 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTARS: Traffic-Aware Radar Scene Flow Estimation
Mar 13, 2025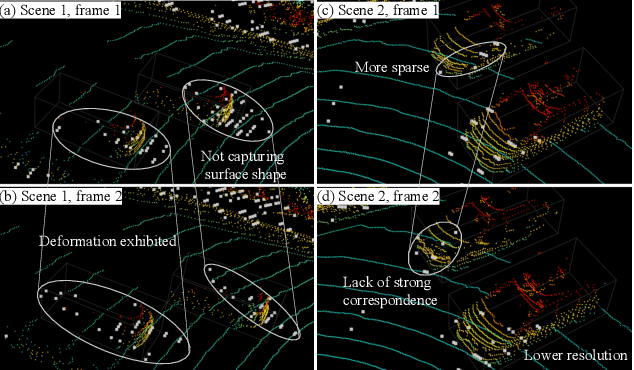

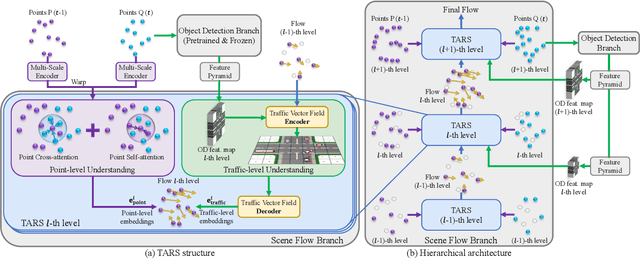
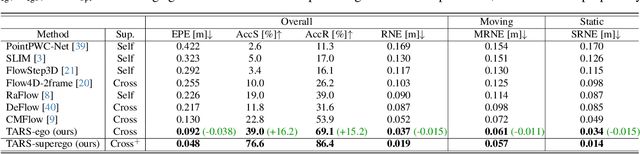
Scene flow provides crucial motion information for autonomous driving. Recent LiDAR scene flow models utilize the rigid-motion assumption at the instance level, assuming objects are rigid bodies. However, these instance-level methods are not suitable for sparse radar point clouds. In this work, we present a novel $\textbf{T}$raffic-$\textbf{A}$ware $\textbf{R}$adar $\textbf{S}$cene flow estimation method, named $\textbf{TARS}$, which utilizes the motion rigidity at the traffic level. To address the challenges in radar scene flow, we perform object detection and scene flow jointly and boost the latter. We incorporate the feature map from the object detector, trained with detection losses, to make radar scene flow aware of the environment and road users. Therefrom, we construct a Traffic Vector Field (TVF) in the feature space, enabling a holistic traffic-level scene understanding in our scene flow branch. When estimating the scene flow, we consider both point-level motion cues from point neighbors and traffic-level consistency of rigid motion within the space. TARS outperforms the state of the art on a proprietary dataset and the View-of-Delft dataset, improving the benchmarks by 23% and 15%, respectively.
Deep Learning Method for Cell-Wise Object Tracking, Velocity Estimation and Projection of Sensor Data over Time
Jun 18, 2023Current Deep Learning methods for environment segmentation and velocity estimation rely on Convolutional Recurrent Neural Networks to exploit spatio-temporal relationships within obtained sensor data. These approaches derive scene dynamics implicitly by correlating novel input and memorized data utilizing ConvNets. We show how ConvNets suffer from architectural restrictions for this task. Based on these findings, we then provide solutions to various issues on exploiting spatio-temporal correlations in a sequence of sensor recordings by presenting a novel Recurrent Neural Network unit utilizing Transformer mechanisms. Within this unit, object encodings are tracked across consecutive frames by correlating key-query pairs derived from sensor inputs and memory states, respectively. We then use resulting tracking patterns to obtain scene dynamics and regress velocities. In a last step, the memory state of the Recurrent Neural Network is projected based on extracted velocity estimates to resolve aforementioned spatio-temporal misalignment.