system obtained comparable performance among the top performing algorithms on the KITTI road benchmark and its fast inference makes it particularly suitable for realtime applications.